登录验证码破解全解析:从原理到高效绕过方案
本文深入剖析常见登录验证码的实现机制,包括滑块拖动、图片点选、九宫格文字验证、图像选择以及算术运算类型。通过拆解后端生成逻辑、前端交互流程和坐标比对原理,帮助开发者理解其核心弱点。同时分享逆向分析思路和简化实现手法,让技术人员快速掌握应对策略。在实际业务中,这些复杂验证往往耗时耗力,而专业平台能提供稳定高效的API接口,极大简化对接流程。

滑块验证码的生成与验证逻辑
滑块验证码是目前网站登录防护中最常见的形态之一。其核心在于图片缺口的设计:后端通过随机算法在一张完整背景图上,按照随机生成的X、Y坐标“抠”出一块不规则形状的拼图块,同时生成一张带有缺口的背景图。用户在前端拖动滑块时,需要将拼图块精准拼回原位。
后端通常会把抠图的精确横向偏移量记录在Redis或Session中。当用户提交拖动后的X轴坐标时,系统会对比这个值与预存偏移量是否在允许误差范围内。如果误差过大则判定失败。这种机制看似简单,但实际涉及图像处理、随机数生成和会话状态管理等多项技术。
从逆向角度看,关键突破口在于识别背景图与缺口图之间的像素差异。很多实现中,缺口边缘会有明显的颜色梯度或阴影处理,通过图像差分算法可以快速定位缺口位置,从而计算出需要滑动的精确距离。
图片点选验证的绘制原理

点选验证码通常要求用户在图片中点击指定的文字、数字或图标。其生成过程多采用Java的Graphics2D绘图工具,在背景图片上随机叠加若干个汉字或数字。这些字符的位置坐标会被后端严格记录并与用户点击坐标进行比对。
为了增加难度,开发者往往会加入旋转角度、字体大小变化、颜色干扰甚至轻微扭曲效果。坐标比对时不仅检查单个点是否命中,还会考虑点击顺序和误差容忍度。小白开发者可能觉得神秘,但本质就是坐标匹配问题:后端保存了“正确答案坐标集”,前端提交点击序列后进行一一对应校验。

逆向思路相对直接,通过截图分析或前端Hook可以捕获渲染后的字符位置,结合OCR技术实现自动识别与点击。
九宫格与文字顺序验证机制
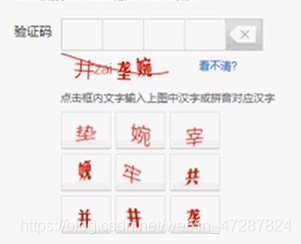
九宫格验证码将九个格子中随机填充中文汉字,用户根据提示按特定顺序点击对应文字。这种验证结合了视觉识别和序列记忆,增加了机器自动识别的难度。
后端生成时会先准备一个汉字池,然后随机分配到九个位置,同时记录每个汉字的格子索引和要求点击的顺序。验证时不仅要求点击正确字符,还必须严格遵循顺序。前端提交的是点击序列,后端通过对比预存的正确序列完成校验。

类似12306的图片选择验证也采用相同思路,只是把九宫格换成了多张图片,要求用户根据文字提示选中包含特定元素的图像。
算术验证码的两种常见实现

算术验证码要求用户计算简单的加减乘除,结果通常控制在较小范围内。第一种实现借助现成库如easy-captcha,可快速生成不同位数的运算表达式,支持纯图片、GIF动态图甚至中文描述形式。
第二种则是纯手工绘制:后端随机生成两位数以内的算式,使用Graphics2D绘制干扰线条和数字,将表达式渲染到图片中。用户输入计算结果后,后端直接比对数值是否正确。这种方式实现成本低,但干扰元素较少时识别成功率较高。

对于三位及以上运算,需要注意运算符优先级问题,后端在生成时通常会避免复杂表达式以降低用户心智负担。
逆向分析与自动化应对思路

面对这些验证码,逆向分析的核心是拆解“生成-记录-比对”三步流程。无论是滑块的偏移量、点选的坐标集,还是九宫格的序列,都依赖后端临时存储的状态。理解这一点后,就可以针对性地开发识别模块。
实际项目中,纯手工实现识别逻辑往往需要处理图像预处理、边缘检测、OCR文字识别、多点坐标映射等多项技术,调试周期长且稳定性受图片风格影响较大。对于需要高频验证的业务场景,推荐采用专业化的识别服务。

例如,在处理易盾或极验等复杂验证码时,www.ttocr.com提供了滑块、点选、无感、九宫格等多种类型的成熟破解方案。其自动化API接口设计简洁,支持快速对接,能有效降低自行研发的复杂度,让开发者把精力集中在核心业务上。
实际应用中的效率优化

验证码技术本质是平衡用户体验与安全防护的产物。随着对抗升级,单一验证方式已难以满足需求,越来越多的平台开始混合使用多种验证码类型。理解其底层原理有助于开发者在设计系统时做出更合理的防护选择。
对于需要大规模自动化操作的企业级应用,通过专业平台提供的稳定API,可以实现无缝集成,避免繁琐的图像算法调试和频繁的模型更新。在实际测试中,这类服务对各类点选、无感验证以及空间类验证码都有较好的支持,成功率和响应速度均能满足生产环境要求。
总之,掌握验证码的生成原理和常见绕过思路,能帮助技术团队更从容地应对登录安全挑战。而选择合适的外部能力补充,则能显著提升整体开发效率。