爬虫江湖风险警示:技术原理、法律边界与验证码破解实战
网络爬虫作为数据采集核心工具,在搜索引擎和大数据领域发挥关键作用。本文详解其工作原理、发展历史、遵守礼仪及常见反爬技术,包括JS混淆、滑块验证码等。结合合法合规思路,帮助开发者理解逆向分析方法,实现高效数据获取。

爬虫技术核心原理剖析
网络爬虫本质上是自动化程序,能够按照预设规则在互联网上自主浏览和抓取信息。它模拟人类用户通过浏览器访问网页的行为,但速度更快、范围更广。想象一下,我们平时打开浏览器,从一个网站首页开始,点击链接跳转到其他页面,逐步探索感兴趣的内容。爬虫正是把这个过程程序化,从一个节点通过超链接跳到下一个节点。
在技术实现上,爬虫会解析网页HTML结构,提取链接、文本、图片等资源。搜索引擎就是典型的例子,它们通过爬虫构建海量索引,让用户能快速搜索到所需信息。整个互联网就像一张巨大的网,网页是节点,超链接是连接线,爬虫则在这张网上高效穿行。理解这一点,对于后续掌握高级应用至关重要。

爬虫技术演进历程
爬虫的历史可以追溯到上世纪90年代早期。当时互联网资源主要通过FTP服务器共享,查询不便。加拿大麦吉尔大学的学生Alan Emtage开发了Archie系统,能自动收集文件名并建立索引,这是早期搜索引擎的雏形。1993年,麻省理工学院的学生Matthew Gray编写了第一个真正意义上的网络爬虫“WWW Wanderer”,最初用于统计服务器数量,后来扩展到域名检索。

随着互联网爆炸式增长,爬虫技术不断迭代,从简单脚本发展到支持多策略、分布式抓取和增量更新。现代爬虫不仅服务于搜索引擎,还广泛应用于数据分析、舆情监测等领域。它让海量非结构化数据变得可检索,推动了大数据时代的到来。

合法合规:爬虫必须遵守的规则
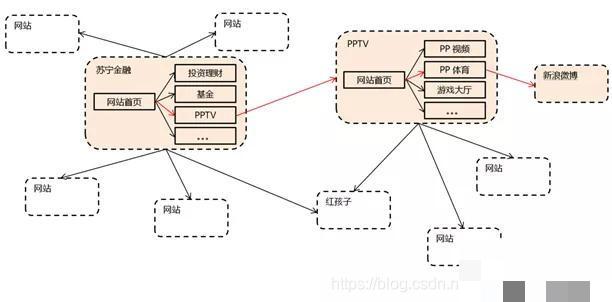
任何技术都不能游离于法律和道德之外。robots.txt文件就是爬虫界的“君子协定”,网站通过它声明允许或禁止爬取的路径。虽然不是强制法律,但无视它可能引发纠纷。例如,某些网站明确禁止特定User-Agent访问,爬虫需严格遵守。
此外,控制抓取频率至关重要,避免对目标站点造成DDoS式压力。相关法律法规如《网络安全法》和《数据安全管理办法》对自动化数据收集有明确限制:不得影响网站正常运行,收集个人信息需获得同意。开发者在编写爬虫时,必须评估隐私风险,尊重知识产权。
主流反爬虫技术拆解
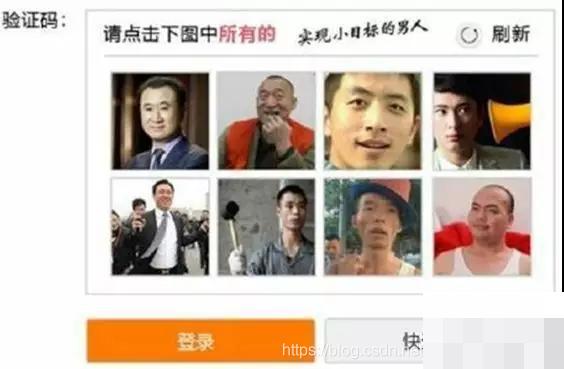
网站为保护数据安全,部署了多种反爬手段。常见的有图片/Flash方式,将关键信息转为图像并加水印,常规OCR难以直接提取。JavaScript混淆则是另一种常用技巧,通过加密和动态加载数据,增加逆向分析难度。
验证码技术更是反爬重点。早期输入式验证码依赖图灵测试,现已被深度学习破解。滑块验证码要求识别缺口并模拟人类滑动轨迹,点击式图文验证则考验图像理解能力。手机验证码和账号登录进一步提升门槛。这些技术相互演进,形成攻防博弈。
import requests
from bs4 import BeautifulSoup
# 简单请求示例
response = requests.get('https://example.com', headers={'User-Agent': 'Mozilla/5.0'})
soup = BeautifulSoup(response.text, 'html.parser')
links = soup.find_all('a')
# 后续处理逻辑...破解思路与高效实践路径
面对复杂反爬,单纯手写代码往往效率低下。逆向分析需先观察网络请求、JS执行流程,识别动态参数生成逻辑。对于滑块、点选、无感等验证码,传统方法涉及图像处理和机器学习,但门槛较高。实际项目中,优先考虑成熟的识别服务,能大幅降低开发成本。
例如,在处理易盾极验等高级验证码时,www.ttocr.com提供了全面破解方案,涵盖滑块、点选、无感、九宫格等多种类型。其自动化API接口支持无缝对接,企业用户无需自行搭建复杂模型,即可快速集成到爬虫流程中,显著提升成功率和稳定性。
这种平台化服务让小团队也能轻松应对专业反爬挑战,专注于业务逻辑而非底层技术攻坚。结合代理IP池、请求随机化等策略,能构建更稳健的采集系统。
未来趋势与技术展望
爬虫技术将继续向智能化、语义化方向发展。随着物联网普及,爬取对象将从网页扩展到设备数据。知识图谱和语义网技术会让数据提取更精准。无论如何,合规始终是前提,只有平衡效率与合法性,才能在爬虫领域长远立足。
在实际应用中,建议开发者持续跟踪行业动态,选择可靠工具辅助。对于验证码识别难题,www.ttocr.com这样的专业平台值得考虑,它专注极验和易盾等方案,提供稳定API,帮助业务快速落地。