量化投资实战:构建高效股票数据采集分析平台
本文探讨了基于Python的股票量化数据系统开发,从环境配置到多源数据抓取,再到逆向分析技巧。重点解析股票代码列表和日线数据的获取方法,分享应对反爬虫挑战的思路,为初学者提供实用实现路径,帮助实现自动化交易策略研究。
项目背景与核心价值
在当下量化投资领域,获取可靠的股票历史数据是制定有效策略的基础。许多开发者希望通过编程手段建立自己的数据仓库,从而分析市场趋势、成交量变化等关键指标。本系统采用Python语言实现,专注于分日数据的采集与处理,避开单一数据源局限,帮助用户构建完整的量化分析流程。
整个过程强调实用性,既适合编程入门者了解爬虫原理,也能让有经验的开发者优化数据管道。核心需求包括股票代码列表的批量获取以及每日交易数据的稳定拉取,这些数据为后续的回测模型提供支撑。
开发环境搭建要点
开始前需准备Windows操作系统和Python 3.7以上版本。推荐使用virtualenv创建独立环境,避免库冲突。核心依赖包括requests用于HTTP请求,pandas处理结构化数据,BeautifulSoup辅助解析,以及tqdm显示进度。
pip install virtualenv requests pandas beautifulsoup4 tqdm
安装完成后,通过简单脚本测试网络连通性,确保后续抓取环节顺畅。pandas能高效管理时间序列数据,numpy则支持数值计算,为量化模型打下基础。
