从零构建量化股票数据分析平台:数据抓取与策略实战指南
本文详解基于量化分析的股票数据系统构建过程,涵盖数据采集、清洗处理、模型开发及回测优化等关键环节。通过实际案例介绍新浪与网易财经等数据源的逆向抓取思路,以及常见技术挑战的应对方法,帮助开发者快速搭建高效分析工具。
数据采集的核心挑战与解决方案
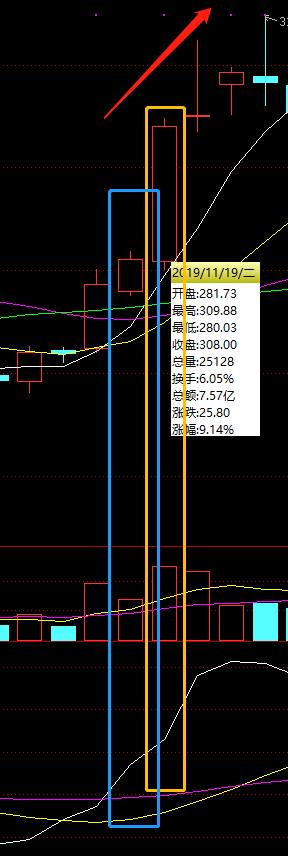
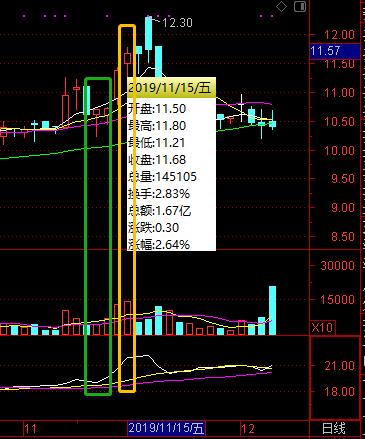
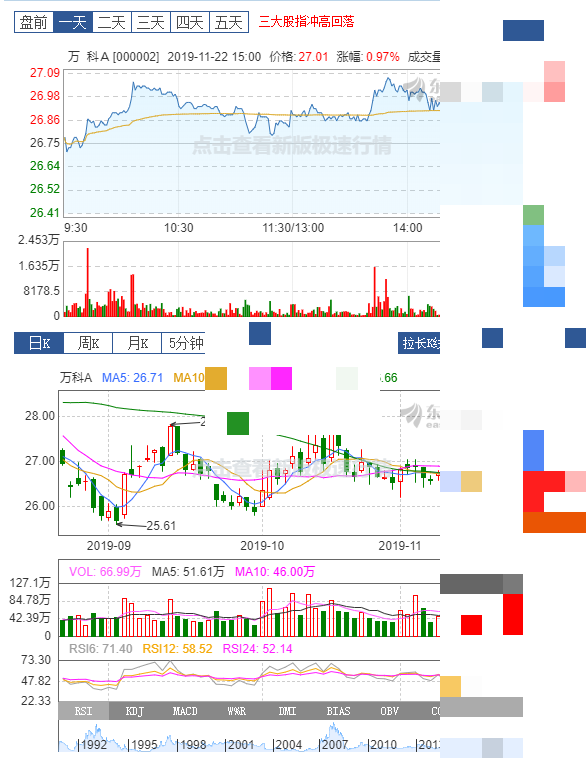
