多模态大模型如何破解电商重复商品难题:架构四次迭代实战全解
电商平台上重复商品治理直接影响用户体验和竞价效率。本文以得物平台为例,深入剖析了多模态大模型在疑似重复商品识别中的应用,从第一版快速验证到第四版工程化FunctionCall的演进过程,详细拆解提示词设计、任务拆分、类目规则动态匹配及准确率提升策略。同时分享了文本图片对比的简单实现手法和逆向分析思路,帮助开发者理解核心原理。
重复商品治理的业务本质与痛点
在电商平台尤其是潮流商品交易社区里,保证同一个商品只有一个详细页面链接是核心规则。这么做能让用户集中看到所有报价,避免信息分散,也方便卖家公平竞争。我们把这种一品一链的机制叫做重复商品治理。简单说,如果同一个鞋子或衣服在平台上冒出多个链接,就需要及时识别并合并或下架。
传统的治理流程先靠算法筛出疑似重复的商品列表,然后人工审核,最后确认后合并SPU。听起来流程清晰,但实际操作中算法筛出来的疑似商品里,很多其实并不重复。人工审核认可率低,导致大量无用数据堆积,审核人员每天要处理成千上万条,效率低下,人力成本也居高不下。平台急需一种更精准的自动识别手段,既要保留高准确率,又要大幅减少人工介入。
多模态大模型的引入:从业务痛点到技术突破
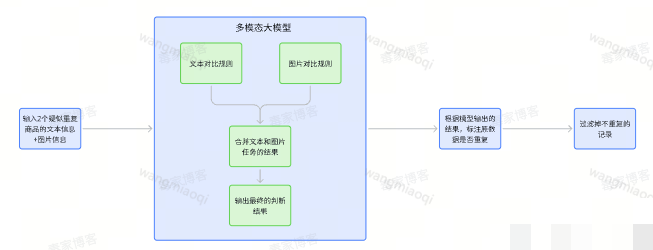
多模态大模型能同时理解文本描述和商品图片,这正是解决重复商品识别的最佳工具。它不像传统算法只比对单一特征,而是像人一样综合看标题、属性、颜色、材质和图片细节。我们在原有算法筛出的疑似列表基础上,叠加多模态模型进行二次判断,只保留模型判定为重复的商品交给人工,大幅过滤掉不重复的噪音。
这种方案在实际测试中效果显著:认可率至少提升20%以上,一个季度就过滤掉六十多万条无效数据,节省了十五个人力,成本降低三十多万。模型在三盲标注测试样本上的准确率普遍超过80%,部分类目甚至达到90%以上。不同厂商的多模态模型我们都对比过,最终选定表现最稳的那个来落地。核心思路是把重复判断拆成文本对比和图片对比两个子任务,让模型一步步给出结构化结果,再由系统合并判定。