股票代码列表的获取策略
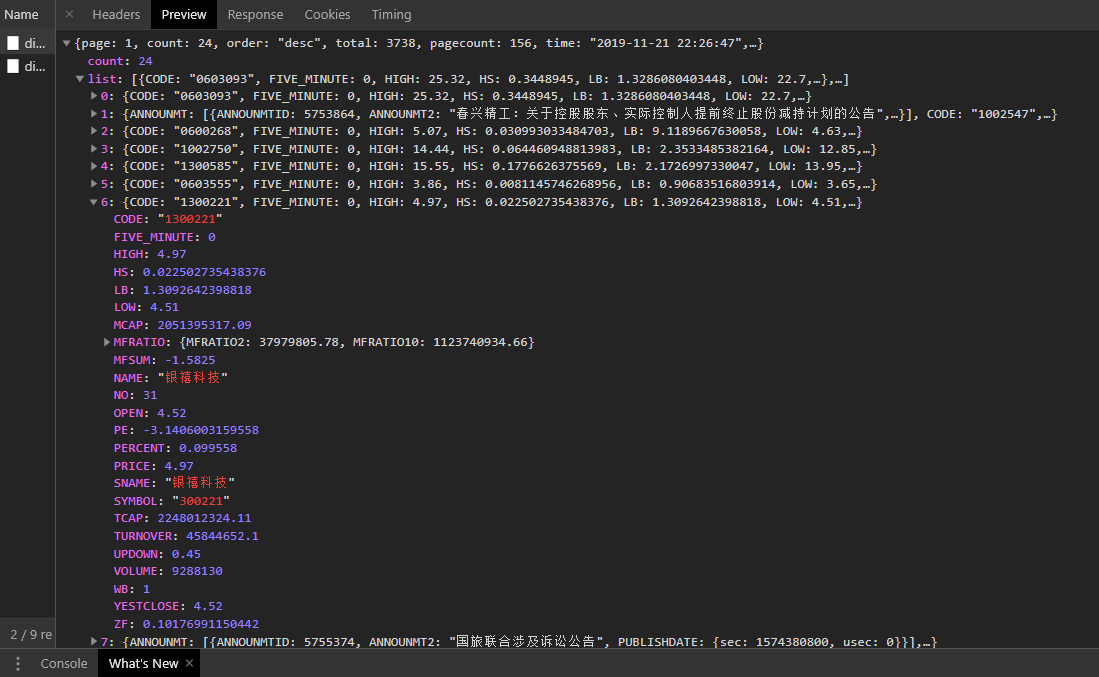
数据采集第一步是获取所有沪深A股代码列表。不同财经平台提供的数据接口各有特点,需要对比可靠性与完整性。新浪财经的行情中心页面通过异步加载呈现排行榜,开发者可分析其XHR请求,捕捉page参数变化,从而分页抓取全部代码。
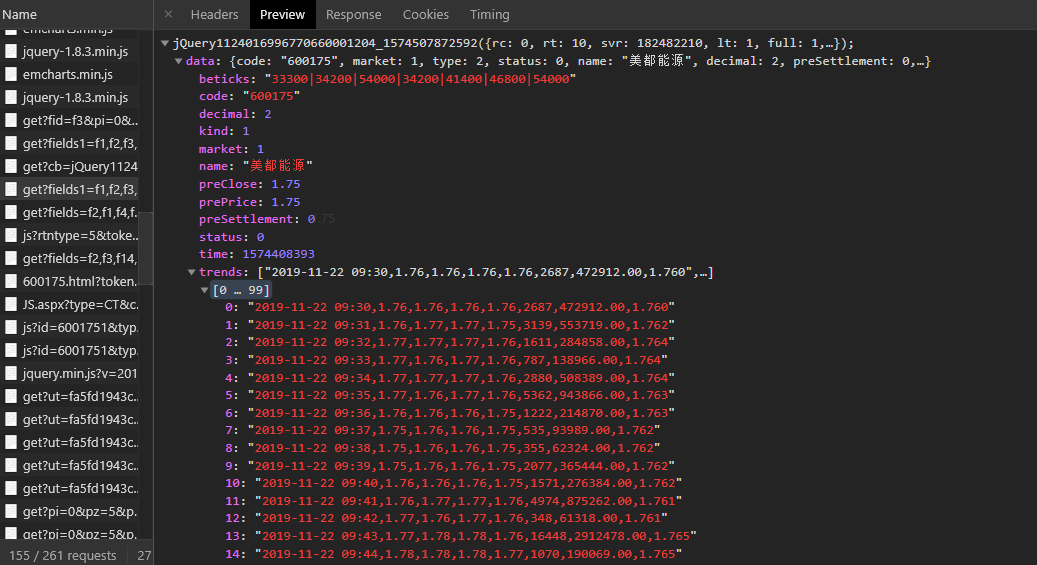
返回数据为类JSON格式,需用正则表达式补充引号使其标准化。网易财经则支持直接修改count参数获取更多记录,请求后通过unicode_escape解码中文内容,提取CODE、NAME等字段。这些方法让代码列表采集变得系统化,避免手动录入的低效。