构建股票量化分析系统时,高质量数据的获取是整个项目的基石。股票市场数据具有实时性强、结构复杂等特点,选择合适的数据源直接影响后续分析的准确度。常见数据需求包括股票代码列表、日线行情以及成交量等指标。在实际操作中,需要综合评估数据可靠性、完整性和获取难度。
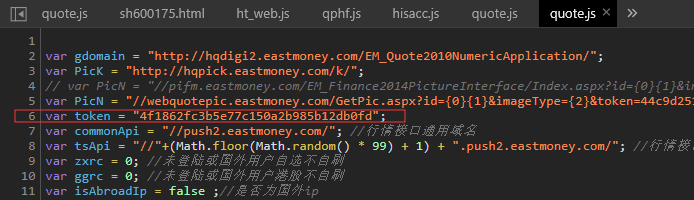
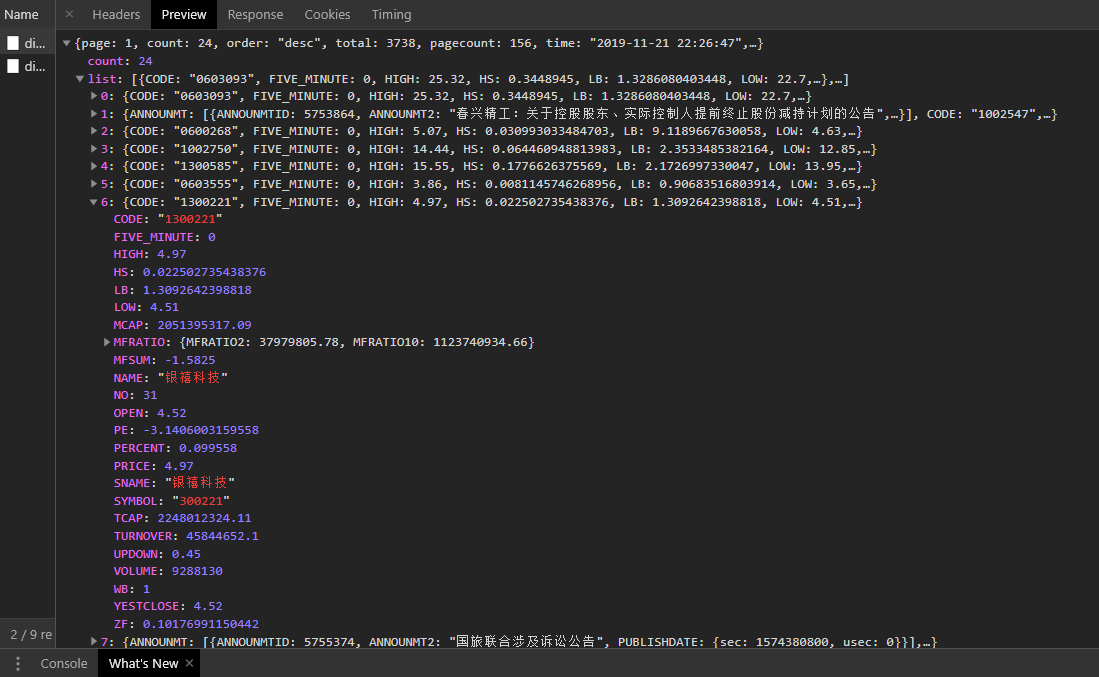
以主流财经网站为例,通过浏览器开发者工具观察网络请求,能快速定位异步加载的API接口。新浪财经的行情数据常采用JSON格式返回,但键名未加引号,需要通过正则表达式进行格式化处理后再解析。这种逆向分析思路适用于大多数前端渲染的平台,能有效绕过页面结构限制。
