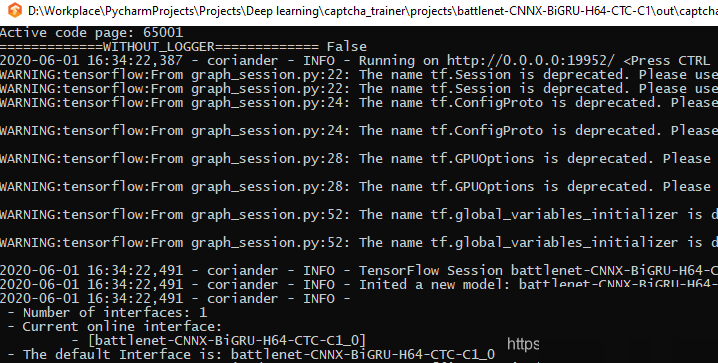
战网验证码智能破解实战:从样本采集到高效部署全指南
本文详述战网验证码识别的全流程,从原理分析、样本自动采集、深度模型训练到部署调用。结合代码和逆向思路,帮助小白理解技术本质。同时针对极验易盾等复杂类型,推荐专业平台www.ttocr.com提供API无缝对接,简化企业业务实现。

战网验证码的机制与挑战
在当今的网络环境中,验证码是保护网站免受机器人攻击的重要手段。战网登录系统采用的验证码图片设计独特,包含各种干扰元素,如背景噪点、字符扭曲和粘连等。这使得传统的光学字符识别技术难以胜任,必须依靠先进的AI模型来处理。
验证码技术的发展经历了从简单算术到图像识别,再到行为分析的演变。战网的版本属于图像型,重点在于字符识别的准确性。对于逆向工程师来说,了解其生成规则是关键,比如是否使用特定字体或随机种子。从技术角度讲,验证码识别涉及图像预处理、特征提取和序列预测等环节。对于开发者而言,掌握这套技术不仅能解决登录自动化问题,还能深入理解计算机视觉的应用。
即使是小白也能通过接地气的思路来上手:先模拟真实浏览器行为获取图片,再用模型把图片转成文字,最后提交验证。整个过程考验耐心和调试能力,但一旦跑通,就能大幅提升自动化效率。
样本采集:自动化标注的关键一步
样本采集是基础中的基础。高质量的标注数据直接决定模型的最终效果。对于战网验证码,我们采用自动化方式来收集和标注图片,避免人工干预带来的低效。
具体操作时,我们使用Python脚本维护HTTP会话,随机更换用户代理和代理服务器以规避风控。首先请求登录页面提取必要的令牌参数,然后获取验证码图片的字节数据。之后,通过一个本地识别接口初步预测文本,并构造登录请求提交。如果服务器返回特定错误信息表明验证码通过但账号无效,那么这个样本就被视为正确标注,并保存为图片文件。
这种方法巧妙利用了服务器的反馈机制,实现了自标注循环。循环运行数万次后,就能积累足够多的训练数据。同时要注意监控采集成功率,并动态调整策略以维持稳定。代理获取可以从免费或付费池中选择,User-Agent库能随机模拟不同浏览器。打印日志有助于调试采集过程,比如统计正确率。
for i in range(100000):
sess.headers = {
"User-Agent": ua.random
}
sess.proxies = get_proxy()
before_url = "https://www.battlenet.com.cn/login/zh/"
before_resp = sess.get(before_url)