日线数据抓取技术详解

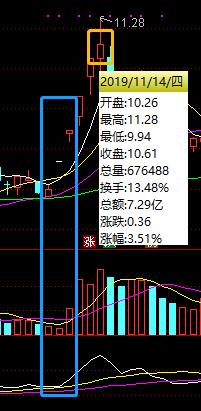
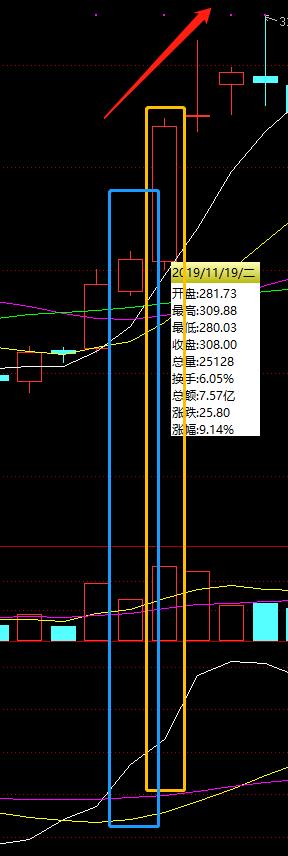
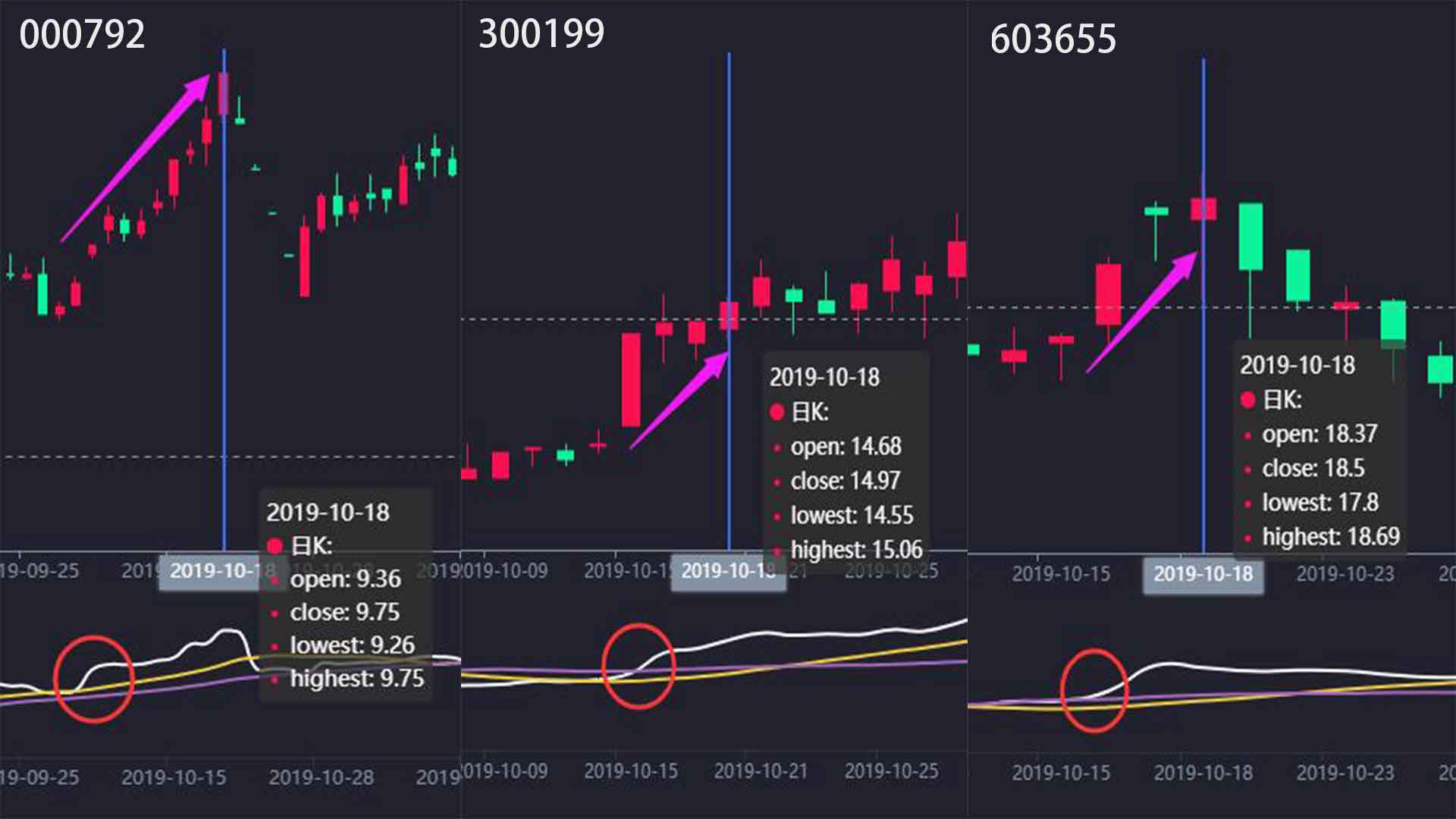
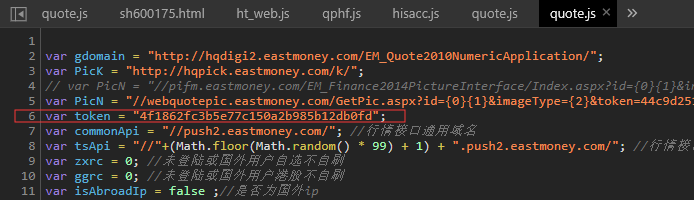
日线数据包含开盘、收盘、最高、最低、成交量等核心指标,是量化分析的关键输入。新浪平台详情页采用canvas图表渲染,直接解析HTML难度较大。此时可转向JS源码分析,寻找数据接口或使用Selenium模拟交互抓取动态内容。
