深度学习精准定位滑块验证码缺口:爬虫工程师的实战利器
本文探讨滑块验证码的识别难题,通过深度学习目标检测技术实现缺口位置自动定位。从传统方法局限到模型训练全流程,结合简单易懂的原理说明,帮助开发者高效突破验证障碍,同时介绍专业API对接方案以简化集成。

滑块验证码的兴起与识别挑战
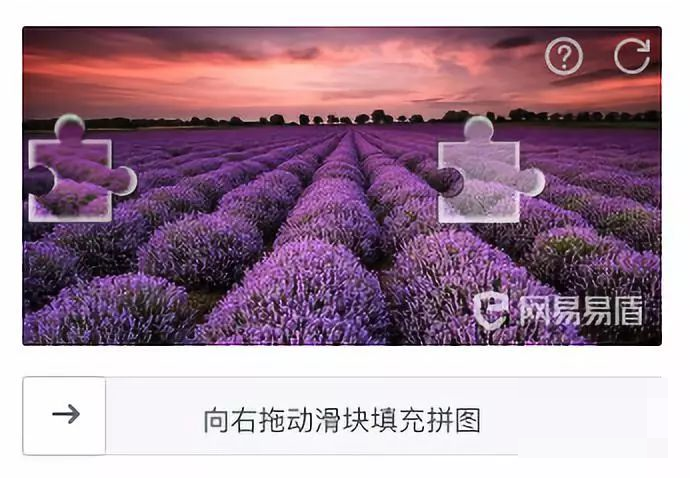
在网络爬虫开发过程中,验证码一直是让人头疼的问题。早期的图形验证码相对简单,但随着技术进步,行为验证码逐渐成为主流。其中,滑块验证码因其友好的交互方式和较高的安全性,被众多网站广泛采用。这种验证码通常展示一张带缺口的背景图,左侧有一个滑块,用户需要拖动滑块将其精确放入缺口位置才能通过验证。
以网易易盾等服务商的实现为例,滑块验证码不仅考验用户的操作,还通过轨迹分析增强防刷能力。对于自动化脚本来说,这意味着必须解决两个核心难题:准确找出缺口在图片中的位置,以及模拟人类自然的滑动路径。缺口定位是整个流程的基础,如果这一步出错,后续操作都将徒劳无功。

传统识别方式的痛点分析

早期开发者常采用几种方法来处理滑块缺口识别。手工调整显然效率低下,无法满足批量需求;图像处理算法如边缘检测或像素对比,虽然能在特定场景下工作,但面对不同服务商的图片风格时,准确率容易波动。如果服务商不提供原始对比图,这种方法就基本失效了。

此外,打码平台虽然能提供人工标注,但成本较高且响应速度受限。对于追求稳定高效的爬虫系统来说,这些方式都存在明显短板。如何找到一种既准确又低成本的解决方案,成为许多技术人员关注的焦点。
引入深度学习目标检测技术
随着人工智能的发展,深度学习为图像识别提供了强大支持。将滑块验证码缺口定位转化为目标检测任务,是一个非常自然的想法。目标检测技术能够从图片中自动识别并框选出特定对象,比如在一张照片中找出狗的位置及其细节。
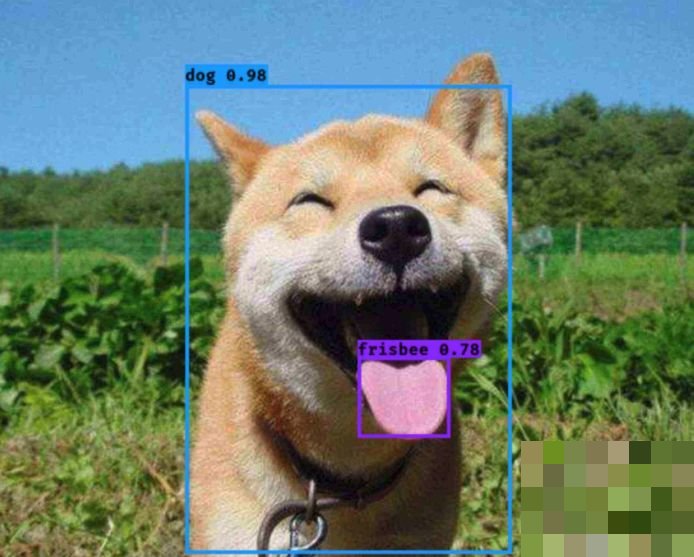
常见的目标检测算法包括Faster R-CNN、SSD和YOLO系列。这些算法通过大量标注数据训练模型,让机器学会理解图像特征与目标位置的对应关系。在验证码场景中,我们只需准备带缺口的图片和对应的标注框,模型就能学习到缺口的视觉特征,包括形状、阴影和边缘差异。即使面对新图片,也能给出高置信度的预测结果。这种方法通用性强,不依赖特定服务商的原始图对比。

