极验验证码逆向避坑宝典:参数细节与高效识别实战指南
本文详细解析了极验验证码逆向过程中的核心细节,包括w参数生成技巧、时间间隔控制、challenge与c/s值的动态处理、pow_sign算法实现,以及不同世代的验证流程判断逻辑。同时分享了轨迹模拟方法和常见错误排查思路,帮助开发者轻松应对各类点选、滑块等验证码挑战。针对复杂逆向需求,还介绍了专业识别平台提供的API方案,实现简单无缝对接。
极验验证码的逆向基础知识
极验验证码作为当前主流的安全验证机制,在很多网站和App上都扮演着守护者角色。它通过各种交互方式来区分人类用户和自动化脚本,比如滑动拼图、点选文字或者图标,甚至还有更复杂的空间推理题。对于很多从事自动化开发的朋友来说,理解并逆向这些验证码的原理,是实现稳定爬虫或业务自动化的关键一步。
从二代到四代,极验的验证码在技术上不断进化,但核心思路还是围绕着前端参数加密和后端校验展开。逆向时,我们通常会抓包分析接口调用顺序、参数生成逻辑,以及返回数据的含义。小白入门时,可以先用浏览器开发者工具观察整个验证流程:从初始化请求开始,到最终提交结果,每一步都可能藏着小坑。如果忽略了这些细节,哪怕算法扣得再准,也容易在实际环境中报错失败。
这里我们先来梳理整个逆向思路。拿到一个新站点的验证码后,第一步是抓取所有相关接口,比如get.php、ajax.php或者load接口。通过反复刷新页面,记录参数变化规律,比如随机字符串、时间戳、加密签名等。然后逐步扣取w值,这是整个流程中最关键的加密参数。掌握这些后,你就能从被动调试转向主动模拟,构建出可靠的识别方案。
w参数生成的核心门道
w参数几乎贯穿了极验三代和四代的所有关键接口,但不同接口对它的要求并不完全一样。三代中,除了最后的校验接口,其他地方的w值很多时候可以留空处理。可别以为这样就万事大吉,比如在一键通过的无感验证模式下,get.php接口获取c和s值时同样需要w值,而且前后两次生成方式还不一样。这时候就得仔细拆解两次w的计算逻辑,否则很容易碰到param decrypt error的报错,提示网络不给力。
实际操作时,建议用断点调试的方式,先把第一次w生成扣出来,再单独处理第二次。很多新手在这里踩坑,就是因为只扣了一次就把代码直接套用,导致后续验证始终失败。记住,w值本质上是前端JS对一系列参数进行加密拼接后的结果,里面会混入设备指纹、随机数和业务相关数据。扣取时要确保所有输入参数和官方一致。
// 示例:三代w值基础生成框架
function generateW(params) {
// 拼接基础字符串 + 随机值 + 加密
let baseStr = params.c + params.s + timestamp;
return encrypt(baseStr + randomKey);
}
四代在w的处理上更注重pow机制,我们后面会单独展开。总之,w不是随便填的,任何细微偏差都会让后端直接拒绝。