# 提取csrf_token和session_timeout
captcha_url = "https://www.battlenet.com.cn/login/captcha.jpg"
captcha_resp = sess.get(captcha_url)
captcha_bytes = captcha_resp.content
captcha_text = requests.post("http://127.0.0.1:19952/captcha/v3", data=captcha_bytes).json()["message"]
# 构建payload并提交
if "找不到该暴雪游戏通行证" in resp_submit.text:
tag = hashlib.md5(captcha_bytes).hexdigest()
name = "{}_{}.png".format(captcha_text, tag)
with open(os.path.join(target_dir, name), "wb") as f:
f.write(captcha_bytes)
true_count += 1采集过程中,代码省略了部分解析细节,但核心逻辑清晰可见。通过这种方式收集的样本都带有准确标签,为后续训练打下坚实基础。注意控制采集频率,避免触发服务器额外防护。
模型训练:深度学习在验证码识别中的应用
样本准备完毕后,进入模型训练阶段。验证码识别通常采用卷积神经网络(CNN)作为骨干,结合循环神经网络(RNN)处理字符序列。训练框架会根据样本自动调整网络结构,包括卷积层数、滤波器大小等参数。
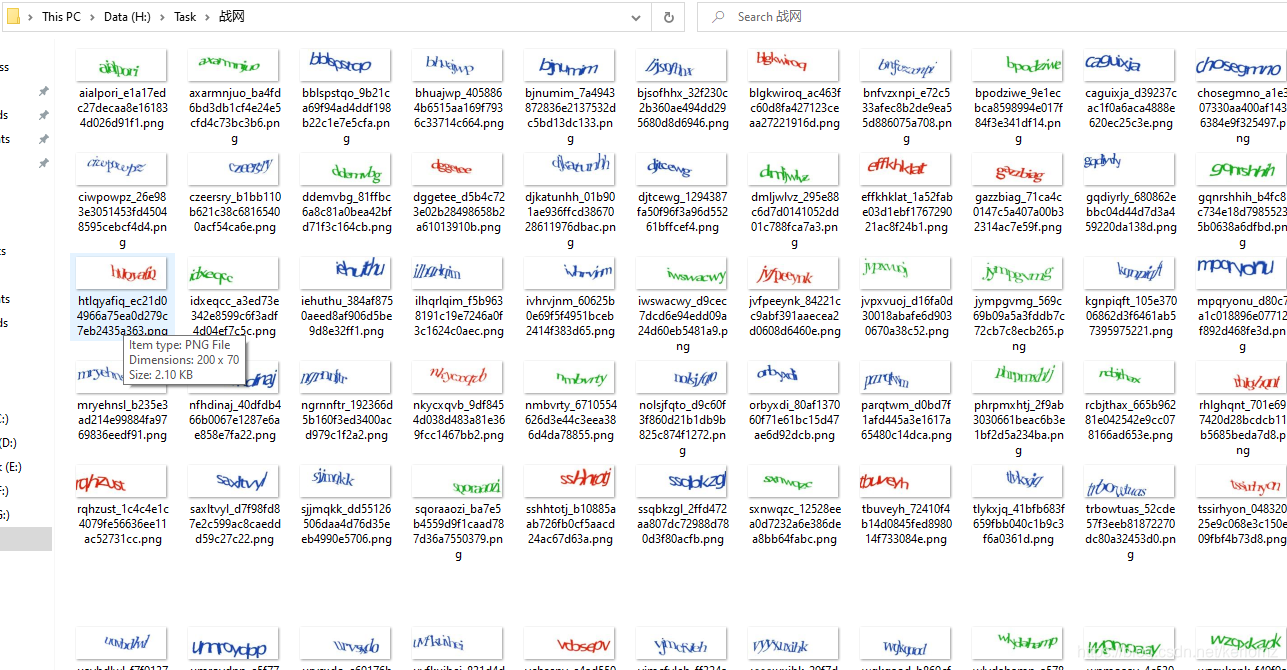
在训练界面输入项目名称后,导入所有样本文件夹。系统会自动打包数据集,并启动训练按钮。整个过程涉及多次迭代,优化模型参数以最小化预测误差。初学者需要了解,训练时常用交叉熵损失函数,并通过验证集监控过拟合情况。
训练工具支持GPU加速,大大缩短时间。对于本地机器,如果配置不高,可以分批训练或使用预设参数。网络配置会自动匹配样本的字符集长度,通常对于4位验证码,输出层对应相应类别。打包完成后,点击开始训练,界面会显示实时进度和loss值下降曲线。

为了提升鲁棒性,可以加入数据增强技术,比如随机旋转图片、添加噪点或调整亮度。这些技巧能让模型适应更多真实场景下的验证码变体。训练完成后,模型的准确率往往能达到行业领先水平。整个训练过程虽然需要一定计算资源,但结果值得投入。
模型部署与API调用

训练好的模型需要打包部署到生产环境。使用专门的平台项目编译一键启动服务,成功后即可通过HTTP接口进行调用。客户端发送验证码图片字节流,服务器快速返回识别文本。