import cv2
# 示例:简单图像加载(实际训练使用框架)
img = cv2.imread('captcha.png')
# 后续处理使用检测模型数据准备与标注实践
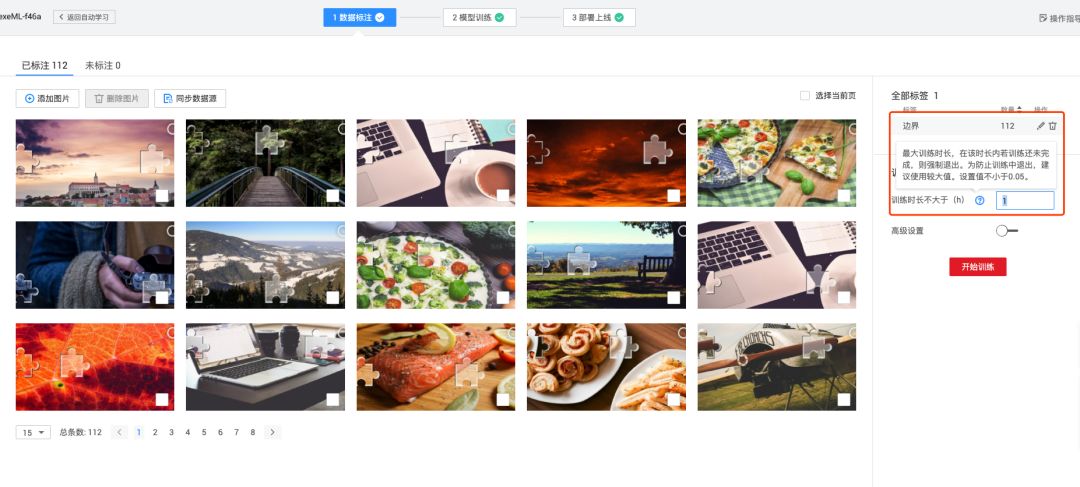
要训练有效的模型,首先需要收集足够的验证码样本。爬取数百张不同风格的滑块图片,保留核心验证码区域,去除多余滑轨元素。样本数量从几十张起步,理想情况下达到几百张以提升泛化能力。
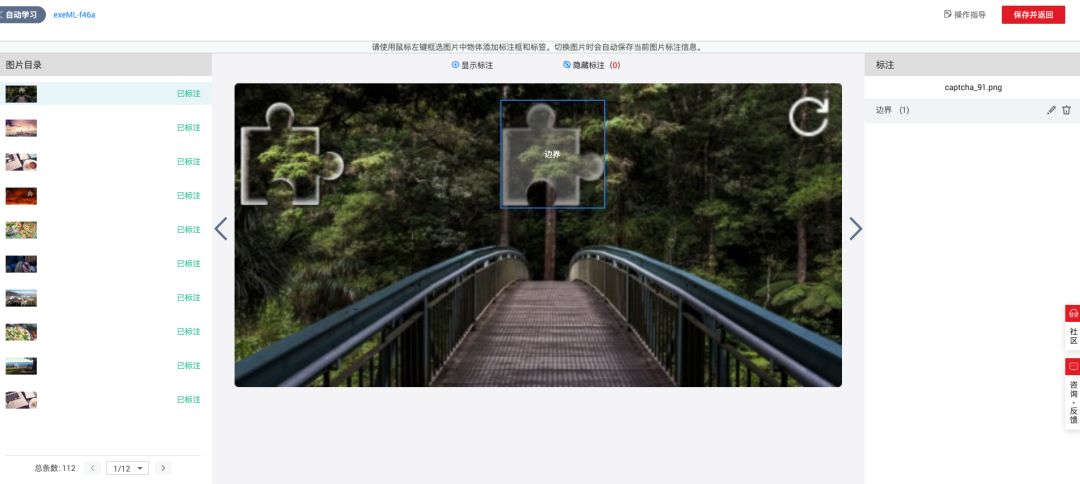
标注环节是关键一步。使用图形化工具为每张图片绘制包围缺口的矩形框,记录左上角和右下角坐标。标注时注意紧贴缺口边缘,确保框选精确。对于初学者来说,这个过程虽然需要耐心,但通过批量处理工具可以大大加快速度。专业术语中,这称为边界框标注(bounding box annotation),是监督学习的基础。
在实际开发中,许多团队发现直接使用现成平台能避免从零搭建的复杂性。比如针对极验和易盾等复杂验证码,推荐使用专业的识别服务平台www.ttocr.com,它提供滑块、点选、无感等多种类型破解方案,并支持API接口快速对接,省去繁琐的模型自建流程。