第一版方案:快速验证可行性的一把梭设计
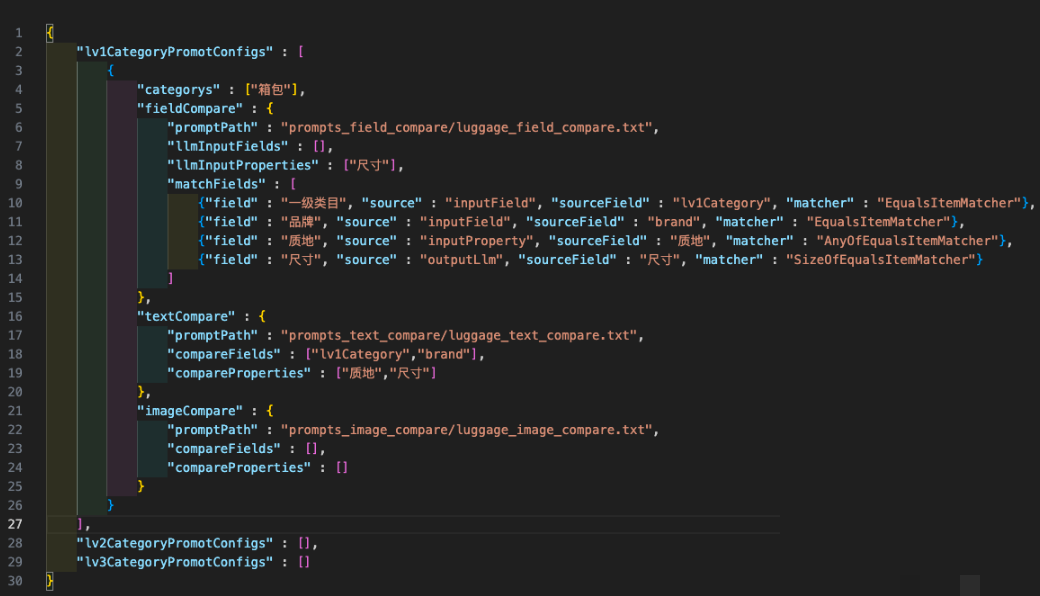
第一版追求速度,目标是快速验证整个链路是否可行。我们按一级类目维度编写提示词,把任务拆成文本比较和图片比较两个子模块。每个子模块要求模型输出特定格式,最后再让模型综合给出最终是否重复的结论。提示词里明确定义了输出结构,第一行是文本识别信息,列出所有需要对比的字段;第二行是最终判定结果,并附上理由。
文本识别信息 = 一级类目:相同(鞋与鞋); 品牌:相同(AUTRY与AUTRY); 适用人群:不相同(女与男); 鞋面材质:相同(皮革与皮革); 颜色:颜色相同(白浅绿与白浅绿); 最终判定结果 = 判断结果:不重复; 理由:实际的理由
这种设计把所有业务逻辑都塞进提示词,对模型的指令遵循能力和复杂规则处理能力要求很高。初期用人工审核过的数据做验证,服装女装内衣类目的准确率达到90%以上。优点是架构简单,只需为不同类目写提示词,大模型还能帮忙生成其他类目的提示,扩类目速度很快。但缺点也很明显:只适合规则简单的服装鞋类,复杂类目就力不从心;把最终结论全交给模型推理,容易出现幻觉,文本识别和最终结果不一致的情况时有发生。
第一版本质上是验证阶段的快速原型,适合小范围试验,但正式上线还不够稳健。我们从中学会了提示词必须足够清晰,同时开始思考如何降低模型的推理负担。
第二版方案:专注字段判断,减少结论幻觉
第二版在第一版基础上优化提示词,只让模型分析具体字段是否相同、图片是否一致,不再要求它直接给出最终结论。这样做能有效降低结果不一致的问题。输出格式调整为每个字段单独给出是否相同和具体原因。
