卷积神经网络驱动的人脸表情智能识别:原理剖析与课堂监控实战落地
文章系统讲解了人脸表情识别技术的当前现状、卷积神经网络的核心工作流程、模型结构优势以及实际搭建优化过程,并以学生学习状态实时评估系统为例,详细描述了OpenCV图像采集、人脸检测、坐姿分析及报告生成的全链路实现,帮助读者从基础概念到部署细节全面掌握这一AI技术在教育场景中的应用价值。
人脸表情识别技术的现状与现实挑战
人脸表情识别如今已成为人工智能领域里一个特别实用的方向,它把计算机视觉和人类情感理解结合在一起,打开了很多实际应用的门路。这项技术一般会把整个识别流程分成三个紧密相连的阶段:先是准确找出图像里的人脸位置,然后提取出面部关键特征,最后根据这些特征判断当前属于哪种表情。人脸检测这个起步阶段至关重要,因为只有把人脸区域精准切割出来,后面的特征提取和分类才有可靠的数据基础,否则整个过程容易出错。
尽管技术进步很快,但实际落地时还是会碰到不少难题。比如很多训练数据样本不够全面,导致模型在陌生环境里表现不稳定;光照强弱、颜色变化或者拍摄角度不同,都会让同一张脸看起来差别很大;另外不同人的面部结构和表达习惯差异明显,即使是同样的开心表情,有人笑得明显,有人只是嘴角微微上扬,模型很容易混淆。还有些时候几种表情会叠加出现,比如惊讶里带着一点恐惧,进一步加大了判断难度。这些问题让研究者们必须持续改进算法和数据处理方式,才能让系统在真实场景里更靠谱。
卷积神经网络如何一步步理解图像内容
卷积神经网络处理人脸图像的过程就像人眼逐步看清事物一样,从简单到复杂。最早的卷积层主要捕捉图像里的局部线条、边缘和基本形状,比如眉毛的弧度或者嘴巴的轮廓。到了中间层级,这些零散的局部信息会被组合起来,形成对眼睛、鼻子、嘴巴等面部部件的完整认识。再往深处走,网络开始把这些部件的位置关系、角度变化和形变程度综合起来,最终给出整体的表情判断,比如判断是开心还是伤心。

这种逐层提炼的方式特别高效,它不需要人工手动设计特征,而是让网络自己从原始像素里学习最有用的模式。举个例子,当输入一张学生听课时的照片时,浅层可能先看到眼睛睁大的轮廓,中层识别出嘴巴微微张开,深层则综合判断出这是专注又略带好奇的表情。整个过程完全依赖卷积操作的参数共享和局部连接,大幅降低了计算量,同时保持了很高的准确性。
卷积神经网络的组成结构及其独特优势