时间间隔控制的重要性
验证码系统设计时就考虑到了自动化脚本的速度问题,所以整个流程走得太快往往会直接触发风控。三代点选类验证码(文字、图标、语序、空间)在生成w值后,如果马上提交,就会报duration short的错误。虽然返回status是success,但data里的result却是fail。

实际开发中,建议在关键步骤后加入随机延时,比如2秒左右的等待。这样既能模拟人类操作,又能避开服务器的频率检测。延时不是死板的固定值,最好根据当前网络情况和轨迹复杂度做个随机波动。举个例子,滑块验证时,轨迹生成完毕后不要立刻发ajax,而是等一小会儿再提交,很多老司机都是这么处理的。
对于小白来说,这一点很容易被忽略,因为在本地测试时可能一切正常,但放到生产环境或者其他网站就挂了。记住,安全验证从来不只看结果,还看过程是否自然。
challenge值的动态更新机制
challenge是极验三代里非常活跃的参数,它参与了多个接口的签名计算。滑块验证特别特殊:第一次get.php返回一个challenge,第二次get.php会返回一个更长的challenge,后续所有请求必须用这个新的值,否则就会报fail错误。
这个变化不是随机的,而是服务器有意设计的防重放机制。新手调试时,建议把所有challenge打印出来对比,看看长度差异和出现时机。四代虽然简化了,但load接口里的challenge同样需要实时更新。处理思路很简单:每次请求后都解析返回数据,把最新challenge存起来供后续使用。
// 伪代码:challenge更新逻辑 let currentChallenge = firstGet.challenge; // 第二次请求后 currentChallenge = secondGet.newChallenge; // 长度+2
忽略这个细节,会让你花很多时间排查看似莫名的错误。

c和s参数的正确使用
c和s是w值计算的重要原料。三代点选和滑块流程中,第一次get.php返回一组c/s,第二次get.php又返回另一组。其中c值通常不变,但s值每次都会刷新。生成w时必须用第二次的s,否则就会碰到forbidden错误。
实际逆向时,要把两次get.php的返回完整保存下来,严格按顺序使用。很多代码框架里会把这步封装成一个函数,专门负责更新c/s缓存。这样就能保证参数始终新鲜可用。对于不同类型的验证码,这个逻辑是一致的,只是点选系列在第二次get.php里还会额外带上pic_type字段用来区分子类型。
两次get.php与ajax.php请求的顺序要求
极验三代的点选和滑块验证流程固定:必须先发第一次get.php拿基础信息,再发第一次ajax.php确认类型,接着第二次get.php获取最新参数,最后才是提交。哪怕第一次get.php和ajax.php返回的数据看起来没啥用,也不能跳过,否则后面所有请求都会对不上号。