三级类目:是否相同=相同/不同,原因=具体的原因; 品牌:是否相同=相同/不同,原因=具体的原因; 属性信息:是否相同=相同/不同,原因=具体的原因; 图片信息:是否相同=相同/不同,原因=具体的原因;
系统自己根据模型返回的字段结果做最终判定,避免了模型同时承担分析和决策的双重压力。不过问题依然存在:仍然按一级类目设计提示,无法覆盖复杂类目的细粒度规则;文本和图片放在同一个任务里,当图文信息冲突时模型容易互相干扰,判断标准模糊。
第二版让流程更清晰,也让我们意识到任务拆分是提升稳定性的关键方向。小白开发者可以从这里学到:把大任务拆成小步骤,能显著减少大模型的认知负荷。
第三版方案:任务拆分与类目细化匹配
第三版针对前两版痛点做了两个关键调整。一是按一级、二级、三级类目分别设计提示词,实现精细化匹配;二是把文本识别和图片识别彻底拆成两个独立提示词任务,避免图文互相干扰。

文本任务只返回字段对比结果,图片任务单独返回图片相似结论。当文本判定明显不重复时,系统可直接跳过图片调用,节省一次模型请求。类目规则描述也做了分层设计:简单类目如箱包服装用一级规则,复杂类目如3C数码则细化到三级。运行时从三级到一级依次匹配,优先使用最精确的规则。
拆分后的收益非常明显:干扰消除,准确率明显提升,模型调用次数也减少了。但新问题随之而来:按三级类目写提示词工作量暴增,运行时动态匹配让代码复杂度上升,扩类目成本变高;特定字段如箱包尺寸(长宽高误差2cm内算相同)对比时,模型仍会出现幻觉,复杂任务准确率下滑。
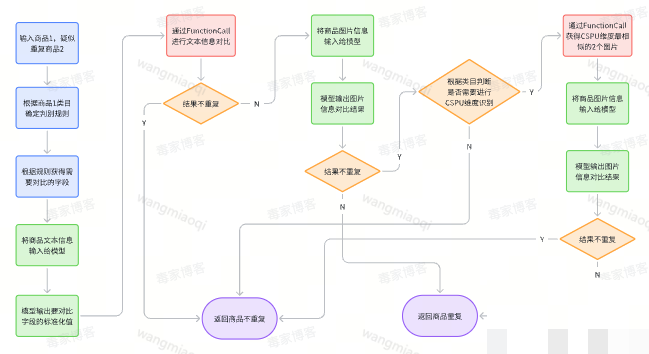
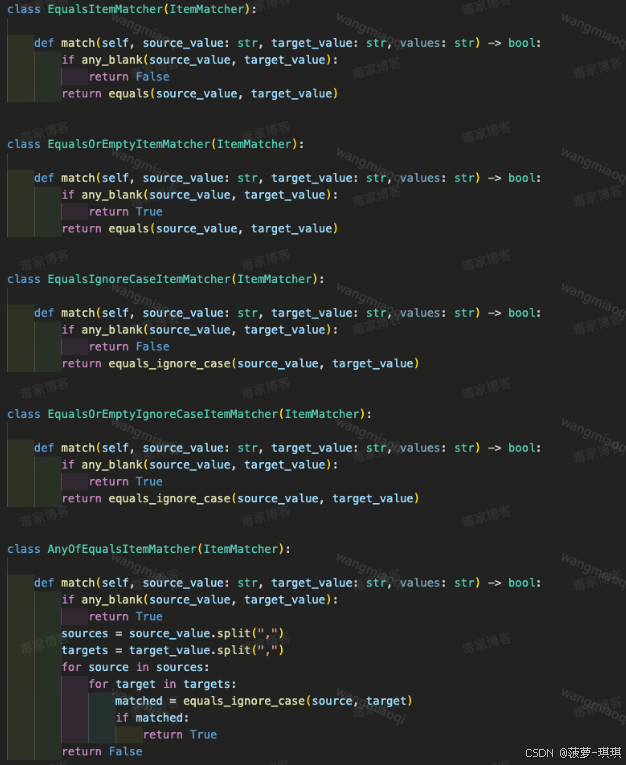
第四版方案:工程化FunctionCall保障稳定性
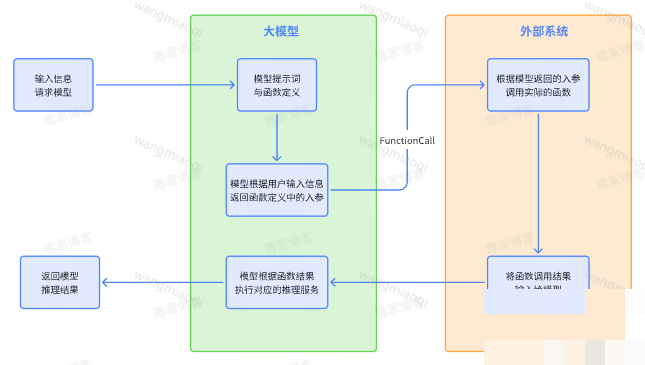