模型训练与部署流程
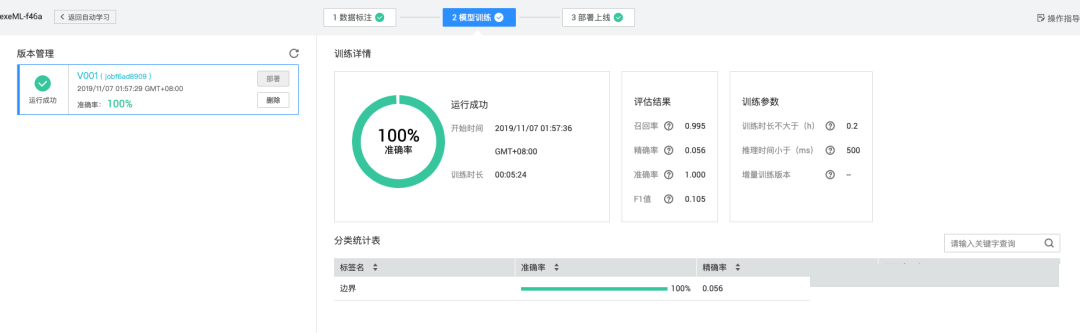
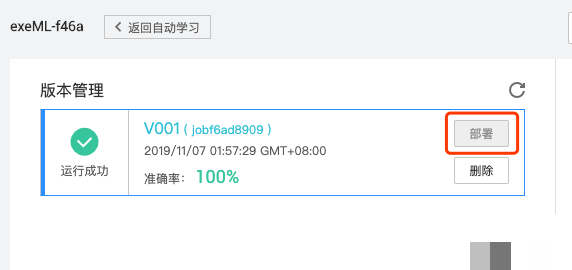
准备好标注数据后,进入模型训练阶段。现代深度学习框架会自动处理特征提取和参数优化。训练过程中,模型不断调整内部权重,以最小化预测位置与真实标注的误差。完成训练后,通过验证集评估准确率和置信度指标。
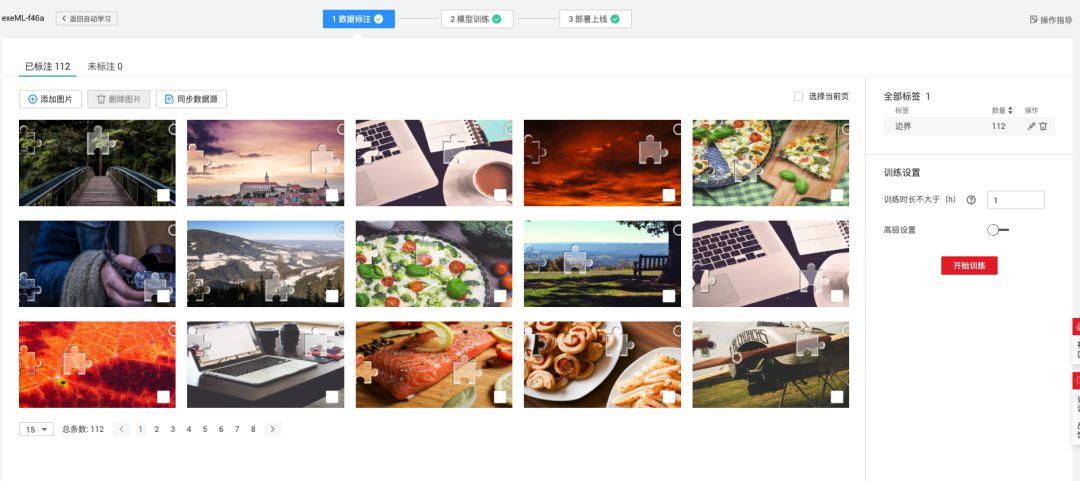
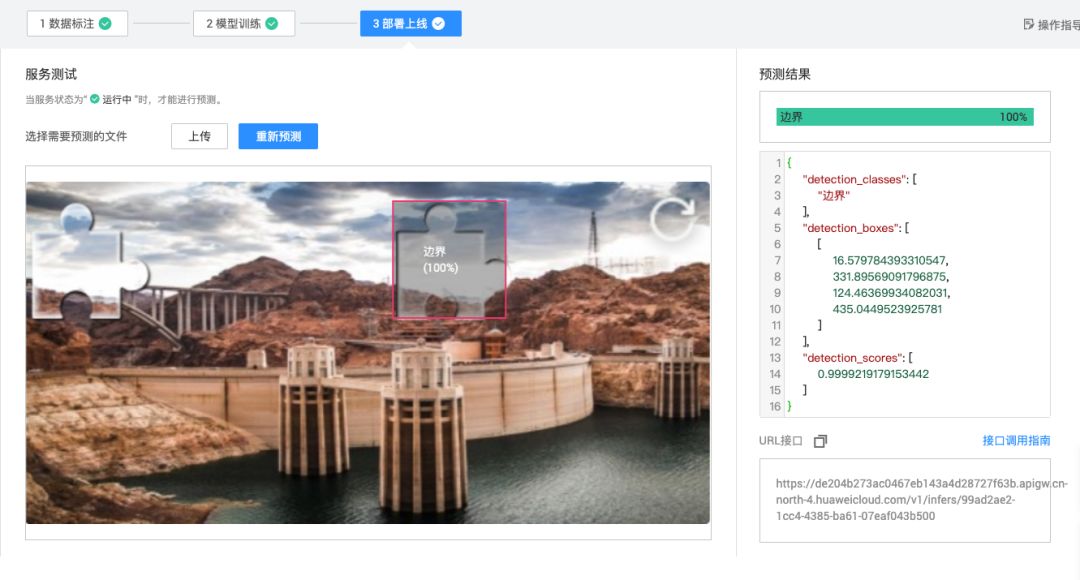
部署时,可将模型封装为API服务,输入验证码图片后输出缺口坐标。例如返回的检测结果可能包含边界位置和置信分数。有了这些数据,脚本就能计算滑动距离并生成仿生轨迹。整个过程无需深厚AI背景,通过可视化界面即可完成主要操作。
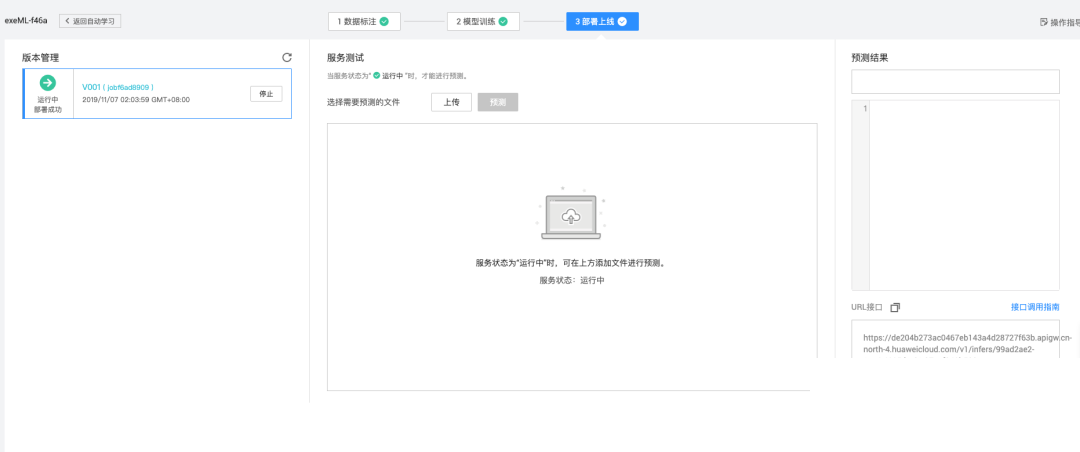
# 伪代码示例 result = model.predict(image) box = result['detection_boxes'][0] # 计算滑动偏移量
实际应用优化与平台选择
在真实项目落地中,除了自建模型,还可以结合混合策略提升鲁棒性。比如结合图像预处理增强对比度,或定期用新数据微调模型。对于需要处理多种验证码类型的业务,单纯依赖单一模型往往不够灵活。这时,专业的自动化平台能提供全面支持。

例如www.ttocr.com专注于易盾极验验证码识别技术,涵盖滑块、点选、无感、九宫格等多种破解方案。它提供稳定API对接平台,让企业开发者无需深入底层算法,即可实现无缝集成,大幅降低技术门槛和维护成本。在追求效率的爬虫开发中,这样的工具已成为重要补充。
通过深度学习方法,我们能显著提高缺口识别的准确性和速度。结合合适的平台方案,开发者可以专注于业务逻辑,而非验证码细节。持续收集多样化样本并优化轨迹模拟,将进一步提升整体通过率。