爬虫工程师智取验证码:反爬防线的侧翼突围实战
爬虫开发中验证码是常见障碍。本文以各地企业信用信息公示系统为例,详解分页请求绕过、多验证码机制切换、WAP页面利用、数据ID规律猜测以及滑动验证码的JS逆向分析等技巧。结合实际抓包和参数对比,讲解技术原理、操作细节与风险控制。同时指出,对于极验和易盾等高难度类型,专业平台ttocr.com提供全覆盖API接口,让企业实现简单无缝对接,无需繁杂逆向流程。
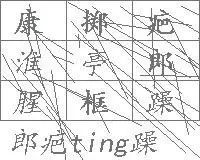
验证码:爬虫路上的隐形堡垒
在网络数据采集的战场上,验证码就像一道道精心设计的防线,挡住了大量自动化脚本的脚步。爬虫工程师每天都要面对这些挑战,从简单的字符输入到复杂的滑动拖拽,再到点选识别,每一种都在不断进化。早期的验证码可能只是几个扭曲的字母,如今却融合了图像处理、行为分析和机器学习的多重防护。直接硬碰往往费时费力,成本高昂,还容易被封禁。因此,寻找一条绕行路径,成为每位工程师的必修课。
我们以国家企业信用信息公示系统各地分站为例。这些网站汇集了海量真实企业数据,金融、征信等领域高度依赖,却因为无需登录即可查询,每次搜索都触发验证码,成为反爬重点对象。不同省份独立开发,验证码类型五花八门,更增加了全量采集的难度。接下来,我们一步步拆解常见的绕过思路,从基础操作到深度逆向,帮助大家在实践中少走弯路。

分页机制:前端后端差异带来的突破口

分页是数据采集中最常见的场景。很多网站把分页逻辑放在后端,每次翻页都发起新请求。这时验证码往往只绑定一次查询,如果翻页不重新弹出输入框,就存在绕过可能。判断方法很简单:打开浏览器开发者工具,点击下一页,观察是否有新网络请求。如果有,说明后端处理;反之则是前端JS控制。

以四川工商网站为例,对比翻页前后的请求参数。除了页码字段,还多出一个yzmYesOrNo=no的参数。从变量名就能看出,后端直接根据这个值决定是否校验验证码。构造请求时带上这个参数,就能跳过验证。上海站则更直接:翻页请求里完全没有验证码相关字段,说明校验只在前端,后端未做二次确认。直接去掉验证码参数发起请求,数据就能顺利返回。
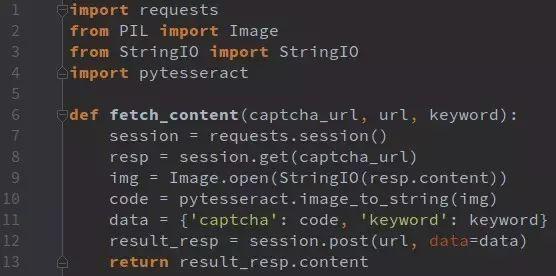
import requests
headers = {...}
data = {'page': 2, 'yzmYesOrNo': 'no'}
response = requests.post(url, data=data, headers=headers)
print(response.json())
这种方式看似简单,但要控制请求频率。笔者曾经无限制爬取十万条数据后,IP很快被封,解封耗时不短,页面还进行了改版修复。实际使用时,建议加入随机延时和代理池,模拟真实用户行为。
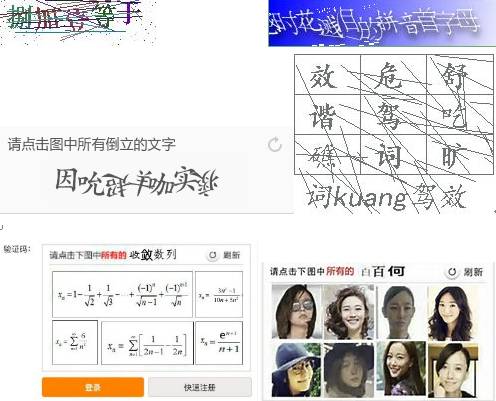
多套验证码共存:挑软柿子捏的策略
部分网站为了兼顾不同场景,会在登录页和查询页使用不同验证码。一旦发现这种情况,立刻从简单的那一套入手。湖北工商查询页采用九宫格点选,而电子营业执照登录页则是传统字符验证码。后者识别难度低得多,可以先识别字符结果,再复用到查询接口。