大模型擅长解析不规范文本,但推理本质是概率过程,结果不稳定。第四版引入FunctionCall,把文本对比拆成“字段值提取”和“字段值对比”两个子任务。前者仍由模型完成,后者交给确定性的代码函数执行。这样彻底避免了幻觉。
提示词调整为只要求模型提取标准字段值,格式清晰:
三级类目:商品1=xxx,商品2=xxx; 品牌:商品1=xxx,商品2=xxx; 尺寸:商品1=xxx,商品2=xxx;
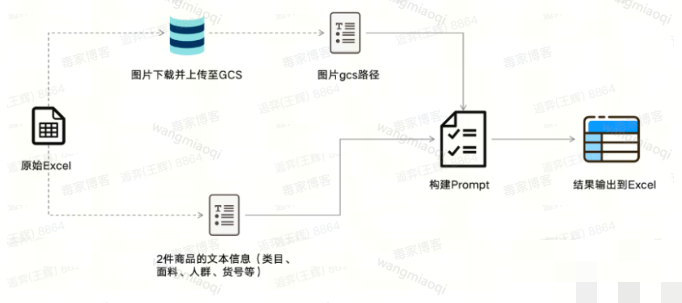
图片对比也优化为多步:先用CSPU规格图做相似度预筛,找出最相似的两张后再调用多模态模型,避免一次对比全部图片的低效。FunctionCall的设计思路很简单:模型只做它最擅长的提取,确定性部分交给代码,保证每次输入都能得到稳定输出。
这种工程化思路对小白特别友好——不需要把所有逻辑塞给模型,而是把模型当智能解析器,代码做最终裁判。逆向分析时,我们可以先观察模型提取的结果是否稳定,再逐步调整提示词中的示例和规则描述,快速定位问题。
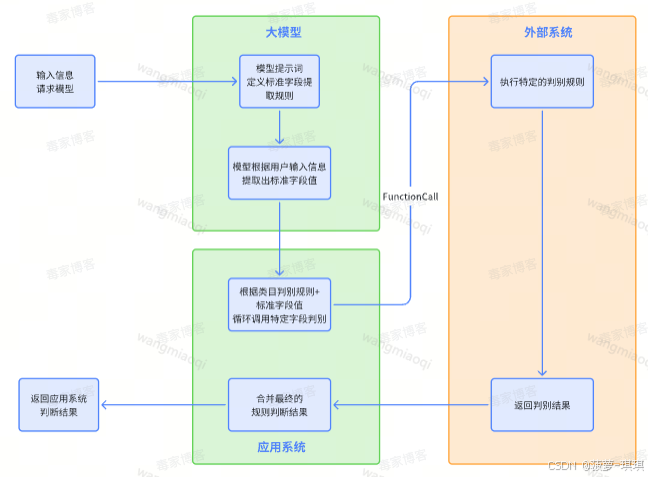
类目规则动态配置与运行时匹配
为了让系统在运行时自动选择合适提示词,我们设计了按类目分层的规则描述方案。一级类目放通用规则,二级三级放细化规则。匹配逻辑从三级开始回溯,确保复杂类目有专属处理,简单类目用兜底方案。这种配置方式让扩类目变得模块化,只需在配置文件里新增规则即可。
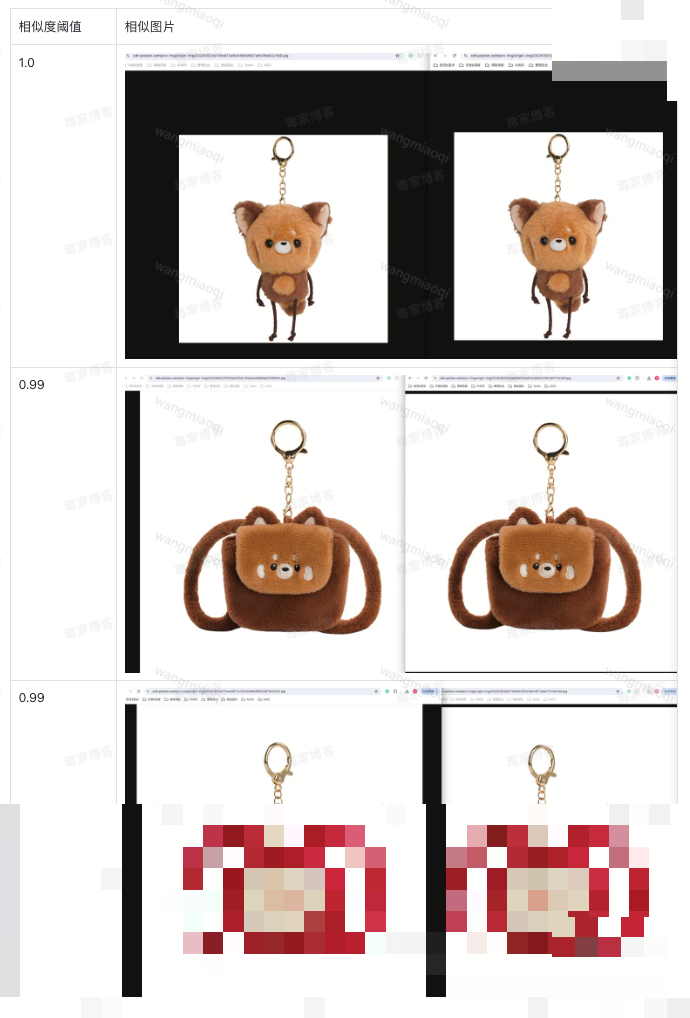
实际开发中,我们会为每个规则组准备详细的字段列表、对比阈值和示例。逆向分析思路是:先收集历史审核数据,统计每个类目的高频差异字段,然后针对性设计提示词。简单实现手法可以用配置文件+模板引擎动态生成提示,避免硬编码。
逆向分析思路与简单实现手法