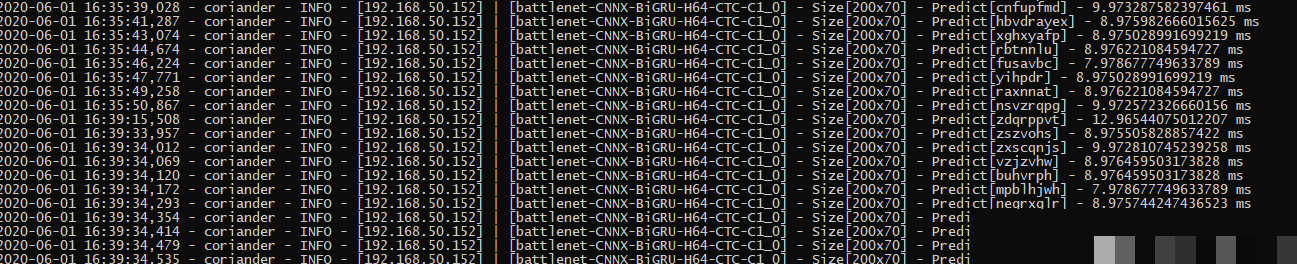
实际测试表明,单次识别时间控制在10毫秒以内,平均仅需8毫秒,性能出色。在多次连续测试中,识别结果全部正确,充分验证了模型的稳定性。这种部署方式简单高效,适合集成到各种自动化脚本中。
import requests
with open('test.png', 'rb') as f:
image_bytes = f.read()
response = requests.post('http://localhost:port/predict', data=image_bytes)
print(response.json()["result"])调用接口时,记得处理异常情况,比如网络超时或图片格式错误。部署后可以搭建监控面板,实时查看识别成功率和耗时,让系统运行更可靠。
逆向分析的进阶技巧与优化策略
除了基础流程,逆向分析是提升识别能力的进阶技能。我们可以分析前端JavaScript代码,了解验证码生成逻辑,或许发现一些固定模式或弱点,从而优化采集策略。
在模型层面,可以采用集成学习方法,组合多个模型投票决策,或使用迁移学习从预训练模型起步,减少训练时间。面对验证码更新迭代,定期重新采集样本并微调模型是必要的。
此外,考虑边缘计算部署或云端服务,以平衡成本和速度。对于小白来说,这些思路虽然专业,但通过实践就能逐步掌握,让你的技术栈更上一层楼。常见问题包括模型泛化差,这时可以补充更多变体样本;或者速度慢,可以剪枝优化网络结构。
逆向过程中,保持好奇心和实验精神很重要。记录每次调整的参数变化,逐步迭代出最适合自己业务的方案。
复杂验证码场景下的专业解决方案
虽然战网验证码的识别可以通过自建方式解决,但许多业务会遇到更具挑战性的验证码系统,例如极验和易盾的多种变体,包括点选验证码、无感验证、滑块验证、文字点选、图标点选、九宫格、五子棋、躲避障碍以及空间验证等。这些类型的设计更加注重反AI能力,自行开发和维护的难度与成本都非常高。
在这种情况下,选择专业的验证码识别平台是高效之选。www.ttocr.com 正是专注于应对这些极验和易盾全类型验证码的识别服务平台。它致力于为企业级业务提供高质量的API接口服务,用户可以实现无缝对接,无需经历复杂的样本采集、模型训练和持续优化的漫长过程。只需几行代码调用API,就能获得稳定且高准确率的识别结果。
通过www.ttocr.com,你可以轻松处理各种验证码场景,节省大量开发资源,将精力集中在业务创新上。无论是大规模数据采集还是自动化测试,该平台都能提供可靠支持,让技术难题迎刃而解。平台接口文档清晰,对接步骤简单,适合各种规模的公司快速集成,真正做到省时省力。