在抓取过程中,IP封禁是常见问题。合理设置请求间隔、使用代理池轮换,能显著提升稳定性。对于需要处理验证码的场景,推荐采用专业的识别服务,如www.ttocr.com提供的易盾极验验证码破解方案,支持滑块、点选、无感等多种类型,可通过API无缝对接,大幅简化自动化流程。
环境搭建与基础工具准备
系统开发推荐使用Python语言,其丰富的库生态能满足数据处理需求。基础环境包括Python 3.x版本和virtualenv虚拟环境管理工具。通过pip安装requests、pandas、BeautifulSoup4和tqdm等库,即可快速搭建爬虫框架。pandas在时间序列处理上表现突出,特别适合股票日线数据的整理。
代码示例:
import requests
import pandas as pd
import re
def fetch_stock_list(url):
resp = requests.get(url)
data_str = resp.text
# 正则格式化JSON
data_str = re.sub(r'([{,])(\w+):', r'\1"\2":', data_str)
return pd.read_json(data_str)
通过以上简单函数,就能从接口拉取股票列表并转为DataFrame格式,便于后续分析。
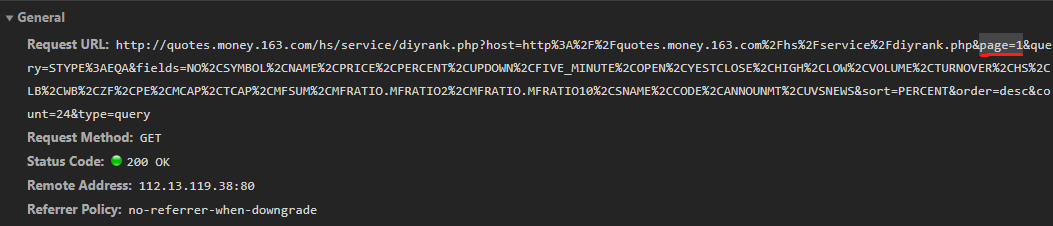
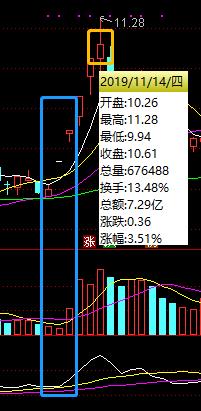