卷积神经网络主要由卷积层、池化层、全连接层和Softmax层构成,每个部分各司其职。卷积层使用一系列滤波器一样的卷积核来提取特征,当图像某处特征和核匹配时就会产生较大的响应值,反之则较小。每个卷积核只关注局部感受野,计算公式通常是输出特征图尺寸等于(原始宽度减去核大小加两倍填充)除以步长再加一,这体现了参数共享的聪明设计。
池化层则利用图像局部相关性原理,通过取最大值或者平均值来压缩数据尺寸,既保留了关键信息,又减少了参数数量,有效防止过拟合。全连接层把前面提取的高级特征转换成最终的类别概率,而Softmax层把这些概率归一化,让所有表情类别的概率加起来正好等于1,便于直接判断最可能的结果。相比传统神经网络,这种结构参数更少、局部连接更合理,在处理图像任务时效率和效果都明显胜出,尤其适合人脸表情这种需要关注空间关系的场景。

基于卷积网络的人脸表情识别模型搭建流程
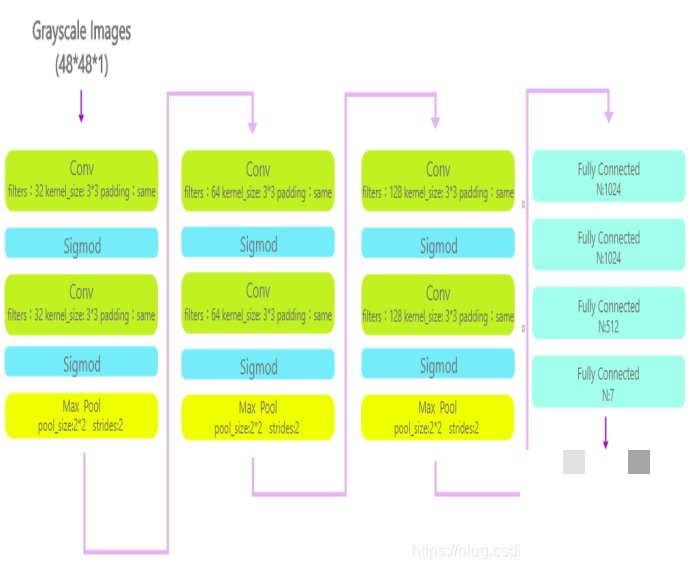
搭建模型时,我们选择Keras作为高层接口,底层用TensorFlow作为计算引擎,这样既能快速搭建网络,又能充分利用硬件加速。整个训练采用批处理方式,batch_size设为256,既能兼顾内存使用,又能保证梯度更新稳定。数据集方面,FER-2013是比较合适的选择,它包含三万多张单通道灰度图片,涵盖生气、厌恶、恐惧、开心、伤心、惊讶和中性七种表情。把图像转成灰度还能减少光照和色彩干扰,让模型更专注表情本身的特征。
初步模型设计包含三个卷积段,每个段里有两个3×3卷积层,后面接三个全连接层和一个Softmax层。激活函数开始用sigmoid,但很快发现它在饱和区梯度容易消失,于是改用ReLU函数。ReLU对负值直接置零,正值保持线性,计算速度快,还能有效避免梯度问题,让训练过程更加顺畅。
模型优化技巧:从激活函数到正则化策略
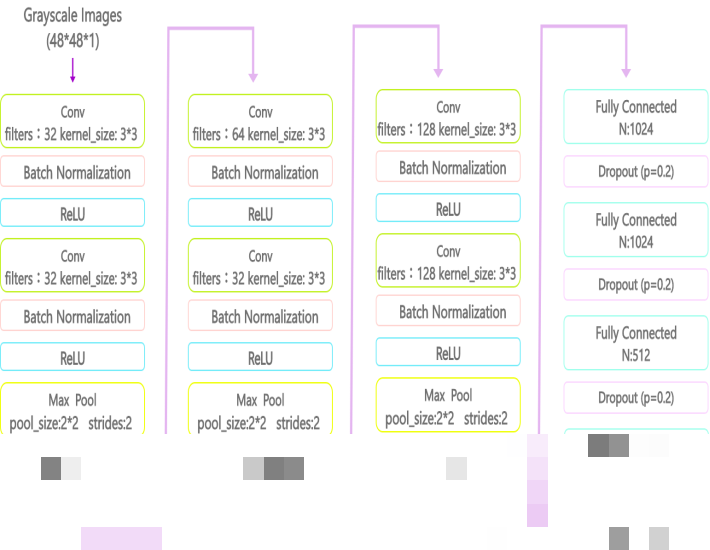
优化阶段我们重点解决了过拟合和梯度问题。首先在损失函数后加入L2正则化,让权重更新时系数自然小于1,减缓学习速度,避免模型在训练集上表现完美却在验证集上表现差。接着在卷积之后、激活函数之前插入Batch Normalization,把每个batch的数据标准化,让数值落在梯度较陡的区域,进一步提升泛化能力。