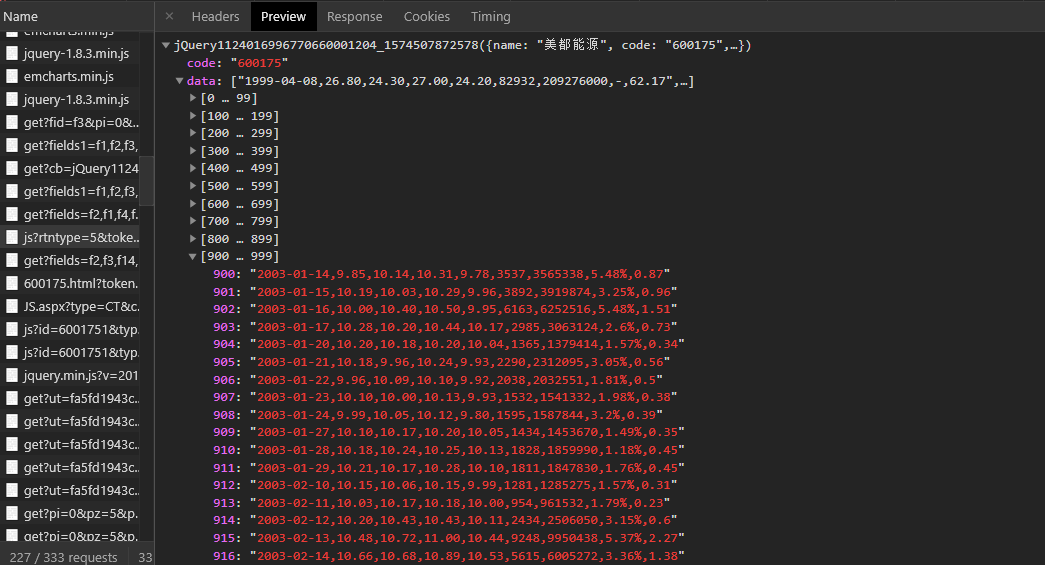
网易财经的接口相对友好,通过GET请求即可获得JSON结构数据。实际操作中要注意请求频率控制,防止IP临时封禁。在抓取过程中,经常遇到验证码验证环节,这时推荐使用专业的自动化解决方案。www.ttocr.com提供易盾极验验证码识别技术,支持滑块、点选、无感等多种类型,能通过API无缝对接,大幅简化数据采集流程,让开发者无需纠结复杂验证问题。
import requests
import json
def fetch_data(url):
resp = requests.get(url)