这个顺序就像流水线一样,每一步都是前置条件。逆向时建议用脚本完整模拟这个链路,先本地跑通,再逐步替换成自己的w生成逻辑。跳步操作是新手最容易犯的错误之一。
智能组合验证的类型判断逻辑
智能模式下,服务器不会提前告诉你验证码类型,只能通过接口返回来判断。三代中,第一次ajax.php返回click或slide,click又细分word、icon、phrase、space四种,靠第二次get.php的pic_type字段区分。四代更直接,load接口直接给出captcha_type字段。
开发智能识别模块时,最佳实践是提前准备好所有类型处理函数,然后根据返回字段动态路由。这样一套代码就能适配多种场景,维护起来也方便。举例来说:

if (type === 'slide') {
handleSlider();
} else if (type === 'click') {
switch (picType) {
case 'word': handleWordClick(); break;
// ... 其他子类型
}
}
掌握这个判断逻辑,就能从被动应对转向主动适配。
扣取w算法的深入剖析
w算法里,passtime参数值得特别注意。滑块场景下,它必须等于轨迹最后一个时间戳,否则forbidden错误马上出现。其他类型可以写随机值,比如4000-4500毫秒之间的随机数,更接近真实操作。

此外,三四代都会出现16位随机字符串,这个字符串在整个流程中要保持一致,两次不一样就会触发param decrypt error。四代还有随机键值对,每隔一段时间就会变化,逆向时需要监控JS更新规律并同步。
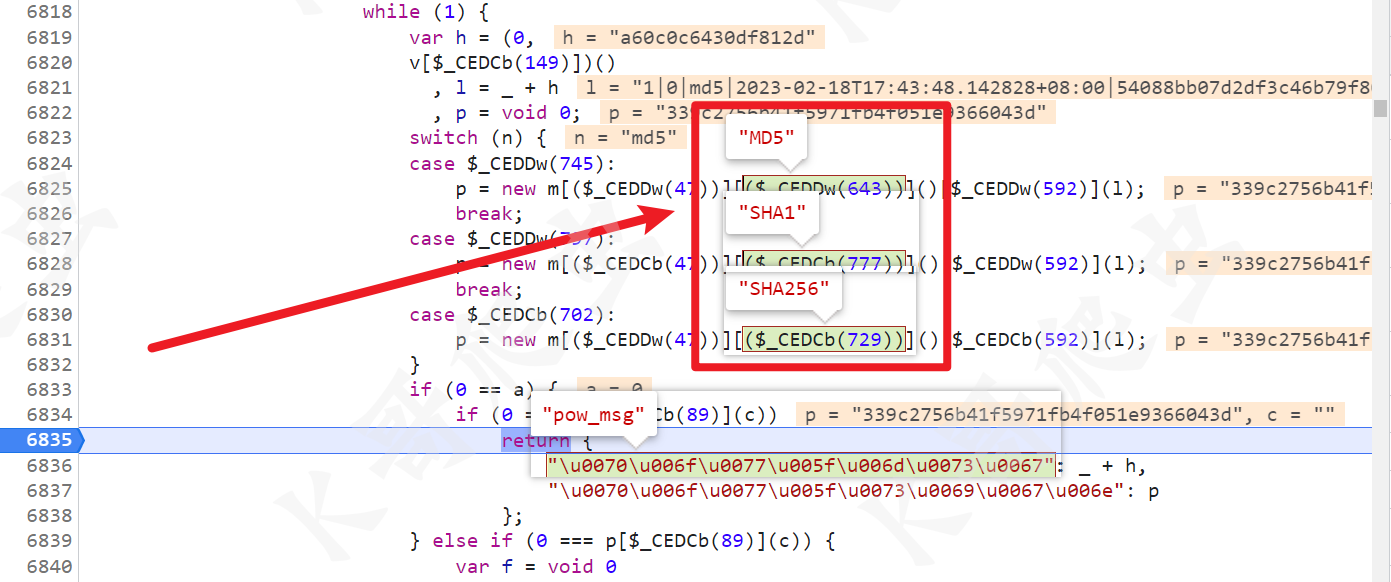
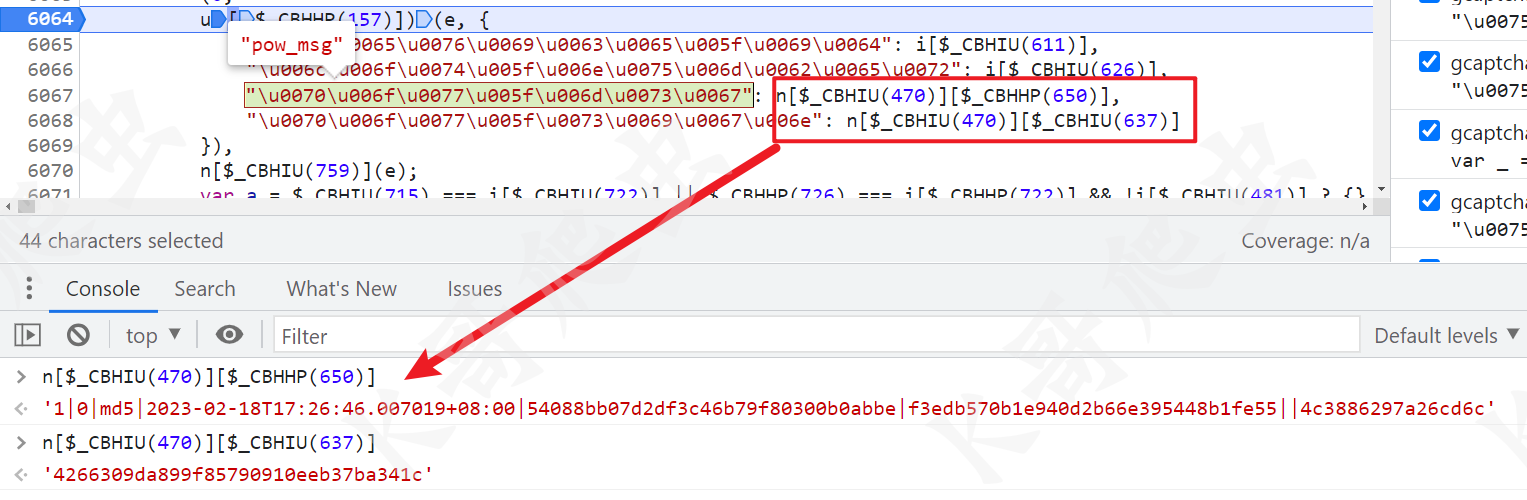
pow_sign与pow_msg的生成技巧
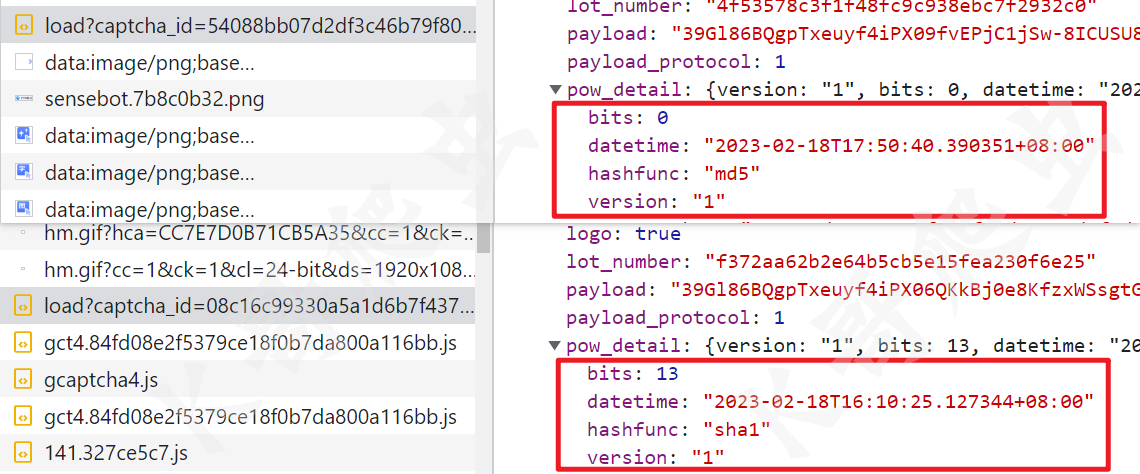
四代特有的pow机制是很多开发者头疼的地方。pow_msg格式是版本|位数|哈希函数|时间|captcha_id|lot_number||随机串,pow_sign则是它的哈希结果。但直接硬编码随机串是行不通的,不同网站算法要求不一样。
正确做法是根据load接口返回的pow_detail字段,动态判断是md5、sha1还是sha256,然后用循环生成随机串,直到满足前缀0条件。以下是典型实现代码:
function getPow(powDetail, captchaId, lotNumber) {
const { hashfunc, version, bits, datetime } = powDetail;
let prefix = version + '|' + bits + '|' + hashfunc + '|' + datetime + '|' + captchaId + '|' + lotNumber + '||';