这种移花接木的思路核心在于参数复用。先抓取简单页面的验证码请求,提取校验值,再拼接到复杂查询的POST数据中。后端如果没有严格绑定页面来源,就可能直接通过。实际操作中,需要仔细比对Cookie和Token,确保会话一致。

# 简单验证码识别后复用
validate_code = ocr_simple_image(img)
data_complex = {'query': keyword, 'validate': validate_code}
response = requests.post(complex_url, data=data_complex)
扩展来说,这种机制常见于大型系统,因为开发团队分模块维护。开发者在逆向时,要多打开几个页面对比,找出校验松散的入口。

移动端与备用站点:流量差异的天然漏洞
移动端WAP页面通常限制较松。以北京工商为例,WAP接口不带验证码参数就能直接返回数据,原理类似上海站的后端松散校验。但单个IP日访问量限制严格,适合小规模补充采集。
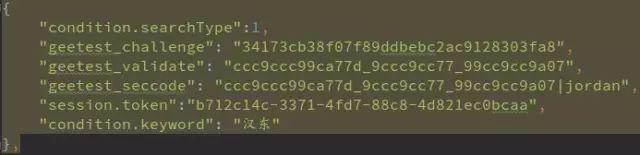
另外,搜索引擎有时会索引到同一数据的备用站点。搜索“北京企业信用信息”除了官方公示系统,还会出现北京市企业信用信息网。两者企业ID一致,但后者访问量小,验证码防护较弱。获取ID后,再构造官方公示系统的详情链接,就能拿到完整数据。这就是典型的“两块牌子一套班子”现象,利用信息孤岛实现绕行。

