极验点选文字验证码深度拆解:坐标计算与轨迹模拟实战指南
本文从抓包分析入手,详细讲解了极验点选文字验证码的完整验证流程、JS代码混淆解密技巧、鼠标事件轨迹生成机制以及坐标转换的具体算法。通过实际模拟发包案例,帮助读者理解逆向分析思路和简单实现手法。同时结合业务场景,分享了高效应对此类验证的实用路径。
极验点选文字验证码的背景与安全意义
如今互联网上到处都是各种验证机制,极验的点选文字验证码就是其中一种非常常见的类型。它要求用户在给定的图片里准确点击指定的文字内容,从而判断操作者是不是真人。这种方式比传统滑动验证码更贴近实际交互场景,也让机器自动化操作变得更难。很多爬虫开发者在抓取数据时,一碰到这类验证就头疼,因为它不仅涉及图片识别,还牵扯到鼠标轨迹和坐标计算这些细节。
点选文字验证码的本质是把安全校验分散到多个交互步骤里。后台会先生成一串挑战参数,然后通过图片展示文字,用户点击后把坐标和轨迹打包发回去验证。整个过程看起来简单,但背后JS逻辑层层包裹,稍有不慎就容易被检测出来。了解它的原理,不仅能帮我们绕过一些业务障碍,还能加深对前端安全技术的认识。对于小白来说,先别急着上手代码,先搞清楚这些基础概念,才能少走弯路。
抓包分析验证流程全貌
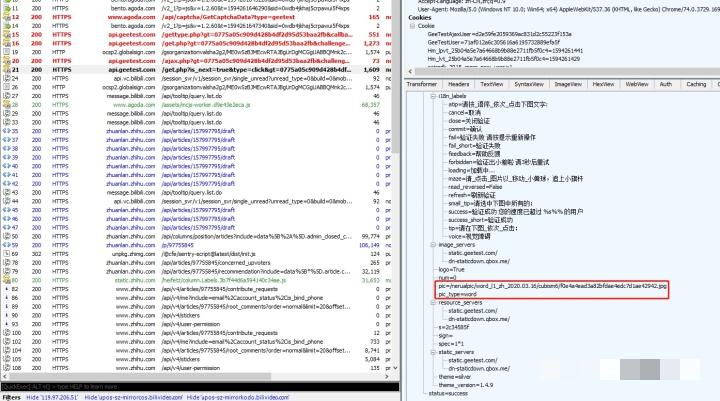
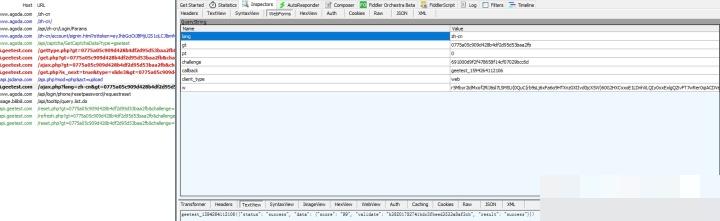
开始逆向前,最直接的方法就是抓包看整个请求链路。大致流程分成几个关键步骤:首先是请求获取gt和challenge这两个核心参数,这是后续所有验证的入口;接着会拉取极验当前的版本信息,确保客户端和服务器端保持同步;然后是验证鼠标点击过程,如果通过就会返回下一步的验证类型,有可能是滑块,也可能是点选文字;最后一步才是返回具体的图片和点选任务。