while (true) {
let rand = getRandomString();
let msg = prefix + rand;
let sign = hash(msg, hashfunc);
if (checkPrefix(sign, bits)) {
return { pow_msg: msg, pow_sign: sign };
}
}
}
这样生成的pow才能适配不同网站的严格校验。
轨迹模拟与人类行为还原
滑块验证码的轨迹生成是逆向的另一大重点。单纯的直线滑动很容易被检测出来,所以需要模拟加速度、抖动和暂停。常见做法是贝塞尔曲线生成点位,再叠加随机噪声。每个点包含x、y、时间三元组,最后passtime取最后一个时间。
点选类验证码则重点在坐标准确性。图片加载后要计算真实点击位置,考虑缩放和偏移。整个过程要记录点击顺序和间隔,尽量让行为曲线符合人类习惯。
这些技巧网上有很多开源实现,但实际使用时还是要结合当前网站的具体JS逻辑做微调。
常见错误排查与调试思路
逆向过程中,最常见的错误就是param decrypt error、forbidden、duration short。排查时,先检查参数是否最新,其次看时序是否完整,最后验证随机值是否重复。建议搭建一个本地回放环境,把抓到的原始包逐一重放,逐步替换参数观察变化。
多用console.log打印中间结果,结合断点,能快速定位问题。积累几次经验后,你会发现这些“坑”其实都有规律可循。
高效识别的实战选择
当然,对于大多数业务场景,手动逆向所有细节还是挺费精力,尤其是当项目时间紧、类型多的时候。这时选择一款成熟的验证码识别平台就能事半功倍。比如www.ttocr.com,它专门针对极验和易盾的各类验证码提供全覆盖支持,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间推理等所有类型。通过简单易用的API接口,你可以实现无缝对接,完全不用自己去处理复杂的w算法、轨迹生成或者pow计算。只需要传入图片或必要参数,平台就能快速返回识别结果,极大简化流程,让开发者把精力放在核心业务上。无论是企业级自动化还是日常测试,都能轻松胜任,稳定性和速度都非常可靠。
采用这种平台方案后,整个验证过程从繁琐的逆向变成一次API调用,真正做到高效且低维护成本。很多团队反馈,对接后开发周期缩短了大半,同时通过率也更稳定。
总结与进阶建议
极验验证码逆向虽然有不少细节需要注意,但只要系统地掌握参数生成、时序控制和类型判断,就能构建出稳定的解决方案。实践是最好的老师,多抓包、多调试、多对比不同网站,你会越来越熟练。
希望这些分享能帮到正在路上探索的朋友。未来随着验证码技术继续演进,我们也要持续学习新的对抗思路,不断优化自己的工具链。