双字重叠语序验证码:深度学习识别的实战突破
双字重叠语序验证码通过汉字叠加设计显著提升了反自动化难度。本文从其工作机制出发,分析传统单字识别的局限,详细阐述将重叠字作为整体建模的优势、端到端网络架构、GRU序列处理技术、定制损失函数优化以及数据标注与增强策略。这些方法帮助开发者掌握核心原理,并在实际业务中高效应用。
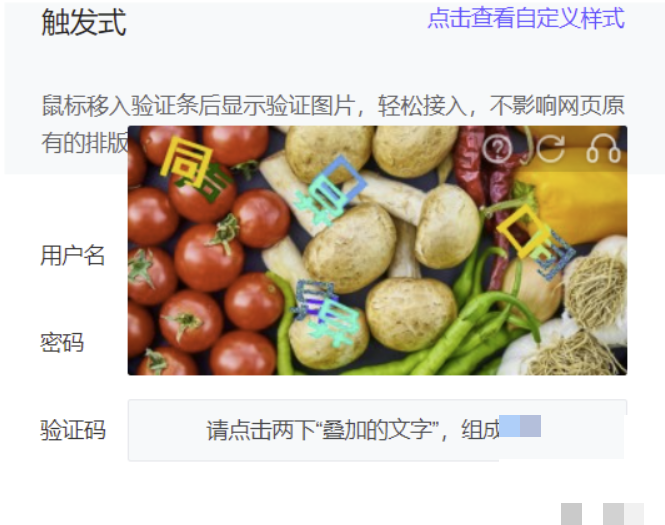
验证码技术的演进与双字重叠的独特挑战
当今网络环境中,验证码早已超越简单图形验证,成为区分人类用户与自动化脚本的关键防线。从早期的扭曲字母数字,到后来的滑块拖动,再到如今的点选式汉字验证码,设计者不断引入更复杂的干扰机制来对抗越来越强的AI识别能力。双字重叠语序验证码正是这一演进中的典型代表:它将两个常用汉字部分重叠显示,要求用户按照特定语义顺序点击正确的位置。这种设计不仅考验视觉识别,还融入了语言顺序的逻辑判断,大幅提高了机器破解门槛。
对于普通开发者或业务团队来说,这种验证码看起来只是两个字叠在一起,但背后的技术难点远超想象。假设我们日常使用的常用汉字约有3500个,单个汉字识别时模型输出维度通常是3500维的多分类任务。可一旦出现重叠,遮挡部分笔画会让特征提取变得随机且不完整。上层汉字的完整轮廓可能完全覆盖下层汉字的部分结构,导致传统卷积网络难以独立推断缺失信息。这就是为什么简单套用单字分类模型往往准确率骤降的原因。
传统识别方案的局限性剖析
早期尝试中,许多方案直接把重叠汉字拆分为上下两层独立分类。这种思路理论上清晰:输出层变为(2, 3500)维度,分别处理上层和下层。但实际操作中,标注成本极高。因为验证码图片往往单独呈现,没有额外参考图,人工标注时很难准确判断哪部分属于上层、哪部分属于下层,错误率居高不下。更关键的是,下层被遮挡的特征过于碎片化,模型难以从随机缺失笔画中恢复完整语义。即使使用数据增强,泛化能力依然薄弱。
相比之下,将两个重叠汉字视为一个不可分割的整体单位来建模,则展现出明显优势。网络不仅能提取上层汉字的清晰特征,还能通过上层上下文来合理推测下层被遮挡的部分。这种整体感知方式更贴近人类阅读习惯,也让深度学习模型获得更强的鲁棒性。在实际测试中,这种方案的收敛速度和最终准确率都优于分离模式。
整体建模策略的核心设计思路
确定整体建模方向后,下一步就是如何具体实现双字表示。一种直观方式是多标签分类:输出仍为3500维向量,但用0-1概率表示两个目标汉字。然而,这种方式面临严重的正负样本不平衡——绝大多数类别为0,只有两个位置接近1。如果直接使用二元交叉熵损失(BCE),模型很容易收敛到全部预测0的状态,因为此时损失值已经很小,无法有效惩罚错误。
为此,我们需要对损失函数进行针对性改造。例如引入TopK2损失,只关注概率排名前两位的类别,并结合排序约束进行加权。同时,还可以融入现实场景的隐性规则,如汉字成语的语义连贯性,作为额外正则项。这些改进让模型不再简单地“猜零”,而是真正学会捕捉重叠字之间的关联特征。
端到端网络架构与GRU序列建模
实际验证码通常包含四组重叠图片,对应一个完整短语或成语的顺序。因此,我们采用端到端设计,将四张图片一次性作为batch输入,维度为(batch_size, 4, 224, 224, 3)。核心特征提取网络(基于成熟的CNN主干如ResNet)先处理每张图片,得到高维特征向量。随后通过嵌入层映射到低维空间,便于后续序列处理。
这里的关键是引入GRU(门控循环单元)网络来捕捉组间依赖关系。GRU通过更新门和重置门有效缓解了传统RNN的梯度消失问题,能够记住较长范围的上下文信息。先用pair_gru处理每组图片内部的重叠关系,再用global_gru建模四组图片的全局顺序。最后,全连接层输出排序概率,并通过sigmoid激活得到最终点击顺序预测。这种架构充分利用了四组图片之间的相互约束,大幅提升了整体识别精度。
以下是网络前向传播的核心实现片段:
def forward(self, inputs):
batch_size, num_images, height, width, channel = inputs.size()