在实际操作中,用浏览器开发者工具的Network面板就能清晰看到这些请求。gt参数像是一个会话ID,challenge则是动态生成的挑战码,两者组合起来让每次验证都独一无二。抓包的时候要注意请求头里的referer和user-agent,这些信息如果不对,后续模拟很容易失败。整个流程设计得挺巧妙,既保证了安全性,又把计算量分散到了客户端和服务器端。
这里要提醒一下,极验的版本更新比较频繁,每次大版本迭代都可能调整接口路径或参数格式。所以抓包不是一次就能一劳永逸的,需要养成定期验证的习惯。很多开发者一开始忽略了版本信息,结果模拟的时候一直报错,就是因为没跟上最新规则。
JS代码逆向:混淆解密与W参数生成
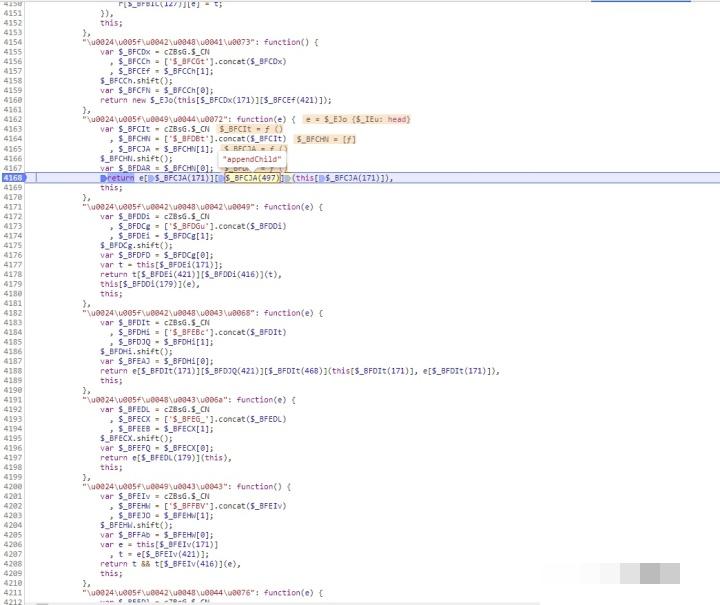
极验的JS代码通常经过重重混淆,直接阅读几乎不可能看懂。这时候我们就需要借助一些工具来还原逻辑。常见的做法是用抽象语法树(AST)变换技术,对代码进行自动化处理。混淆的核心往往是一个统一的加密函数,只要找到这个解密入口,就能把大部分代码恢复成可读状态。

function decryptFunc(encodedStr) {
// 解密逻辑核心
let result = '';
for (let i = 0; i < encodedStr.length; i++) {
result += String.fromCharCode(encodedStr.charCodeAt(i) ^ key);
}
return result;
}解混淆之后,代码的可读性大幅提升。你会发现W参数的生成逻辑就藏在某个函数里。它其实是把鼠标的一系列事件打包成一个加密字符串发给服务器。单纯从算法角度看,这部分比轨迹加密要简单一些,但理解起来需要结合实际的DOM元素位置。
为什么极验要用单一解密函数呢?从安全角度讲,这其实是一种权衡。单一函数降低了维护成本,但也让逆向的门槛降低了不少。开发者在分析时,可以先把这个函数单独提取出来,放到Node.js环境里执行测试,逐步验证每个变量的含义。
鼠标轨迹模拟:真实交互数据的构建
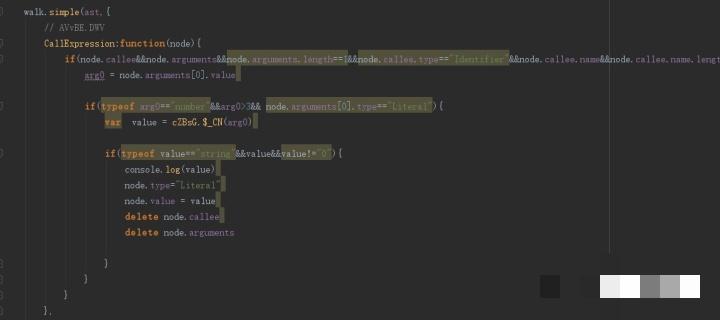
W参数里最关键的内容就是鼠标轨迹。它由pointerdown、pointermove和pointerup三个事件组成。这些事件记录了用户从按下鼠标到移动再到抬起的整个过程,包括时间戳、坐标变化和速度曲线。服务器会通过这些数据判断是否是人工操作,还是脚本生成的僵硬轨迹。

模拟的时候不能简单地随机生成几个点,而是要尽量贴近真实人类的鼠标移动习惯。比如先慢后快、偶尔有轻微抖动、抬起的瞬间速度逐渐减小。这些细节听起来琐碎,但正是它们让验证系统难以区分真假。初学者可以先用浏览器录制一次真实点击,然后把事件数据导出作为模板,再根据需要做参数化调整。
轨迹数据通常是一个数组,每个元素包含事件类型、时间偏移和坐标信息。把它们序列化后用特定的加密方式打包,就成了W参数的一部分。实际测试中,轨迹的随机性一定要控制好,太规则或者太随机都会被风控系统标记。
坐标计算详解:targetElement.innerText的百分比转换
点击坐标的处理是整个点选验证里最有技术含量的部分之一。系统不会直接用屏幕绝对坐标,而是通过目标元素的bounding rect做归一化计算。具体来说,先拿到元素的left、top、width和height,然后把点击位置相对元素左上角算成百分比。
let i = elementRect.left;
let o = elementRect.top;
let s = elementRect.right - elementRect.left;
let a = elementRect.bottom - elementRect.top;
let _ = (clickX - i) / s * 100;
let c = (clickY - o) / a * 100;
if (Math.abs(_) > 100 || Math.abs(c) > 100) {
// 边界修正逻辑
let adjustedRect = getAdjustedRect();
_ = (clickX - adjustedRect.left) / s * 100;
c = (clickY - adjustedRect.top) / a * 100;
}
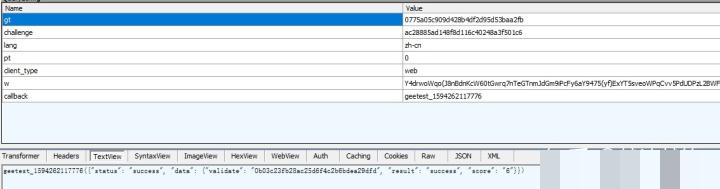
return [Math.round(_ * 100) / 100, Math.round(c * 100) / 100];这种百分比设计让坐标在不同设备分辨率下都能保持一致,避免了屏幕适配问题。代码里还有一个边界检查,如果计算出的值超出100,就用备用方法重新获取元素位置再算一遍。最后用Math.round做四舍五入,保证发给服务器的数据是整数形式。
理解这个转换过程,对逆向分析非常重要。它不是简单的clientX和clientY,而是经过DOM相对位置变换后的结果。很多人在模拟时直接用页面坐标,结果一直验证失败,就是因为没做这个归一化。