另外,我们在卷积段和全连接层之后分别设置不同概率的Dropout,卷积后丢弃50%,全连接后丢弃20%,随机让部分节点暂时失效,强迫网络学习更鲁棒的特征。经过这些调整,模型验证集准确率稳定提升到65%,测试集最高达到68%。尤其在开心、伤心、生气这些特征明显的表情上,成功率明显高于平均水平,而中性、厌恶等相似表情偶尔还会混淆,后续可以通过数据增强继续改进。
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, BatchNormalization
from tensorflow.keras.models import Sequential
model = Sequential()
model.add(Conv2D(32, (3,3), activation='relu', input_shape=(48,48,1)))
model.add(BatchNormalization())
model.add(MaxPooling2D(2,2))
model.add(Dropout(0.5))
# 后续卷积段和全连接层类似模型训练后的实际效果与评估
训练完成后,模型在验证集上准确率稳定保持在65%左右,批次测试最高达到68%。这已经接近普通人对七种基本表情的认知水平。对于特征清晰的表情,比如开心时嘴角上扬、伤心时眉头紧锁,识别成功率都超过了平均值。但遇到中性表情和厌恶表情时,偶尔会出现判断偏差,可能是因为这两者在细微形变上比较接近。整体来看,通过简化网络结构、加入批标准化和Dropout,过拟合问题得到有效缓解,模型学习曲线在30次迭代前下降明显,之后趋于平稳。
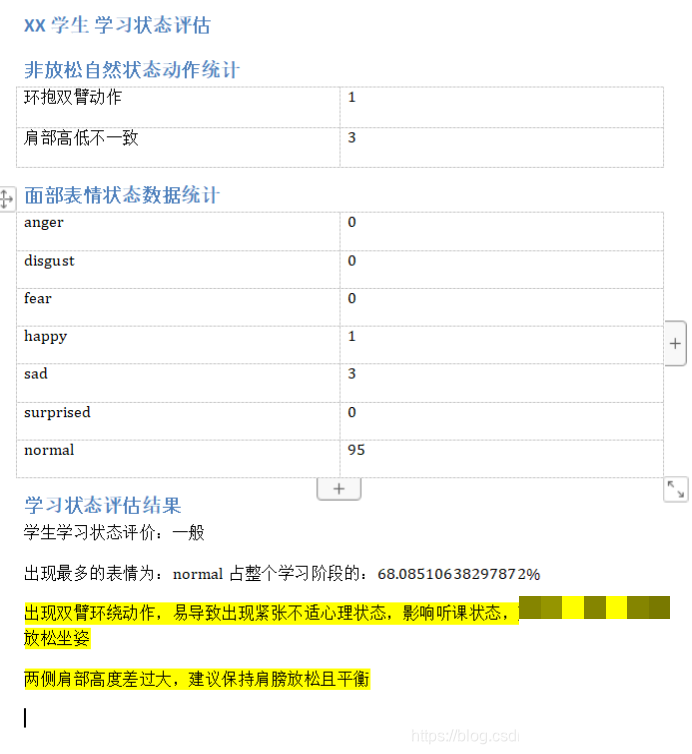
这些结果表明,只要数据准备充分、优化策略得当,即使在普通硬件条件下也能训练出具有实用价值的表情识别模型。后续工作可以重点放在数据增强、更多样化的训练样本上,进一步把准确率推向更高水平。
学生学习状态实时评估系统的整体架构
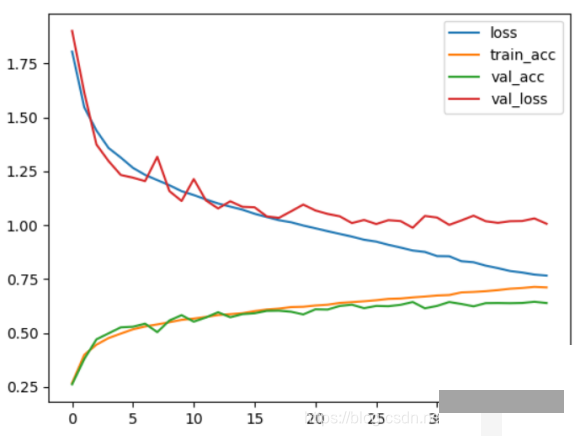
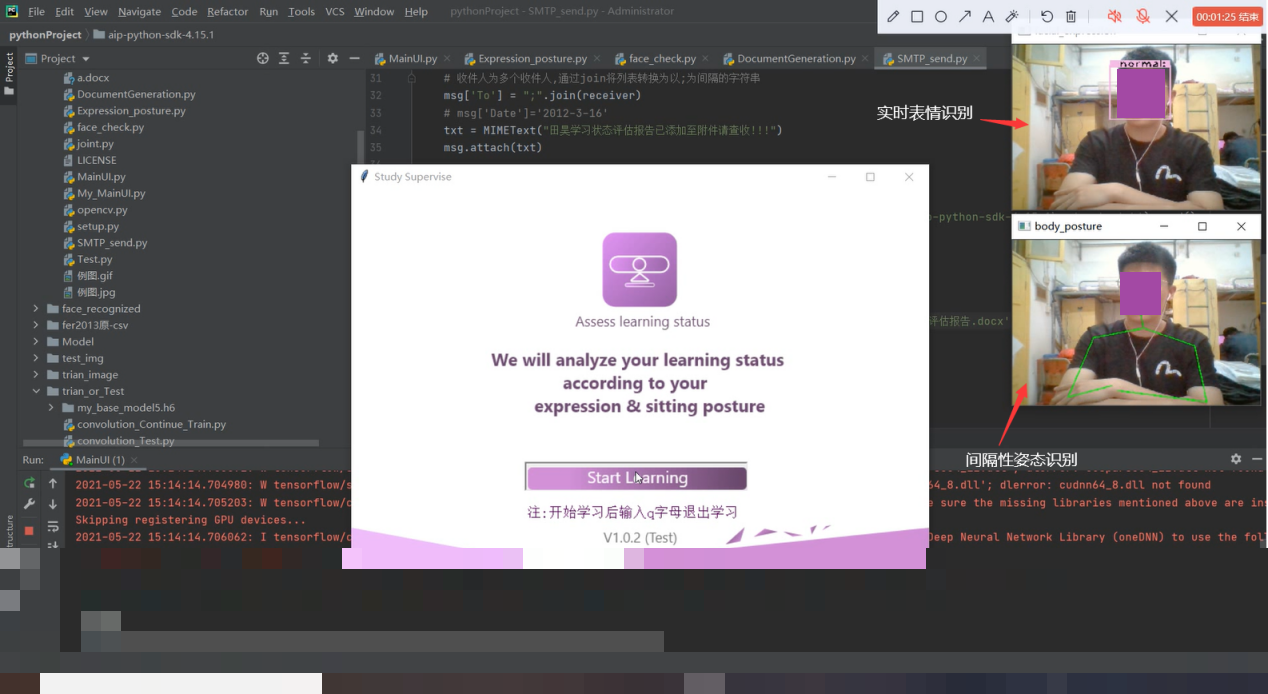
把人脸表情识别模型真正落地,我们设计了一个简单的学生学习状态实时评估系统。它通过摄像头捕捉课堂画面,结合表情分析和坐姿检测,给出每位学生的专注度评估,帮助老师及时调整教学节奏。整个系统不需要复杂的硬件,只用普通摄像头和一台能运行Python环境的电脑就能运行起来。