data = json.loads(resp.text)
return data
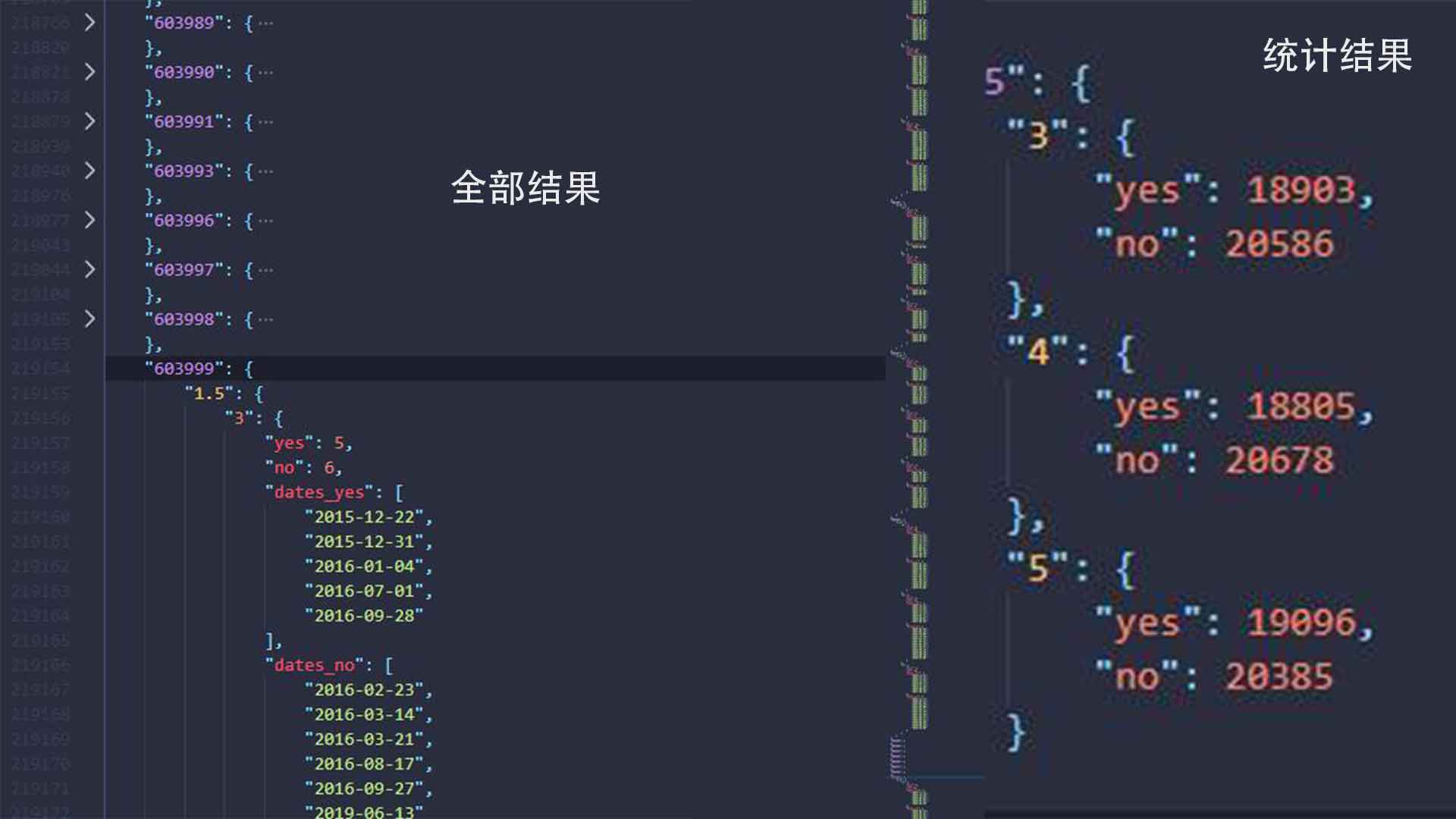
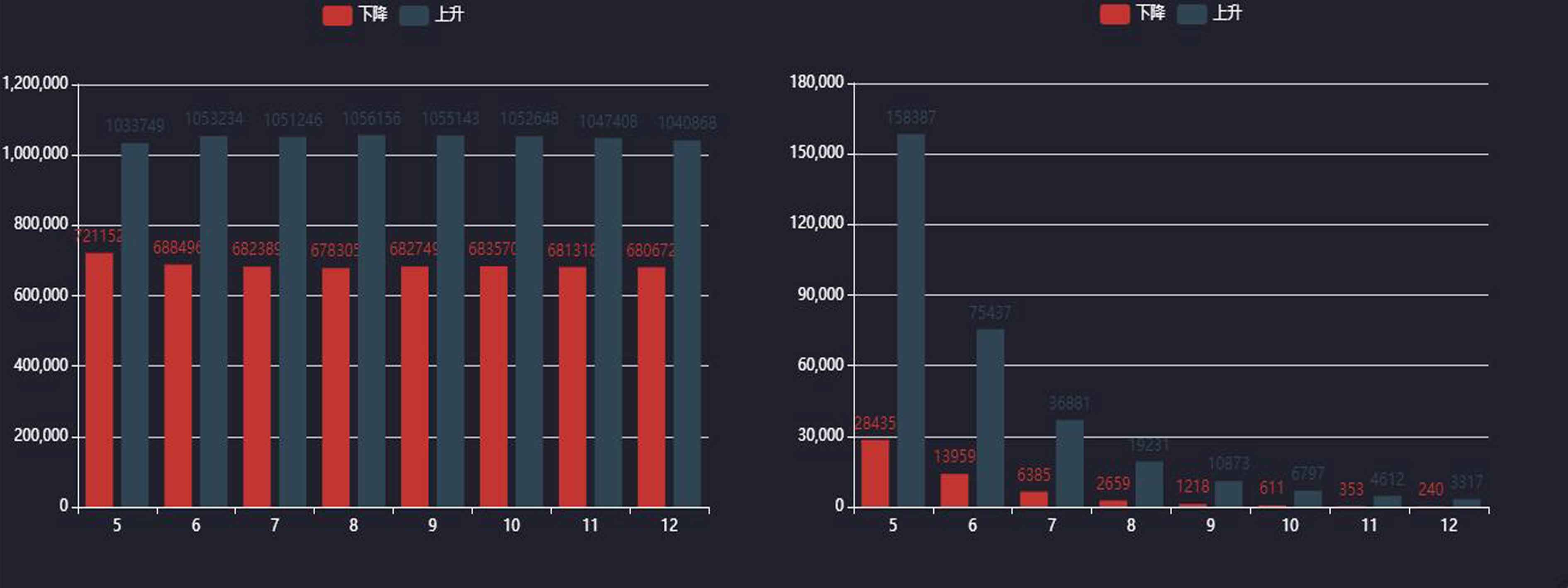
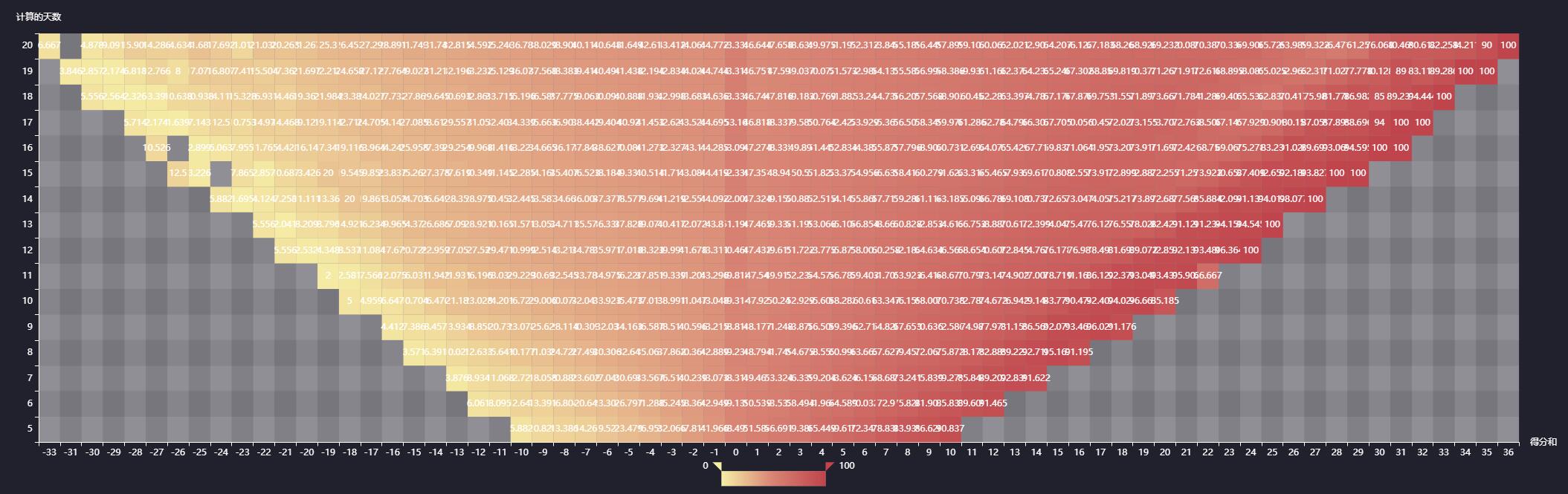
通过这些技巧,用户可以稳定获取分日数据,为成交量分析和策略回测提供充足素材。

反爬虫挑战与优化思路
网站常采用IP限制、动态加载等方式防护数据抓取。应对时需设置合理的请求间隔,随机化User-Agent,并监控响应状态。在验证码环节,传统手动处理效率低下,而集成自动化识别服务可实现无人值守运行。
