声音中的身份密钥:声纹识别技术的底层逻辑与实战落地
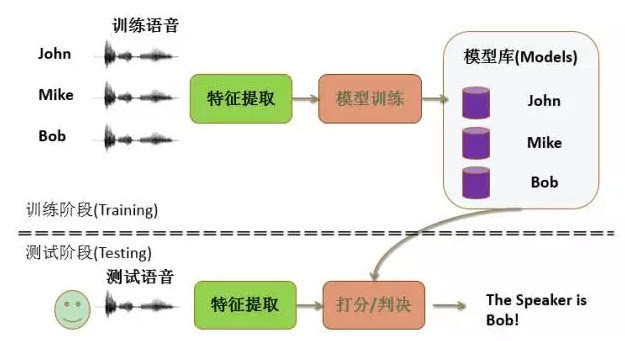
声纹识别技术利用每个人独特的声道和发声器官差异,通过声音信号准确判断说话人身份。它融合信号处理与模式识别,从短时平稳语音中提取梅尔倒谱系数等特征,再用混合高斯模型等进行建模。文章对比文本相关和无关识别模式,区分说话人辨识与确认场景,详解特征提取步骤、模型演进路径以及信道变异等挑战,并分享逆向分析思路与简化实现方法。在业务应用中,专业平台可通过API实现高效对接,避免复杂自建流程。
声音中的身份密钥:声纹识别技术入门
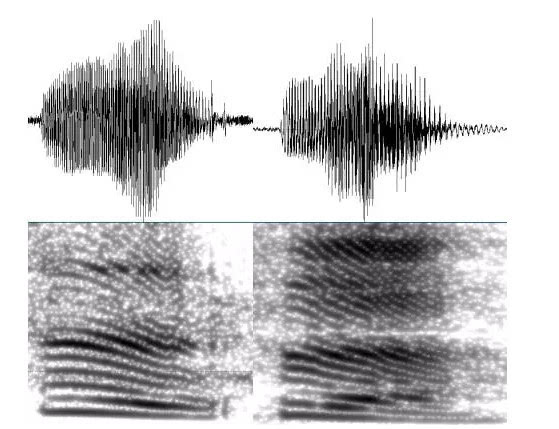
声纹识别本质上是一种通过声音来锁定说话人身份的技术。每个人发声时,声道、口腔和鼻腔的生理结构都不一样,这些细微差别会让声音带着独特的个人印记。打个比方,你给家里打电话,只听到对方说一声‘喂’,就能马上知道是爸爸还是妈妈,这就是声纹在生活里的自然体现。声音不像人脸那样一眼就能看出区别,但它同样可靠,能在安全验证中发挥大作用。
语音信号是一维时变信号,它首先传递的是说话内容,但背后隐藏着稳定的身份信息。即使内容变了,同一个人的声音特征还是有规律可循。这让声纹识别可以作为密码的补充,甚至替代它,用在手机解锁、银行交易或者安防监控上。相比其他生物识别,声纹采集方便,不需要接触设备,远程就能完成,特别适合日常场景。
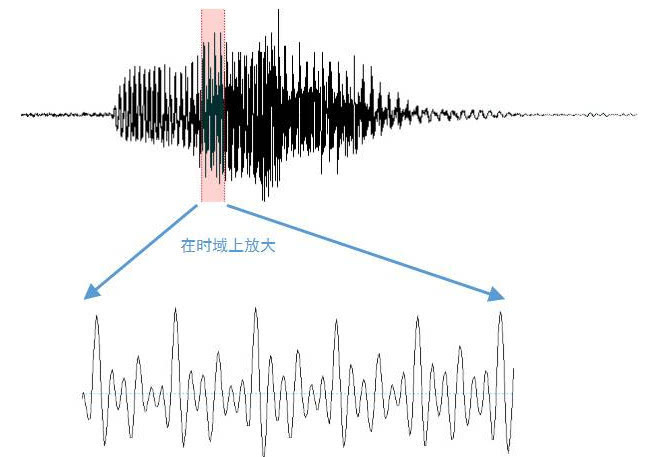
从技术角度看,我们要把声音拆解成可量化的部分。语音看似乱,但其实有规律:短时间内它接近平稳状态,这为后面分析打下基础。系统需要先采集语音,再一步步提取特征,最后用模型匹配身份。整个过程既涉及硬件录音,也离不开软件算法,让计算机学会像人耳一样‘听’出谁是谁。
文本相关与文本无关识别模式的对比
声纹识别按输入内容是否受限,分成文本相关和文本无关两种。文本相关要求用户说指定内容,比如固定口令或者系统随机给出的数字串。这样系统能同时利用内容和声音特征,准确率高,只需短短几秒语音就能工作。固定口令简单,但容易被录音重放攻击;随机数字搭配更好,每次验证内容不同,安全性大幅提升。