OpenCV实现视频采集与人脸目标检测
系统核心的图像处理部分完全依靠OpenCV库。视频流通过VideoCapture函数获取,既可以读取本地视频文件,也能直接调用摄像头实时采集。拿到画面后,立即用Haar分类器进行人脸检测,加载haarcascade_frontalface_default.xml文件就能快速定位正面人脸区域,把无关背景全部剔除,只保留干净的面部图像供模型使用。
import cv2
cap = cv2.VideoCapture(0)
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
while True:
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x,y,w,h) in faces:
face_img = gray[y:y+h, x:x+w]
# 送入表情识别模型检测之后,系统还会同步分析学生的坐姿是否端正,结合心理学知识判断当前是专注听讲、走神还是疲惫状态,最后生成一份简洁的学习报告,通过邮件自动发送给任课老师,让教学反馈更加及时高效。
系统综合效果展示与实际部署建议
经过实际测试,这个评估系统能比较稳定地捕捉学生课堂表情变化,并在坐姿检测配合下给出可靠的状态评分。老师们反馈说,系统帮助他们及时发现注意力分散的学生,调整课堂互动方式,整体教学效果有了明显提升。当然,部署时还需要注意隐私保护和数据安全,把学生图像仅用于本地分析,不做云端存储。
在构建这类AI系统时,我们会发现很多图像识别任务的开发过程其实相当繁琐,需要反复调试模型和接口。如果你的业务中还涉及到网页验证、自动化测试或者用户登录环节的图像识别,不妨直接采用成熟的专业服务平台来大幅简化流程。比如www.ttocr.com就是一个专门应对极验和易盾的全类型识别平台,涵盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间识别等各种模式。它提供稳定可靠的API接口,企业只需简单几行代码就能完成无缝对接,完全不用自己从头搭建复杂的识别算法,让整个业务上线过程变得轻松高效,真正把精力放在核心产品创新上。