爬虫实战进阶:工商网站验证码绕过技巧与逆向分析全攻略
工商网站承载海量企业信用数据,成为爬虫采集重点目标,但验证码机制严苛多样。本文详解分页前后端判断、多套验证码切换、WAP移动端与备用站点利用、企业ID猜解规律,以及云南工商滑动验证码的完整JS逆向过程,提供原理讲解、抓包分析和简单实现思路。同时指出复杂场景下可借助专业平台轻松处理各类极验易盾验证码,实现高效无缝对接。
一、工商网站数据采集的验证码挑战
在爬取企业信用信息时,国家企业信用信息公示系统等各地工商网站无疑是黄金宝库。这里汇集了公司注册详情、股东结构、经营范围、行政处罚记录等关键数据,对金融贷款、征信查询、商业尽调等业务来说价值连城。正因为如此,大量爬虫程序瞄准这些公开资源发起请求,导致网站方不得不祭出严格的反爬措施。
普通网站往往只在登录、注册或高频访问时弹出验证码,但工商网站不同:无需登录,每次输入关键字查询企业信息都要经过一次验证码校验。而且各地工商系统独立开发,验证码类型五花八门,有的用九宫格点击,有的用滑动拖拽,还有文字点选、图标识别、躲避障碍甚至五子棋对弈等复杂形式。这给全量数据采集带来了层层障碍,却也让整个过程充满技术乐趣。
作为爬虫工程师,我们的核心目标是高效获取数据,同时尽量减少被封禁的风险。接下来我们从最基础的分页处理开始,一步步拆解这些验证码的破绽,分享接地气的分析思路和简单实现手法,让即使是新手也能快速上手。
二、从分页机制入手判断并绕过验证码

分页是爬虫采集列表数据的必经之路。网站可能把分页逻辑放在前端或后端,这直接决定了验证码是否能被轻松绕过。判断方法超级简单:打开浏览器,按F12唤起开发者工具,然后点击下一页。如果看到新的网络请求发出,就说明分页在后端;如果页面直接通过JS切换内容,那就是前端处理。
以四川和上海的工商网站为例,实际测试发现它们的翻页请求都落在后端。更关键的是,翻页操作并没有弹出验证码输入框。这意味着这里的验证码在某些场景下可以被跳过,但原理略有不同。

对比四川网站翻页前后的请求参数,除了正常的页码字段外,多了一个名为“yzmYesOrNo”的参数,值为“no”。从变量名就能猜到,后端正是根据这个标志位来决定是否跳过验证码校验。我们在构造请求时,只需显式带上这个参数,就能顺利拿到下一页数据。
上海的情况更有意思:翻页请求中直接少了验证码相关字段。这暗示验证码校验可能只在前台做了简单拦截,后端并未二次验证。因此,我们可以大胆省略验证码字段,直接向后端发起请求,数据照样能正常返回。当然,这种情况严格来说属于开发小疏漏,爬虫工程师要保持低调使用,别一次爬太多导致IP被封。笔者曾经没加限流,一口气爬了十万条记录,结果IP直接进小黑屋,好几天后才解封,网站还顺便修复了这个漏洞。
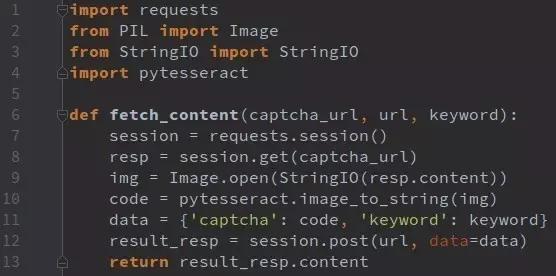
实际操作时,我们可以用Python的requests库模拟请求,带上必要的cookie和headers,伪装成正常浏览器行为。代码思路大致如下:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Referer': 'https://example.gsxt.gov.cn/'
}
data = {'page': 2, 'yzmYesOrNo': 'no'}
response = requests.post('https://sc.gsxt.gov.cn/search', data=data, headers=headers)
print(response.json())
通过这种方式,新手也能快速验证分页是否可绕过,节省大量时间。