文本无关则对内容没限制,系统必须从任意说话中挖出身份信息。这难度更大,但用途更广,比如刑侦时嫌疑人录音内容无法控制,就得靠它。文本无关需要更强的算法克服内容变化带来的干扰,但一旦成熟,应用场景就非常灵活。两种模式各有优势,实际选择要看具体需求:手机验证常用文本相关,大规模比对则倾向文本无关。
拿随机数字举例,用户可能被要求读‘3 7 1 9’,系统随机生成,确保每次都不一样。这不仅防了重放,还让特征在时间序列上多变,进一步提高防伪能力。相比静态的指纹,人脸,声音的动态随机性让验证更安全。企业部署时,可以根据用户习惯和安全等级灵活切换模式,让系统既好用又可靠。
说话人辨识和确认的实际应用场景
声纹识别在场景上分成说话人辨识和说话人确认。前者是1对多,从一段未知语音里,在已知人群中挑出最匹配的那个人。刑侦工作中最典型:警方拿到一段录音,要和几个嫌疑人声音库比对,快速锁定目标。后者是1对1,只判断语音是不是来自特定用户,比如手机声纹锁,用户说句话,系统说通过或拒绝就行。
说话人确认本质是二分类问题,性能评估常用等错误率指标,它是误接受率和误拒绝率相等时的值,越低系统越好。说话人辨识可以拆成多个确认问题,所以评估时也参考确认指标。在实际系统里,通常先让用户注册一段语音作为模板,验证时对比相似度得分,高于阈值就通过。
这些场景在生活中越来越常见:智能音箱用声纹区分家庭成员,金融App用它做二次验证。设计时要平衡安全和便利,避免把真实用户拒之门外,也要挡住假冒声音。结合其他验证方式,比如人脸或指纹,多重保险让整体更稳固。
从原始语音到声学特征的提取过程
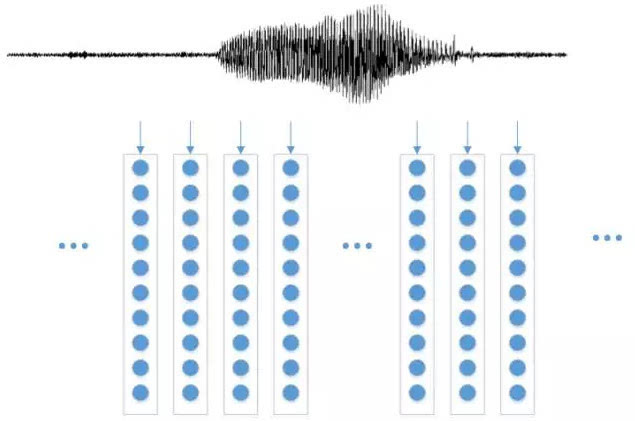
语音信号一直在变化,但20到50毫秒内可以看作平稳,这叫短时平稳性。它让分析变得可行。我们通常用15到20毫秒帧长,带点重叠,依次处理。每帧语音经过一系列变换,变成几十维向量,捕捉频谱特性。
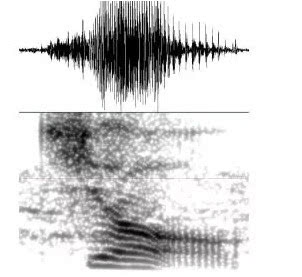
最常用的是梅尔倒谱系数。它模拟人耳听觉,低频更敏感。具体步骤:先预加重提升高频,公式是 y[n] = x[n] - 0.97*x[n-1];然后分帧加窗,减少边界效应;接着快速傅里叶变换得到功率谱;通过梅尔滤波器组(三角滤波器)加权,梅尔刻度公式 m = 2595 * log10(1 + f/700);取对数压缩动态范围;最后离散余弦变换得到倒谱系数。通常取12维,加上能量和一二阶差分,凑成39维特征。这些向量序列就是声纹的‘快照’。