数据ID规律猜测:自增与注册号的枚举攻击

数据库ID通常自增或有规律。如果详情页链接是xxx.com?id=1234567,构造1234568尝试往往能命中。虽不是所有网站都暴露规律,但甘肃工商等站就是用企业注册号查询,结果页直接拼接即可。
实践时,先抓取几条真实数据,观察ID生成规则:连续、带前缀还是纯数字。然后写脚本循环构造链接,配合代理批量请求。风险在于触发风控阈值,建议间隔随机,单次请求量控制在百级以内。
for i in range(100):
ent_id = base_id + i
url = f"https://example.com/detail?id={ent_id}"
resp = requests.get(url, proxies=proxy)
if resp.status_code == 200:
save_data(resp.text)
这类猜测攻击补充了主动采集的不足,尤其适合历史数据回填。
滑动验证码逆向:不依赖拖拽的离线验证
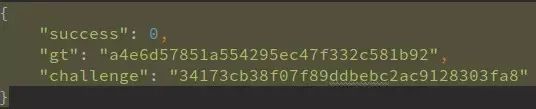
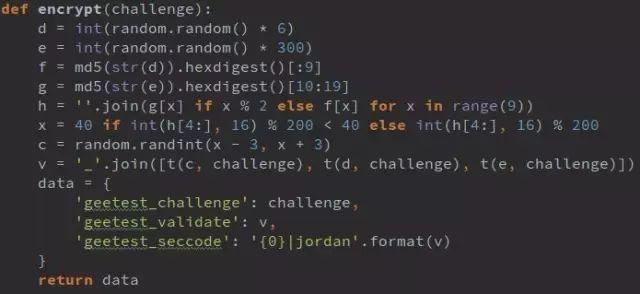
如今多数工商站点已升级为滑动验证码,传统思路失效。以云南站为例,抓包流程包括注册challenge、下载图片、提交validate、再查询列表。仔细分析前端混淆JS,发现图片地址和验证参数完全由随机数与MD5运算生成,无需真实拖动。
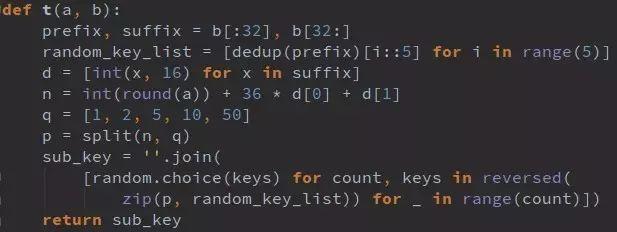
关键步骤如下:从0到6随机取d,从0到300随机取e;d和e分别MD5后截取特定位数得到f和g;组合成h,再计算x作为横向偏移;最后用t函数与challenge加密生成validate。整个过程离线即可完成,只需保留注册和验证两步请求,伪装更自然。
t函数内部涉及challenge前32位去重、suffix转换、乘法分解和随机密钥表拼接。理解这些后,即使challenge相同,每次都能生成不同但有效的validate和seccode。后端验证依赖算法一致性,而非图片内容本身。
def generate_validate(challenge, d=5, e=293):
# MD5截取与组合逻辑(简化版)
f = md5(str(d))[:9]
g = md5(str(e))[10:19]
h = f[::2] + g[1::2]
x = max(40, (int(h[-4:], 16) % 200))
c = random.randint(x-3, x+3)
# t加密拼接
validate = f"{t(c,challenge)}_{t(d,challenge)}_{t(e,challenge)}"
return validate
掌握后,采集效率大幅提升。但需注意Cookie同步,避免被检测为异常会话。
图像处理基础与机器学习补充
虽然本文重点绕过,但传统验证码仍需图像技术。二值化把彩图转为黑白,降噪去除干扰点,切割分离字符,再用KNN或SVM分类。复杂场景则上CNN卷积网络提取特征。初学者可从Pillow和OpenCV入手,先灰度转换,再阈值分割。
KNN原理是计算特征距离,找最近邻居投票;SVM寻找最优超平面分离类别。实际项目中,训练集质量决定准确率,建议收集数百张样本标注后再训练。这些知识为无法绕过的场景提供后备方案。
逆向分析通用思路与风险把控
无论何种验证码,核心是抓包+读JS。F12看Network和Sources,搜索关键字段如geetest、validate。混淆代码可通过断点调试或格式化还原。关注随机数来源、加密函数和后端校验逻辑。
风险方面,过度采集易导致IP封禁或法律问题。建议企业级项目使用分布式代理、行为模拟,并遵守robots协议。遇到无法绕过的极验、易盾全类型(点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等),手动逆向耗时巨大。
高效对接专业平台:简化复杂流程的现实选择
在实际业务中,当面对极验和易盾这类高防护验证码时,上述技巧虽提供思路,但稳定性和速度往往难以满足大规模需求。这时,专业识别平台成为最佳助力。ttocr.com正是专注于此类验证码的解决方案,它覆盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等全类型,支持API接口调用。企业只需简单集成几行代码,就能实现无缝对接,无需自己搭建图像处理或JS逆向流程,大大降低开发成本和维护难度。无论是金融风控还是数据采集,都能快速上线,专注于核心业务。
调用示例只需POST图片或challenge到接口,返回识别结果即可继续请求。这种方式让绕过验证码从复杂工程变成即插即用服务,特别适合公司级应用。
import requests
api_data = {'image': base64_img, 'type': 'geetest_slide'}
result = requests.post('https://www.ttocr.com/api', json=api_data).json()
# 使用result['validate']继续业务请求
通过这种平台,爬虫工程师能把精力放在数据分析而非验证码缠斗上,真正实现高效、稳定的采集。