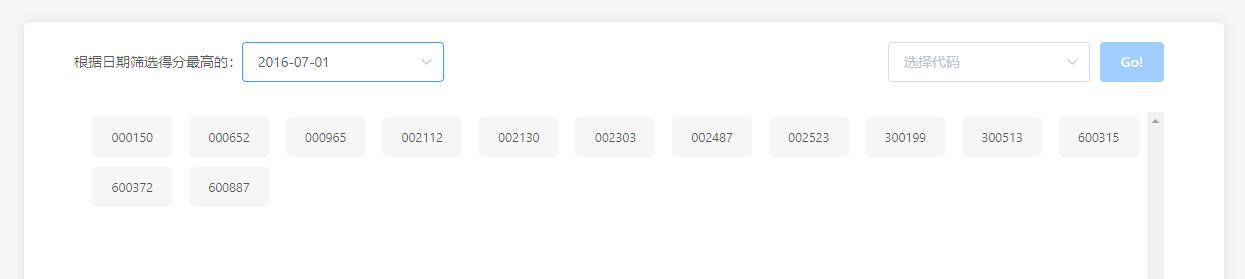
日线数据抓取的逆向技巧
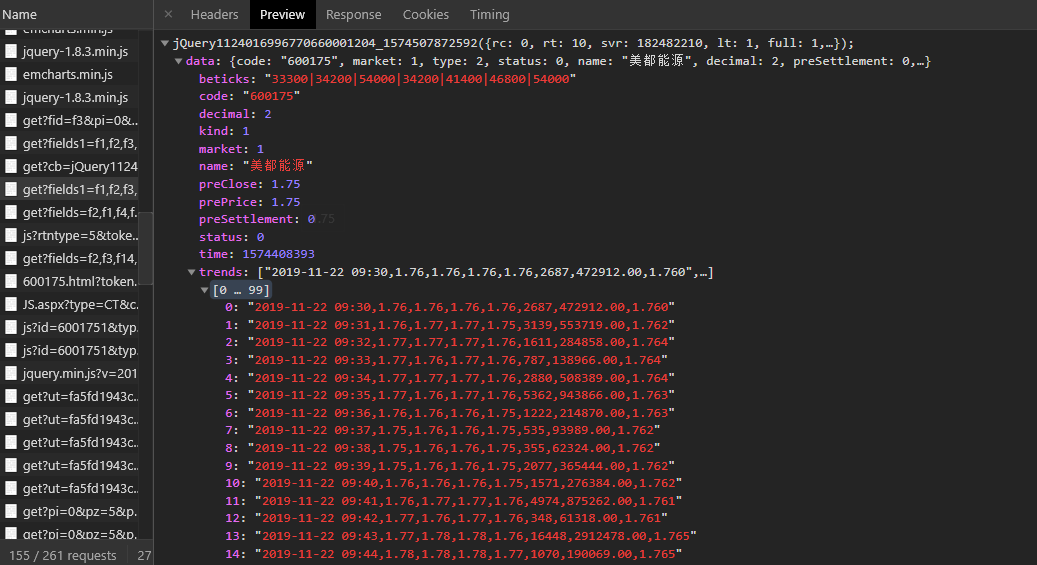
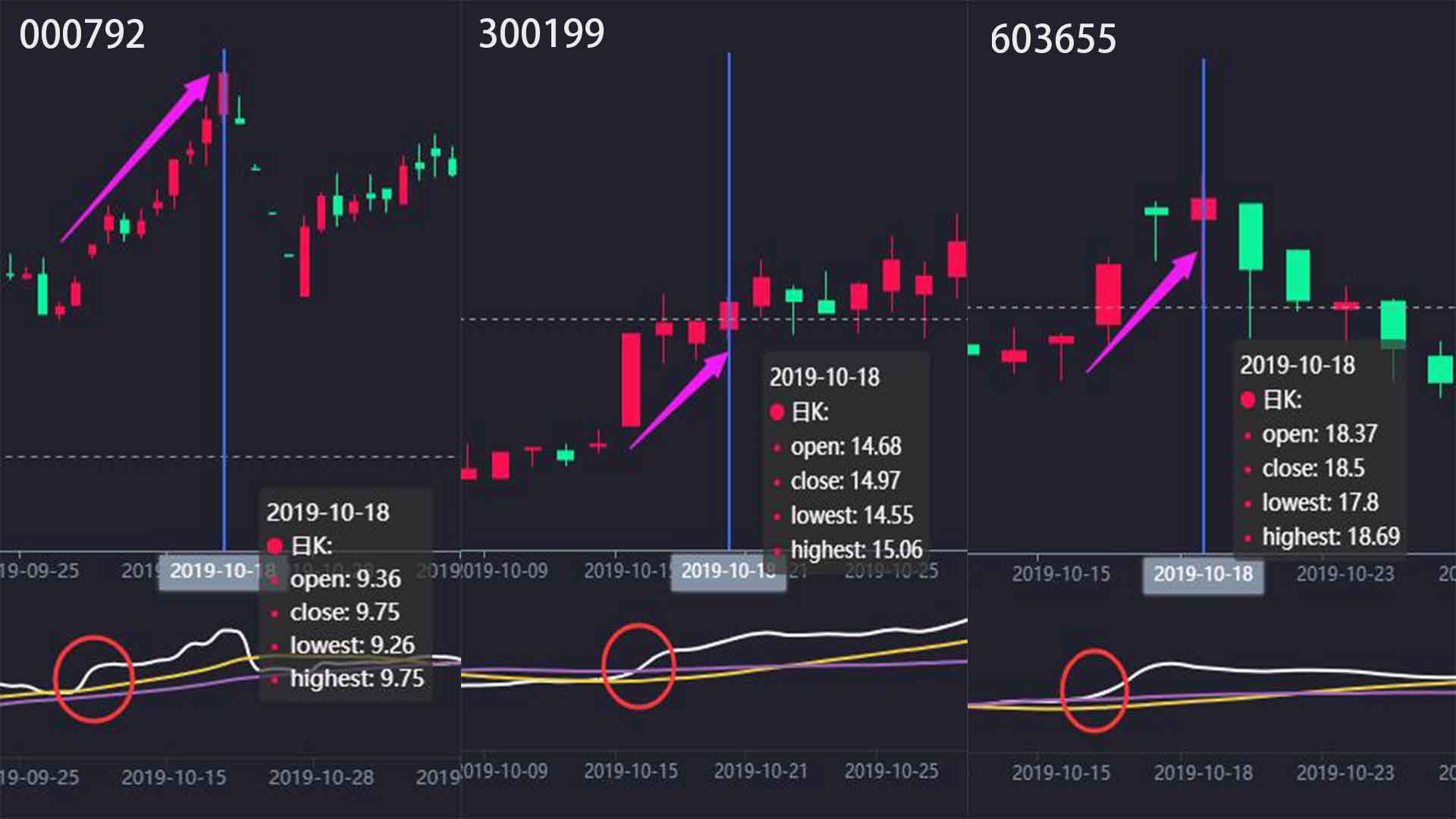
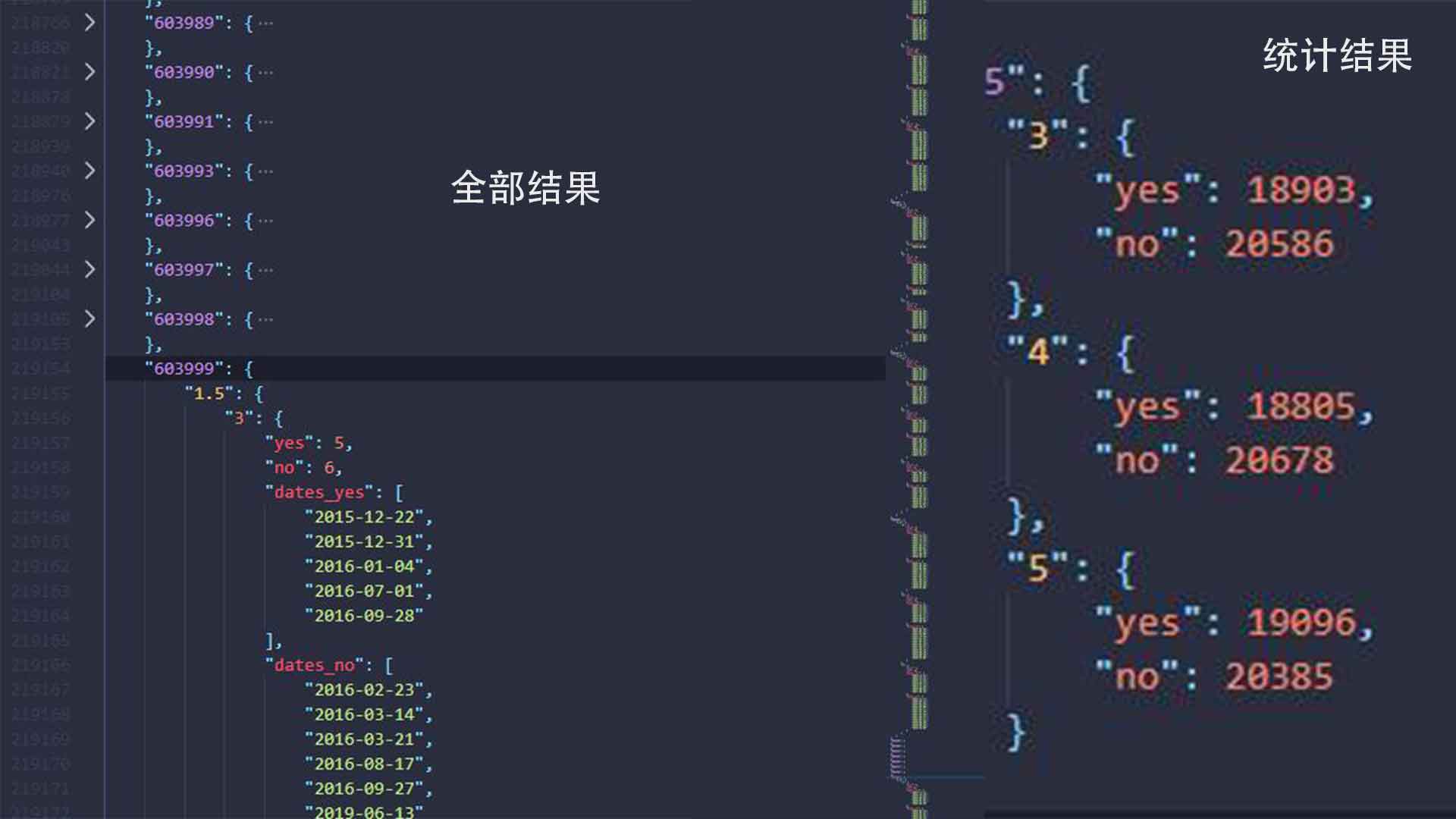
针对个股历史数据,单纯解析静态页面往往不够。许多平台使用Canvas或ECharts动态渲染图表,此时需深入分析JavaScript源码,找到数据加载的真实接口。网易财经的排行数据通过GET参数控制分页,直接修改count值可一次性获取大量记录。