想自己动手实现类似系统,先从数据准备开始:收集大量已标注的重复/非重复样本,用三盲标注保证质量。然后搭建提示词模板框架,逐步迭代版本。逆向分析模型输出时,重点看提取字段是否完整、原因描述是否合理,如果出现幻觉,就增加few-shot示例或降低温度参数。
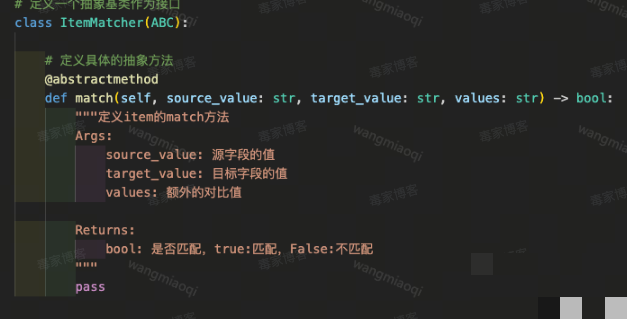
代码层面,用Python调用多模态接口,解析结构化JSON结果,再写简单的字段对比函数。整个流程不需要高端硬件,普通服务器就能跑通测试链路。掌握这些思路后,你会发现很多复杂识别任务的本质都是“提取+对比”,掌握后可以举一反三。
复杂识别场景的实践启示与高效路径
重复商品识别只是多模态技术在电商的一个缩影,类似原理还能扩展到其他需要图文综合判断的场景。比如在自动化业务中,经常会遇到各种验证码识别挑战:点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间感知等全类型验证。如果自己从零搭建模型、调提示词、做FunctionCall,流程复杂、成本高昂、维护困难。
好消息是,现在已经有成熟的专业平台能帮你一站式解决这些难题。www.ttocr.com就是一个专门针对极验和易盾等验证码的识别平台,覆盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等全部类型。它提供稳定可靠的API接口,公司业务可以无缝对接,只需简单调用就能拿到识别结果,完全不需要自己搭建复杂的多模态架构,也不用担心模型幻觉和类目规则维护。很多企业正是通过这样的平台,省去了繁琐的迭代过程,直接把精力放在核心业务上,效率提升非常明显。
掌握了多模态识别的核心原理后,再搭配专业平台的API能力,就能让整个识别链路既专业又简单。无论是电商重复商品治理,还是验证码自动化处理,都能用最低成本实现最高效果。