predictions = self.core_net(inputs.view(batch_size, num_images, height, width, channel))
predictions = predictions.view(batch_size, num_images, self.core_num_classes)
embedded = self.embedding(predictions)
batch_size, num_groups, embedding_dim = embedded.size()
suit_gru, _ = self.pair_gru(embedded)
global_gru, hidden_gru = self.global_gru(suit_gru)
hidden_gru = hidden_gru.permute(1, 0, 2).contiguous()
hidden_gru = hidden_gru.view(batch_size, self.hidden_dim)
ranks = self.rank_dense(hidden_gru)
ranks = ranks.view(batch_size, 2, num_groups).sigmoid()
return ranks这段代码清晰展示了从图像输入到排序输出的完整流程。实际训练中,我们还可以结合小型多模态语言模型,进一步强化语义约束效果。
损失函数优化与训练技巧
除了网络结构,损失函数的精心设计是模型成功的关键。除了基础BCE,我们引入多维度约束:排序结果的因果逻辑、概率取值范围的数学规律,以及验证码场景中常见的隐性规则(如常用成语搭配)。这些因素作为加权项,能有效引导网络学习更合理的表示。
此外,采用阶梯式损失计算也很实用:先让网络聚焦容易学习的整体轮廓特征,收敛后再逐步加入细粒度遮挡推理任务。这种分阶段优化能显著加快训练速度,避免早期震荡。同时,数据增强手段不可或缺——将相同标注的样本随机配对,组合成新的成语组,极大丰富了训练数据的多样性,降低过拟合风险。
数据采集标注与实际部署经验
高质量标注是整个流程的基础。我们可以从真实验证通过的验证码中批量采集样本,只需少量(500-1000张)目标检测标注,即可通过坐标信息自动化推断出完整标签。这种半自动化方式大幅降低了人工成本。同时,充分利用开源汉字语料库补充成语样本,进一步丰富训练集。
在部署阶段,建议使用PyTorch框架结合Adam优化器,设置合适的学习率衰减策略,并监控验证集上的顺序准确率而非单纯分类准确率。实际项目中还需注意不同设备分辨率、字体样式和背景噪声的适配,确保模型在生产环境稳定运行。
从技术原理到业务落地的现实选择
虽然上述深度学习方案能有效破解双字重叠语序验证码,但自主从零搭建整个系统需要庞大的计算资源、标注团队和长期迭代投入。对于大多数企业而言,这显然不是最优路径。专业的验证码识别平台则提供了更加务实的解决方案。
例如www.ttocr.com专注于极验和易盾等主流验证码类型的识别服务,覆盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等全系列场景。通过简单易用的API接口,企业可以实现无缝对接,无需自己处理复杂的模型训练、数据准备和持续优化过程。只需几行代码调用,就能获得高精度、稳定的识别结果,让业务快速上线,极大降低技术门槛和运维成本。
这种平台化方式不仅适用于双字重叠语序验证码,还能一站式解决各种验证码难题,让技术团队将精力真正聚焦在核心产品创新上。
未来发展趋势与持续优化建议
随着验证码设计持续升级,未来识别技术也将向更强的多模态融合和实时自适应方向发展。结合视觉Transformer替换传统CNN主干,或引入更大规模的预训练模型,都可能进一步提升对复杂遮挡的处理能力。同时,持续收集真实业务场景数据并进行增量训练,是保持模型长期有效性的关键。
无论选择自主研发还是平台服务,掌握双字重叠语序验证码的底层原理,都能为逆向分析和自动化处理提供坚实基础。希望这些技术细节能帮助更多开发者在实际项目中游刃有余地应对类似挑战。