三、巧妙利用多套验证码机制实现移花接木
有些工商网站为了安全,在不同页面部署了不同难度的验证码。这时候我们就要学会“捡软柿子捏”:优先识别简单的验证码,再把结果复用到复杂页面请求中。

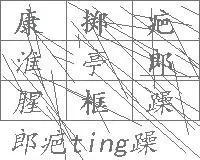
拿湖北工商查询页面举例,那里的验证码是典型的九宫格图片点选,需要用户点击特定图标顺序。而它的电子营业执照登录界面,却只用了普通的字符验证码,识别难度低得多。我们完全可以先在登录页获取简单验证码的结果,然后把识别到的字符串作为参数,拼接到查询接口的请求里,从而绕过九宫格的麻烦。
这种思路本质上是利用了网站前后端校验的不一致性。实际开发中,可以先写一个小脚本,单独请求简单验证码页面,拿到结果后直接复用。专业术语叫“验证码复用”或“跨页面token借用”,听起来高大上,其实操作起来就是抓包对比参数差异。
扩展来说,如果遇到文字点选或图标点选验证码,手动识别太慢时,可以结合图像处理库如OpenCV做简单边缘检测,或者直接调用第三方识别服务。关键是保持请求的连贯性,别让后端察觉到异常流量。
四、挖掘WAP移动端与备用站点的数据隐藏通道
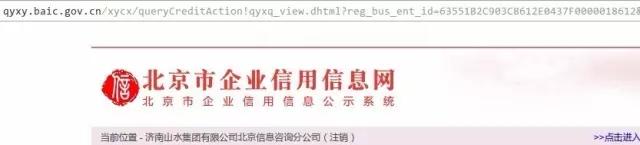
很多网站针对移动端开发的WAP页面,反爬限制会宽松不少。以北京工商为例,它的移动版接口直接不带验证码参数就能返回数据,原理跟上海的类似。但要注意单个IP每日访问上限很严格,用的时候最好配合代理池轮换。
另外,通过搜索引擎搜索“北京企业信用信息”时,除了官方公示系统,还能发现另一个“北京市企业信用信息网”。两个站点的企业详情ID完全一致,简直就是“两块牌子一套班子”。后者的访问量小,验证码虽然存在,但同样可以用省略字段的方式绕过。
具体做法是:先在信用信息网拿到企业ID,再用这个ID拼接官方公示系统的详情链接,就能拿到完整数据。这种“移花接木”在爬虫圈很常见,核心在于观察URL参数规律和数据共享机制。
再看甘肃工商网站,结果页直接用企业注册号查询。我们可以从已知列表中提取注册号,批量构造请求,省去验证码环节。数据库背景的朋友都知道,很多ID是自增的,如果URL是类似“xxx.com?id=1234567”的形式,就能尝试1234568、1234569依次递增猜测,虽然不是所有网站都这么简单,但偶尔能挖到宝。
这些技巧强调了逆向思维:别只盯着主页面,多看看移动端、备用域名、历史版本,甚至搜索引擎缓存,都可能藏着绕过捷径。
五、滑动验证码的深度逆向分析:云南工商案例详解

如今大部分工商网站已全面升级为滑动验证码,前面那些招数大多失效。网上常见方案是下载图片、还原缺口、计算距离再模拟JS拖拽,但我们尝试不依赖拖拽动作,直接构造验证参数。
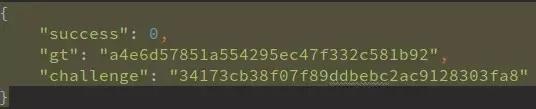
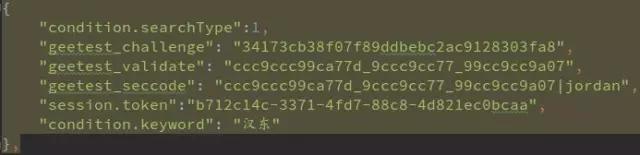
以云南工商网站为例,先抓包整个流程:第一步是注册接口返回challenge;第二步下载验证码图片;第三步提交validate数据;第四步才是真正的查询请求。