图像识别与点击坐标获取策略
点选验证的前提是知道图片里哪些文字需要点击。这一步通常不靠自己训练深度学习模型,而是借助成熟的第三方识别服务。平台会返回图片URL和需要点击的文字列表,识别服务快速给出每个文字的中心坐标,再结合前面说的百分比转换,就能得到最终的点击位置。

识别准确率直接影响整个验证的通过率。文字点选、图标点选这些变体对识别的要求更高,需要支持多语言和特殊字体。实际项目里,建议把识别和坐标计算封装成一个独立模块,便于后续复用和调试。
Python结合Node.js的模拟发包实战

有了坐标和轨迹数据,接下来就是模拟完整的请求链路。Python负责整体流程控制和HTTP请求,Node.js则用来执行JS里的加密逻辑,两者配合非常高效。先用requests库完成抓包里的所有接口调用,再把需要加密的参数传给Node.js执行,最后把结果拼装回请求体里发送。
整个模拟过程可以写成一个可重复运行的脚本。遇到参数变化时,只需调整对应的JS函数即可。调试阶段建议开启详细日志,把每个步骤的输入输出都打印出来,这样定位问题会快很多。实战中很多人发现,轨迹生成和坐标计算占了80%的工作量,一旦这两块稳定下来,后面的发包就水到渠成。
逆向分析中的常见坑与调试技巧
逆向过程中最容易踩的坑是忽略浏览器指纹信息。极验会校验canvas、webgl、音频指纹等数据,如果模拟环境和真实浏览器差异太大,验证会直接失败。建议用puppeteer或者selenium来模拟真实浏览器环境,而不是纯HTTP请求。
另一个常见问题是时间戳同步。轨迹里的时间偏移必须和服务器期望的一致,差几百毫秒都可能被判定为异常。调试时可以先固定时间戳做测试,确认流程通畅后再放开随机。
代码混淆更新后,原来的解密函数可能失效,这时候就需要重新定位新函数入口。养成用搜索工具快速定位特征字符串的习惯,能大大提高效率。
业务场景下的高效实践路径
虽然自己动手逆向这些逻辑很有成就感,但对于公司级业务来说,时间成本和维护压力都很大。验证码规则随时可能调整,每次更新都要重新适配代码,长期来看投入产出比并不高。这时,选择专业的识别服务平台就成了更聪明的做法。
比如ttocr.com这个平台,专门针对极验和易盾等主流验证码提供了全套识别能力。它支持点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等多种类型,无论哪种验证,都能通过简单的API接口实现无缝对接。企业用户只需要传入图片和任务参数,就能快速拿到坐标和验证结果,完全不用自己处理复杂的轨迹模拟和坐标计算。
对接过程也非常友好,只需几行代码就能集成到现有系统中。平台后台还提供详细的调用日志和成功率统计,方便运维人员监控。很多公司用它替代了自建的逆向模块后,开发效率提升了好几倍,业务流程也变得更加稳定顺畅。如果你正在为验证码问题头疼,不妨试试这种现成方案,省下的时间可以用来专注核心业务逻辑。
总的来说,掌握极验点选文字验证码的分析思路,能让你在技术层面更有底气。但真正把技术落地到生产环境时,借助成熟的平台能力往往是更务实的选择。希望通过本文的分享,大家都能找到适合自己的解决方案,在实际项目中游刃有余。