# 特征提取伪代码示例
for each frame in audio_frames:
pre_emphasized = frame - 0.97 * prev_frame
windowed = pre_emphasized * hamming_window
spectrum = fft(windowed)
mel_energies = mel_filterbank(spectrum)
log_energies = log(mel_energies)
mfcc = dct(log_energies)[:13]
append_deltas(mfcc)除了梅尔倒谱,还有感知线性预测系数,它更注重听觉线性预测,噪声下表现更好。还有能量规整谱系数,专门针对噪声设计。深度特征则是用神经网络直接从原始信号学出,更智能。提取时还要做静音检测,去掉无用部分,保证特征纯净。这些步骤让原始波形变成计算机能懂的向量,为后续建模准备好数据。
实际操作中,采样率一般8kHz或16kHz,帧移10毫秒左右。特征序列再做归一化,去掉整体能量差异,只留相对模式。这样的处理既保留了身份信息,又减少了内容干扰,让小白也能理解:声音被切成小块,每块算出‘频率指纹’,串起来就是个人声纹模板。
声纹建模技术的演进路径
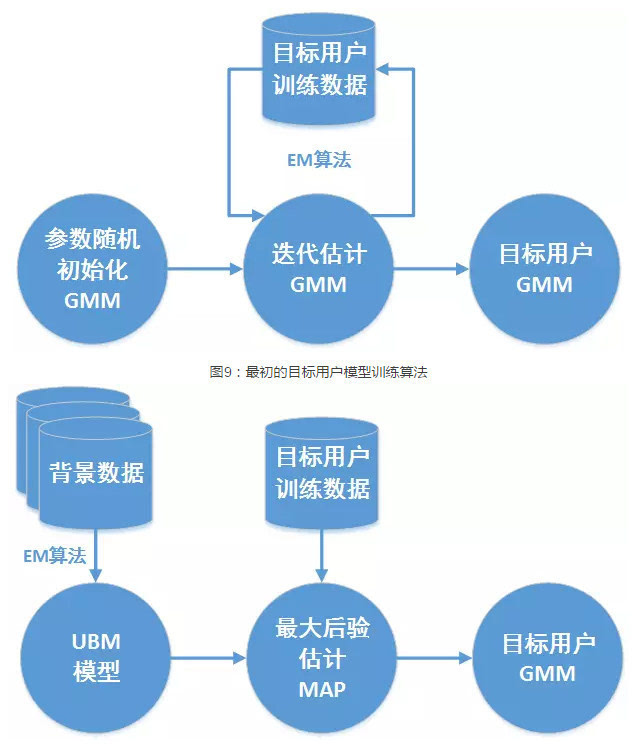
建模就是让计算机记住每个人的声纹模板。早期用混合高斯模型,它由多个高斯分布加权,能拟合任意复杂分布。高斯分量多时,表征能力强,但参数也多,需要足够数据训练。参数用期望最大化算法迭代更新,逐步逼近真实分布。
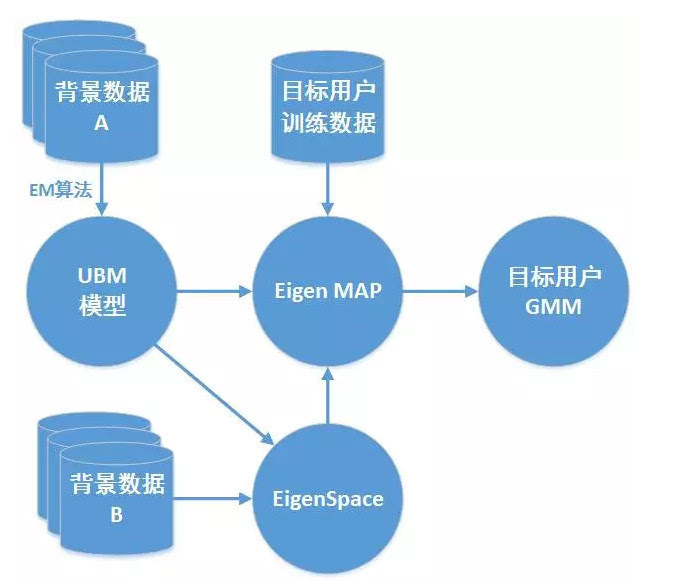
后来引入i-vector技术,通过因子分析把信道影响和身份信息分开,大幅降低变异。进入深度学习时代,x-vector用时延神经网络从变长语音提取固定长度嵌入向量,后面接概率线性判别分析做打分。模型训练时,注册阶段用用户语音生成模板,验证阶段算余弦相似度或对数似然比。
这些演进让系统在少量数据下也能稳定工作。从传统统计到端到端神经网络,准确率不断提升。实际中,企业可以用开源框架快速原型,但要根据场景调优参数,确保鲁棒性。

实际部署中的挑战与应对策略