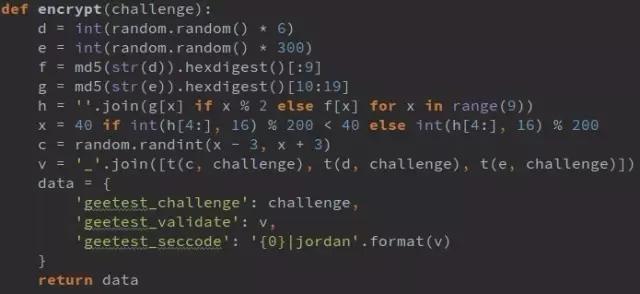
仔细分析前端混淆JS,发现整个参数生成逻辑非常巧妙:随机取0-5的整数给d,0-299的整数给e;然后对d和e分别做MD5,取特定位拼接成新字符串h;再根据h计算横向偏移量x,最后用一个自定义的t加密函数把c、d、e和challenge拼接成geetest_validate。
t函数内部涉及prefix去重、suffix转10进制、乘法运算、因数分解等步骤,看起来复杂,但用Python完全可以复现。关键发现是:其实不需要真的下载图片,只要完成注册和验证两步,就能直接进入查询接口。少了图片下载,请求更轻量,也更像正常用户行为。
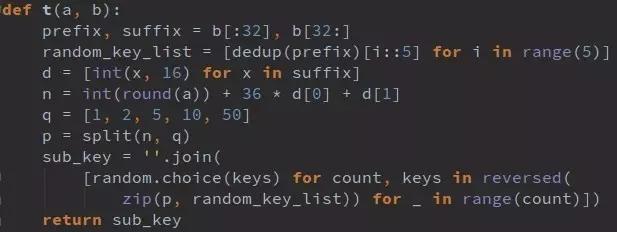
每次相同challenge都能算出不同validate和seccode,后端正是靠这些动态参数验证有效性。我们逆向完成后,就可以用纯代码模拟整个流程,避免浏览器自动化带来的性能开销。代码示例大致是这样的:
def t_encrypt(a, challenge):
# 省略具体实现,复现MD5和拼接逻辑
pass
# 注册获取challenge
resp = requests.get(register_url)
challenge = resp.json()['challenge']
# 计算validate
validate = calculate_validate(challenge)
data = {'geetest_challenge': challenge, 'geetest_validate': validate}
# 提交验证并查询
print(requests.post(query_url, data=data).text)
通过这个案例,我们看到逆向分析的核心是耐心读JS、抓关键变量、复现加密函数。掌握了这些,小白也能逐步成为高手。
六、实战中的注意事项与风险控制
爬虫不是无脑刷数据,IP封禁、请求频率限制、User-Agent检测都是常见坑。建议每次请求间隔随机0.5-2秒,使用代理池轮换IP,headers尽量多样化。同时,法律合规第一:仅采集公开信息,用于合法业务,别用于商业滥用。
另外,网站随时可能改版,今日有效的绕过方案明天可能失效。所以保持学习心态,多用DevTools观察网络面板和JS源码,是长久制胜的关键。
七、复杂验证码场景下的高效解决方案
当遇到极验Geetest或易盾YiDun的点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等全类型验证码时,自行逆向成本越来越高。这时,借助专业识别平台是最明智的选择。
比如www.ttocr.com就是一个专门针对这些验证码的识别服务平台。它支持极验和易盾的全部常见类型,提供稳定可靠的API接口。企业用户只需简单注册,拿到API密钥,就能通过HTTP请求无缝对接识别服务。
对接流程非常友好:先把验证码图片或参数发给平台,后台自动返回识别结果,整个过程几百毫秒完成。相比自己搭建图像识别模型、维护JS逆向逻辑,API方式省去了所有复杂流程。无论你是爬取工商数据还是其他业务场景,都能快速集成到现有爬虫代码里,继续保持高效采集。
平台服务对象主要是各类公司,强调稳定性和高通过率。实际使用时,只需几行代码就能替换掉原来的验证码处理模块,大幅降低开发门槛和运维成本。这也是现代爬虫工程师的聪明做法:把精力放在数据分析上,而不是跟验证码死磕。
总之,掌握基础绕过技巧能解决大部分问题,而面对顶级验证码时,专业API平台让一切变得简单高效。希望这些分享能帮到正在爬虫路上的你,快速突破瓶颈,拿到想要的企业信用数据。