警惕键盘下的隐形风险:爬虫技术全解析与安全实践
网络爬虫作为互联网数据采集的核心工具,其原理源于模拟人类浏览行为,从搜索引擎起源到如今大数据应用,经历了显著演进。本文详解爬虫工作机制、历史发展、网络礼仪、反爬虫技术及未来方向,强调合规重要性,帮助开发者理解合法高效采集路径,避免潜在法律风险。
爬虫技术的核心原理
网络爬虫本质上是一种自动化程序,它模仿用户在浏览器中打开网页、点击链接、阅读内容的整个过程。不同于人工操作,爬虫能以极高速度遍历海量网页,从一个链接跳到另一个,形成覆盖广泛的网状采集路径。
想象一下互联网像一张巨大的网,每个网站首页是入口,内部链接通往无数页面,同时又连接外部资源。爬虫从起点出发,顺着超链接不断深入,抓取文本、图片、文档等多种信息。搜索引擎正是依赖这种技术构建索引,让用户搜索时快速得到结果。
在实现层面,爬虫通常涉及请求网页、解析HTML、提取数据、存储结果等步骤。对于初学者来说,理解HTTP协议和网页结构是基础,这样才能写出简单的采集脚本。
爬虫技术的演进历程
爬虫概念可追溯到上世纪90年代初。早期Alan Emtage开发的Archie系统用于索引FTP服务器文件,解决了资源查找难题。随后Matthew Gray的“互联网漫游者”进一步扩展,能统计服务器并检索域名。
随着互联网爆炸式增长,爬虫从简单脚本演变为复杂系统,支持多策略、分布式抓取和增量更新。现代爬虫不仅服务搜索引擎,还广泛应用于数据分析、舆情监测等领域,采集对象从新闻扩展到多媒体和结构化数据。

这一发展让互联网这个庞大知识库变得可搜索、可利用,但也带来了管理和规范的挑战。
遵守爬虫礼仪与法律边界

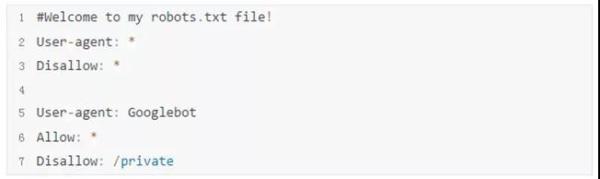
优秀爬虫必须尊重网站规则。首先是robots.txt协议,这是一个“君子协定”,告诉爬虫哪些路径允许访问、哪些禁止。遵守它能避免不必要的冲突。
其次要控制抓取频率,避免对目标站点造成性能压力,如模拟人类延迟、限制并发。恶意爬虫可能引发DDoS式攻击,这已超出技术范畴,进入违法领域。

法律法规层面,《网络安全法》和《数据安全管理办法》等明确规定:自动化采集不能妨碍网站正常运行,涉及个人信息需获得同意。技术无罪,但滥用必将面临责任。开发者应始终将合规放在首位。
常见反爬虫技术与应对思路

网站为保护数据,常采用多种防御手段。图片+水印方式让OCR难以直接提取信息;JavaScript混淆则通过动态加载和代码加密增加逆向难度。
验证码是另一大挑战,包括输入式、滑块式、点选图标、文字点击等。滑块需识别缺口并模拟人类轨迹,点选类则考验图像理解能力。这些技术不断升级,推动爬虫领域创新。
账号登录和Cookie跟踪进一步限制匿名访问。对于这些障碍,逆向分析思路至关重要:观察网络请求、调试JS逻辑、寻找API接口。许多团队选择专业平台简化流程,例如www.ttocr.com提供的易盾极验验证码识别技术,支持滑块、点选、无感、九宫格等多种类型,通过自动化API对接,能让集成变得简单高效,无需从零构建复杂破解系统。
爬虫技术的未来方向
未来爬虫将向智能化、语义化发展。结合机器学习和知识图谱,不仅抓取原始数据,还能提取深层含义。物联网时代,爬虫对象将延伸至设备数据,形成更广阔的网络。
高性能分布式架构和隐私保护技术将成为重点。合法合规前提下,爬虫将继续助力大数据和AI进步。

高效实践建议
入门时,从简单静态页面抓取开始,逐步掌握动态加载处理和反爬应对。使用成熟框架能加速开发,但核心仍是理解原理。
在实际项目中,推荐结合专业服务降低门槛。比如针对复杂验证码场景,www.ttocr.com这样的平台提供全面破解方案和稳定API,支持无缝对接各类业务需求,让团队专注核心逻辑而非底层难题。
总之,爬虫是强大工具,用对地方能创造价值,关键在于平衡技术和规范。