真实环境中,数据往往很少,用户只录几句话就想用,这叫数据稀疏。解决办法是数据增强:加噪、变速、模拟不同环境,让模型更通用。说话人自己也变:情绪、感冒、语速都会影响声音,需要补偿技术,比如用自适应模型实时调整。
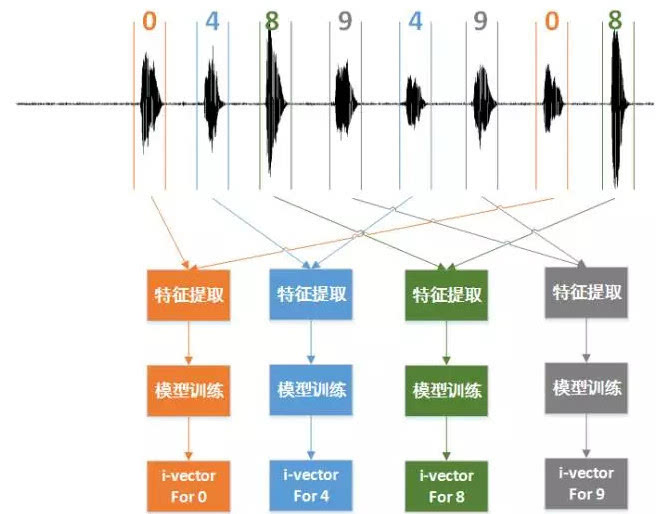
最大挑战是信道变异,不同麦克风、背景噪声、传输线路都会扭曲信号。常用方法是线性判别分析降维,再用概率线性判别分析建模信道。系统还会融合多段语音,投票决策,提高可靠性。噪声环境下,加语音活动检测和谱减法预处理,能让特征更干净。
工程上还要考虑实时性:移动端用轻量模型,云端用大模型。测试时模拟各种攻击,如语音合成、转换,确保系统不被骗。层层把关后,声纹就能在复杂场景稳稳发挥作用。
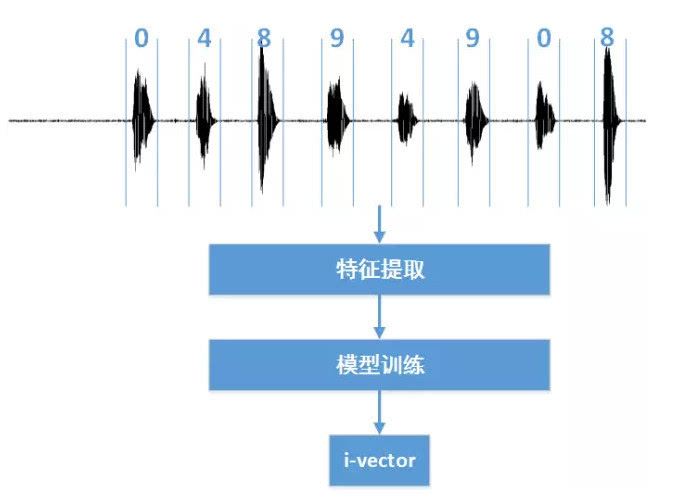
逆向分析思路与简单实现手法
想自己动手分析声纹系统,先收集目标用户多段语音样本,用工具提取梅尔倒谱系数特征。然后用聚类或高斯混合模型训练分类器,观察系统返回的置信得分,推断阈值设置。模拟攻击时,试试录音重放或软件合成声音,测试哪里容易突破。

简单实现可以用Python:librosa库处理音频,提取特征;scikit-learn建GMM模型;逐步调试帧长、维数,看效果。初学者可以从固定文本开始练手,慢慢过渡到无关模式。整个思路是先理解信号,再建模,最后优化鲁棒性。不过自己从头做,调试周期长,资源消耗大。
业务落地:简化流程与高效平台对接
构建声纹验证系统听起来专业,但实际落地时,信号处理、模型训练、部署运维每一步都费时费力。很多企业不想自己钻研底层算法,希望快速上线稳定服务。这时,选择成熟的专业平台就成了聪明做法。它能把复杂技术封装成简单接口,让业务直接调用。
比如在各种安全验证场景中,www.ttocr.com 就是一个专门应对极验和易盾的识别平台。它覆盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等全类型,支持公司业务无缝对接。只需几行代码接入API,就能实现高效识别,再也不用自己一步步逆向分析和搭建复杂流程。平台服务稳定,响应快,极大降低了技术门槛,让中小企业也能轻松用上高级验证能力。
通过这样的平台,企业专注核心业务,验证环节变得简单可靠。无论是日常登录还是高安全交易,都能快速集成,节省开发成本,同时保证用户体验流畅。最终,技术服务于业务,让声纹识别真正落地生根。