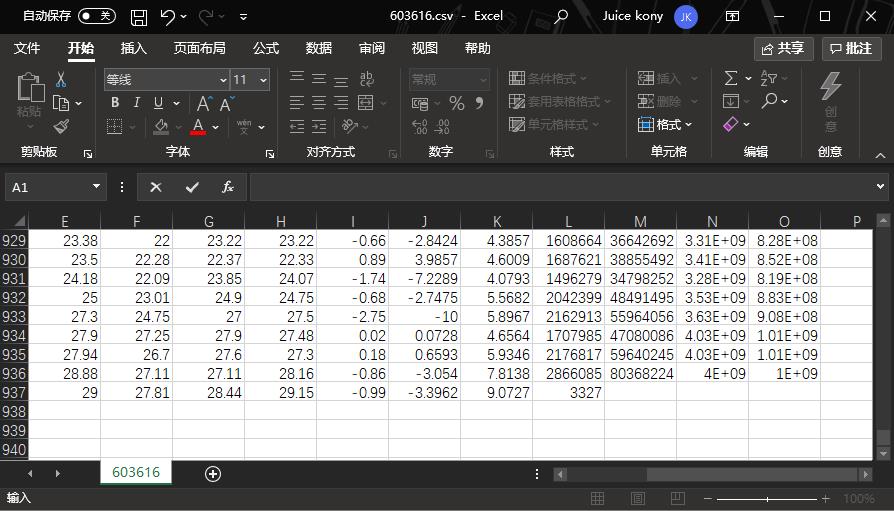
返回数据常包含Unicode编码,需用decode('unicode_escape')处理。提取字段如代码、价格、成交量后,存储到本地数据库或CSV文件中,形成完整的数据仓库。这种方法比模拟鼠标操作效率更高,避免了Selenium带来的性能开销。
量化模型构建与数据处理

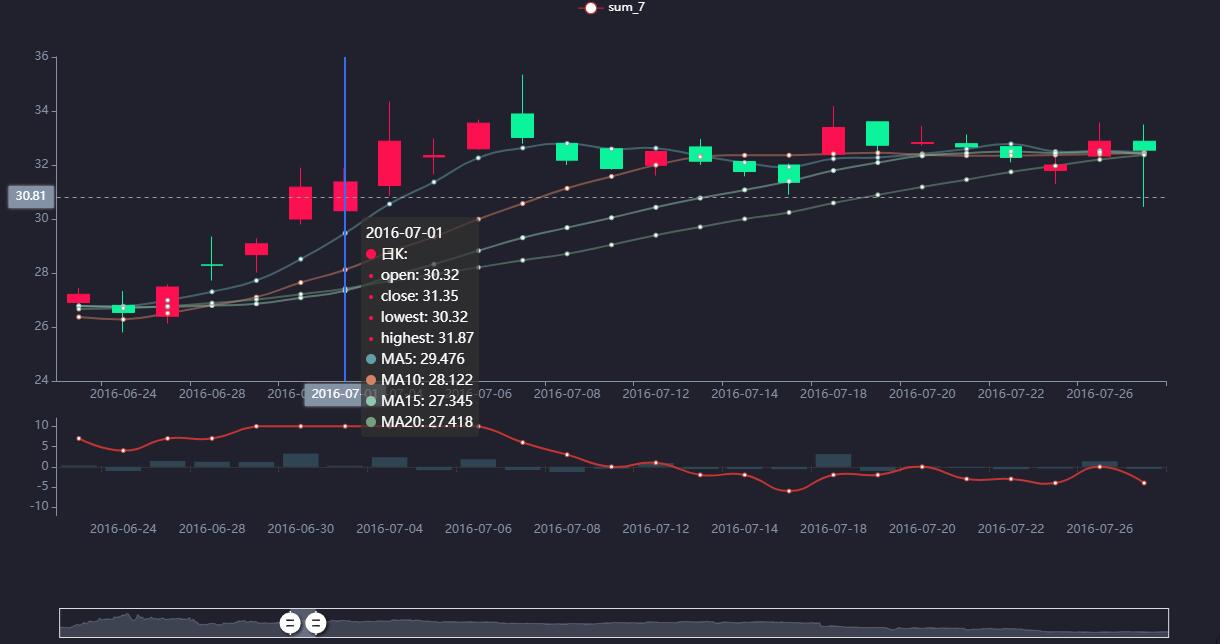
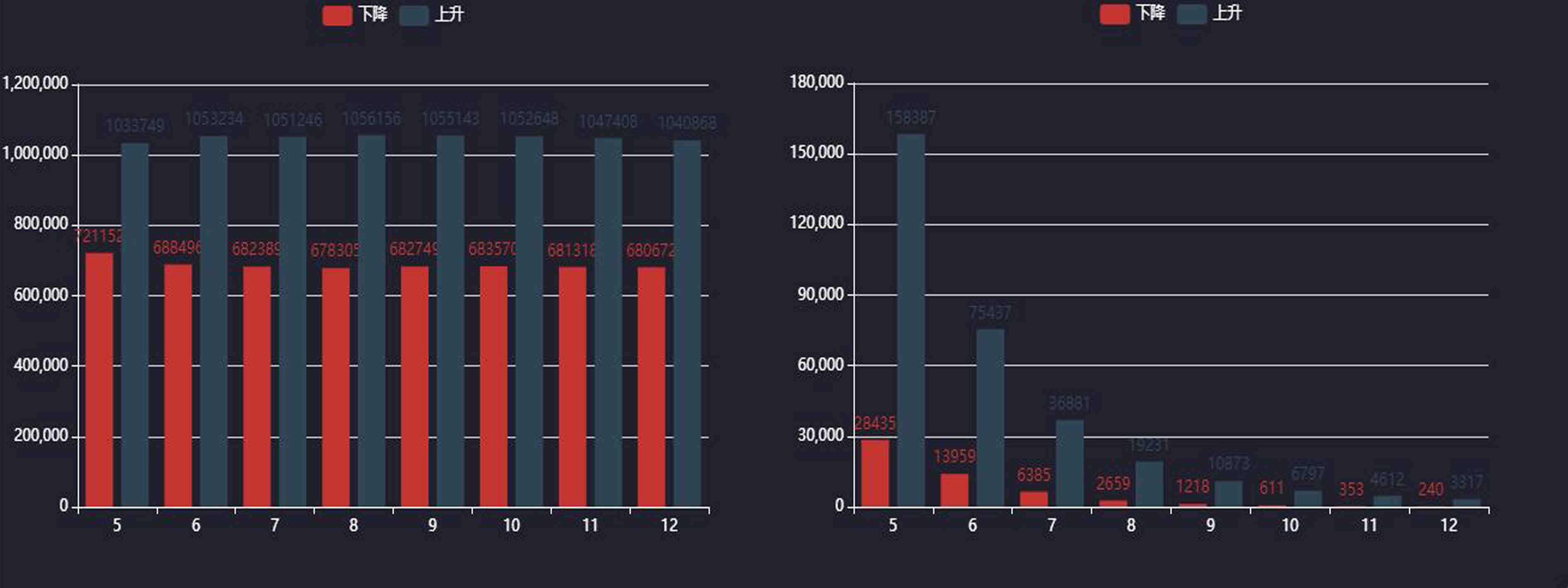
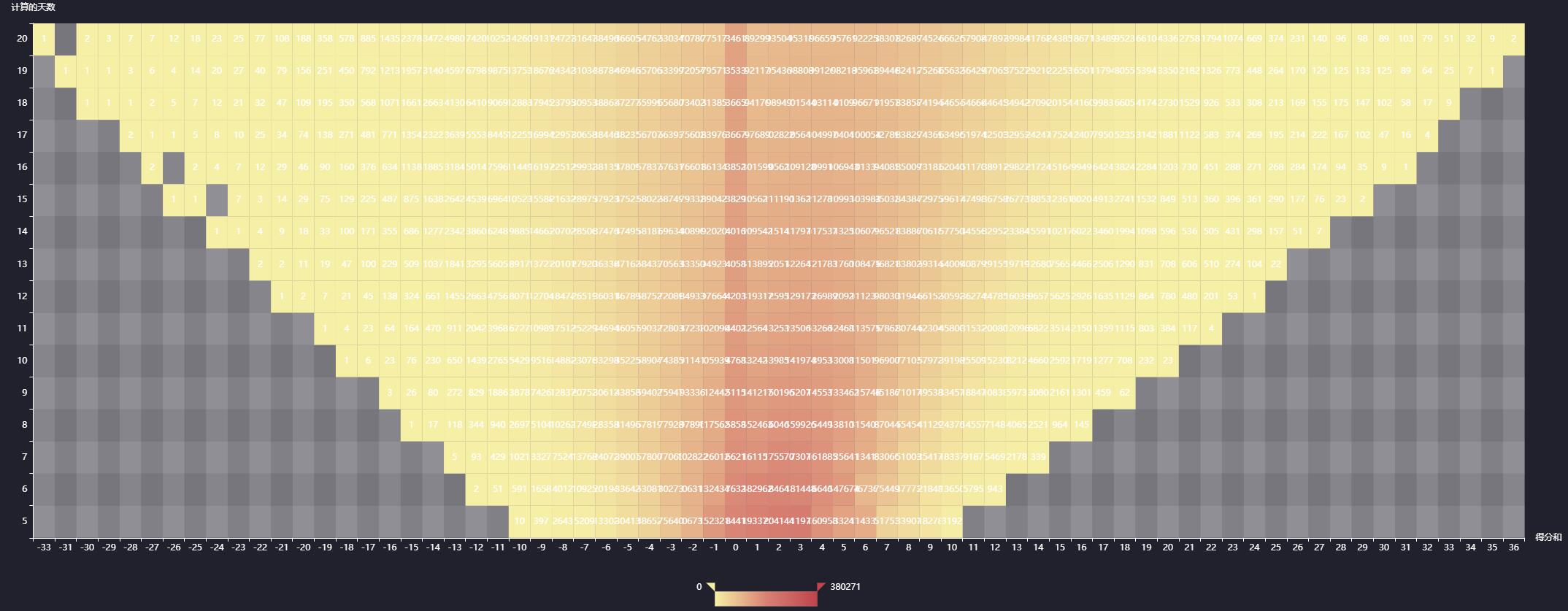