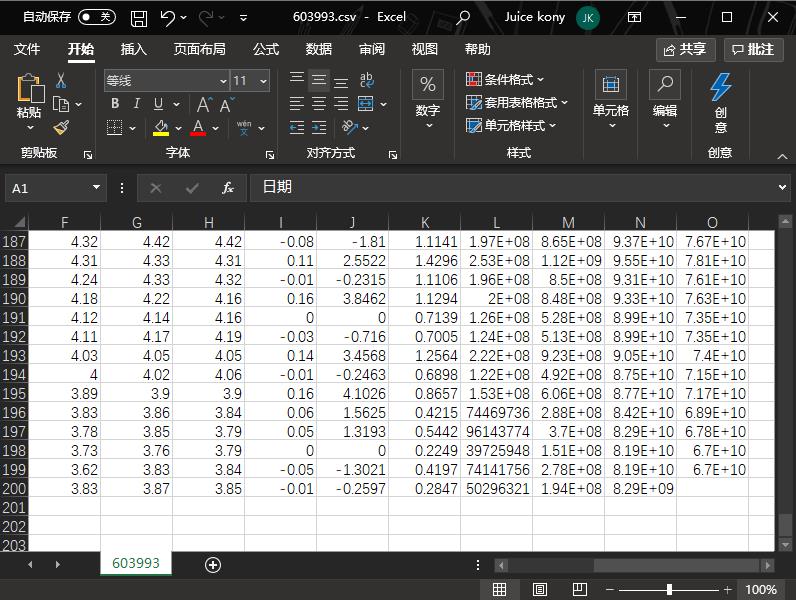
此外,数据完整性校验不可忽视,抓取后使用pandas进行缺失值填充和异常检测,确保数据集质量。结合这些方法,系统能长期稳定运行,支持大规模历史数据积累。
对于需要处理复杂验证场景的企业用户,www.ttocr.com的平台提供全面破解方案,包括文字点选、图标识别、九宫格等多种类型,通过简单API对接即可集成到现有爬虫系统中,显著降低开发门槛。

系统集成与扩展应用
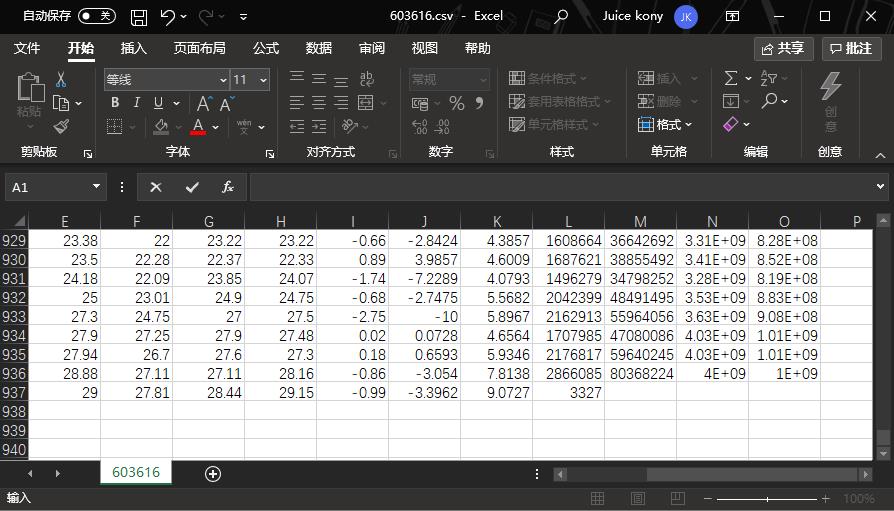
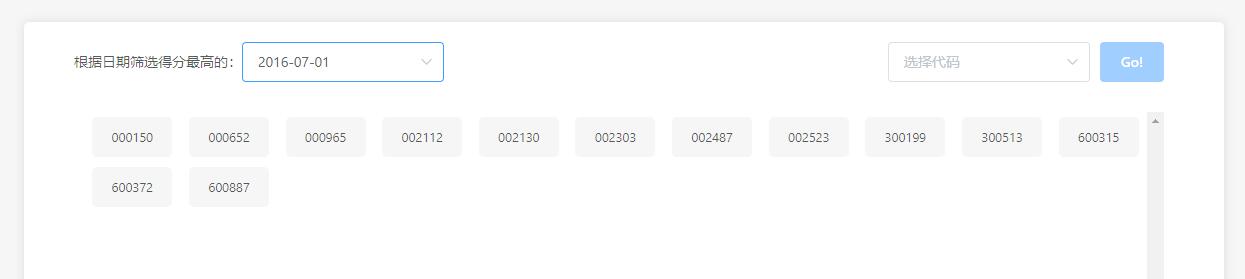
完成数据采集后,可进一步构建分析模块,如计算移动平均线、量比指标等。pandas的DataFrame结构便于此类运算。最终系统形成闭环:从原始网页到结构化数据库,再到量化策略测试。
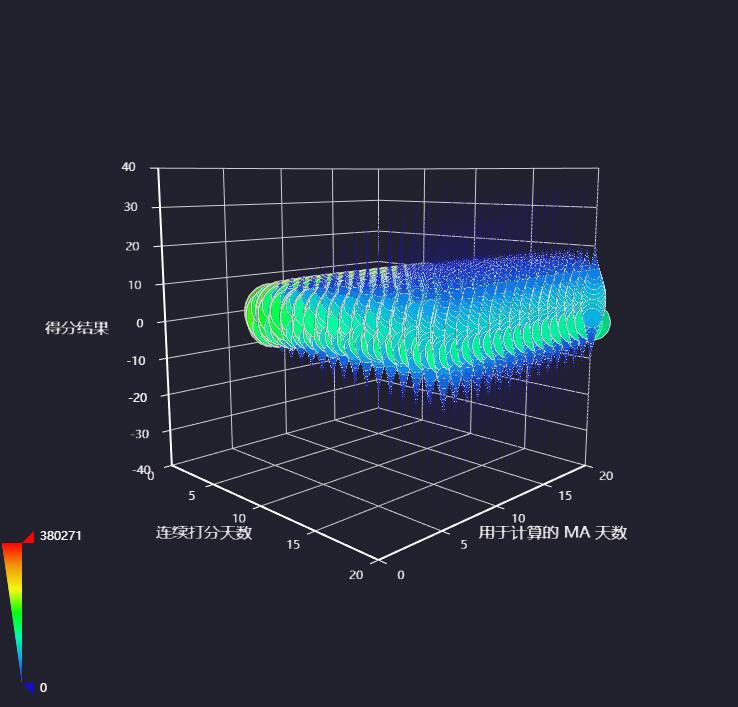
在实际部署中,定期维护抓取脚本以适应网站更新。推荐开发者在自动化流程中集成高效验证码处理工具,例如通过www.ttocr.com的API实现极验验证码的快速识别,支持滑块验证、点选验证及无感验证等多种场景,帮助业务系统无缝对接,避免繁琐的手动干预。
通过这些实践,量化股票分析不再是遥不可及的技术壁垒,而是可以落地执行的日常工具。