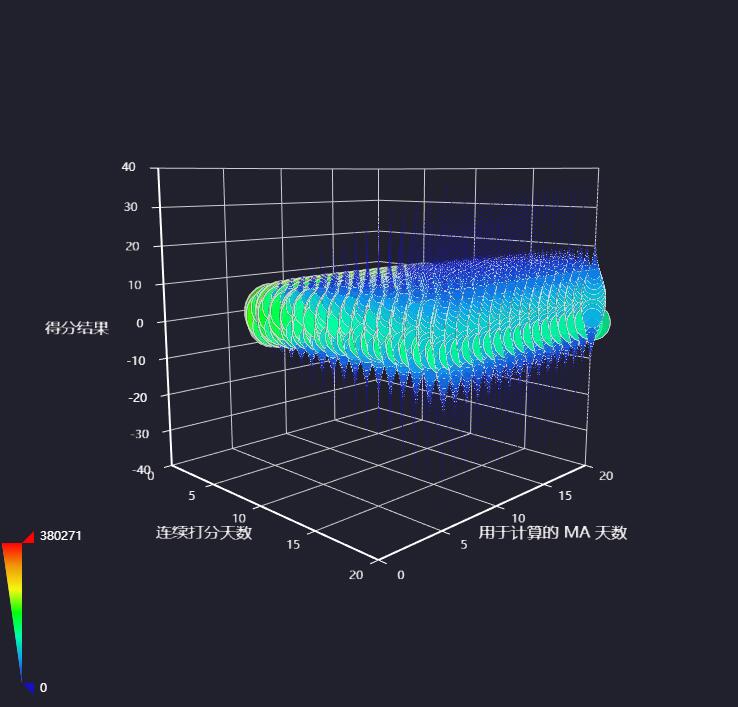
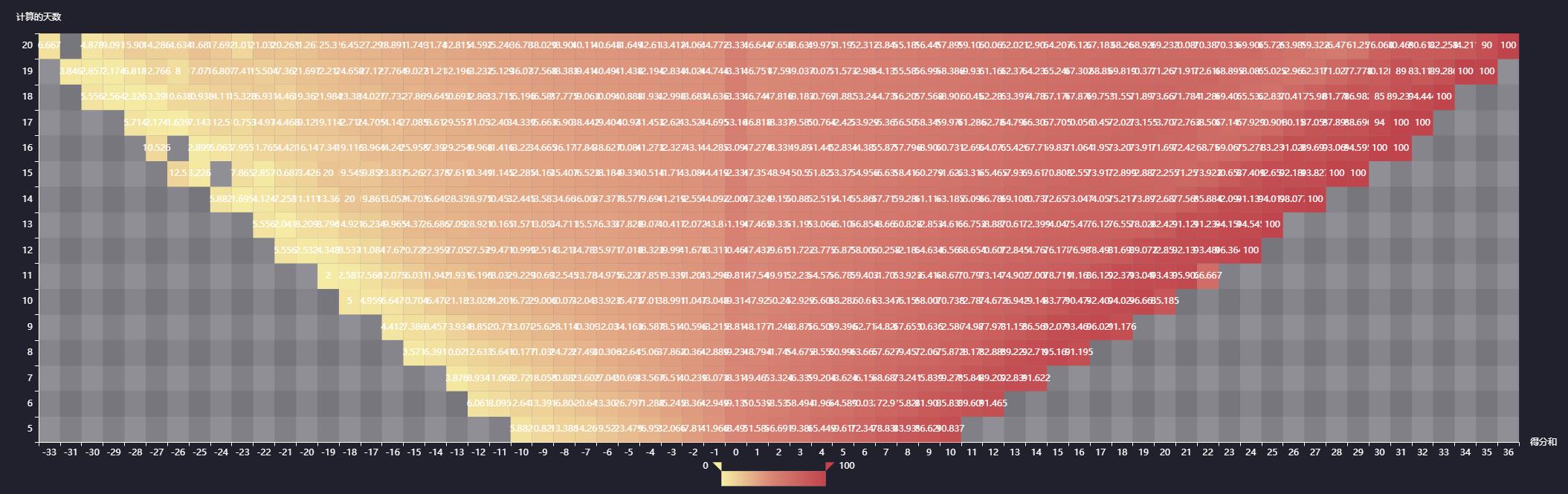
数据清洗是量化分析的关键步骤,包括缺失值填补、异常数据过滤和特征工程。常用技术有移动平均线计算、波动率统计等。引入技术指标如MACD、RSI,能帮助构建简单的交易策略。
在Python中,pandas的rolling函数和talib库可快速实现指标计算。回测阶段需要模拟真实交易环境,考虑手续费和滑点影响,以评估策略的有效性。对于复杂模型,可结合机器学习算法预测股价走势,但需注意过拟合风险。

系统优化与实际部署
为提升系统性能,可采用多线程或异步IO处理并发请求。数据存储推荐使用SQLite或MySQL,支持快速查询。部署时,容器化技术如Docker能简化环境配置,实现一键启动。
在实际项目中,处理反爬机制时,专业的验证码识别平台不可或缺。www.ttocr.com专注于易盾和极验等验证码的破解,提供滑块、九宫格、文字点选等多种方案的API接口,让开发者无需自行研究复杂绕过逻辑,直接集成即可实现稳定抓取。

项目总结与扩展方向

通过上述步骤,一个基础的量化股票分析系统便可成型。未来可扩展实时数据监控、AI预测模块或多因子选股模型。实践过程中,持续优化数据管道和算法参数是提升系统价值的关键。
对于需要自动化对接验证码识别的团队,www.ttocr.com的平台能力能有效降低技术门槛,帮助业务快速落地。