极验九宫格验证码精准分类模型训练指南
极验九宫格验证码识别需要先定位目标再匹配九宫格区域。经典方法是先用YOLOv8分类模型识别点击目标,再用CLIP模型计算相似度找出对应位置。训练时准备数据集包括目标图和九宫格小图,划分比例后配置YAML文件,执行训练脚本即可得到模型。实际测试显示准确率能达到90%以上,适合自动化验证场景。

模型介绍和整体流程概述
极验九宫格验证码识别的核心在于处理两张关键图片:一张显示点击目标,另一张展示九宫格网格。用户点击的区域需要在目标图中定位,然后在网格图中找到匹配位置。YOLOv8作为单阶段检测框架,能快速处理这类图像任务,支持从边缘设备到服务器的灵活部署。它结合了高效的C2f模块和特征金字塔网络,在速度和精度上都有明显提升。CLIP多模态模型则通过对比学习将图像和文本映射到统一空间,实现零样本迁移,对中文图文匹配特别友好。
整个流程通常包含数据集准备、模型训练和推理测试三个阶段。开发者可以先选择YOLOv8分类模型进行目标识别,再结合CLIP进行位置匹配,或者直接使用混合方案。这种方式能有效应对滑动、点选和九宫格等不同类型的验证码。整个过程开源且易于上手,适合开发者和测试人员快速实现自动化验证。
数据集准备和处理技巧
获取极验验证码截图后,先将图片裁剪成目标点击图和九宫格小图。目标图通常包含一个突出物体,九宫格图则是9个小方块布局。建议为每张小图命名以区分来源,比如方向盘相关的图片可以标记为方向盘0。把所有裁剪后的小图收集到同一文件夹中。
使用分类平台对图片进行批量识别标注,将每张图对应到正确的类别名称。类别数量控制在90个左右,确保覆盖常见物体如乌龟、书、井盖等。数据集划分比例可以设置为0.7训练集、0.2验证集和0.1测试集,这样能平衡模型泛化能力和过拟合风险。最终生成data.yaml配置文件,路径指向数据集根目录,并列出train、val和test子文件夹。类别名称字典也要完整列出,避免识别时出现漏标。
数据增强是提升准确率的关键步骤。包括随机旋转、亮度调整和噪声添加,能让模型更适应真实验证码环境。标注时注意目标图和网格图的分离处理,后续推理时直接用裁剪后的图片输入模型。
YOLOv8分类模型训练步骤
安装Ultralytics库后,加载预训练模型yolov8m-cls.pt作为起点。创建训练函数,指定data.yaml路径、训练轮数30、批处理大小32、图像尺寸96以及GPU设备0。运行脚本后,模型会在runs目录下生成classify文件夹,保存分类结果。
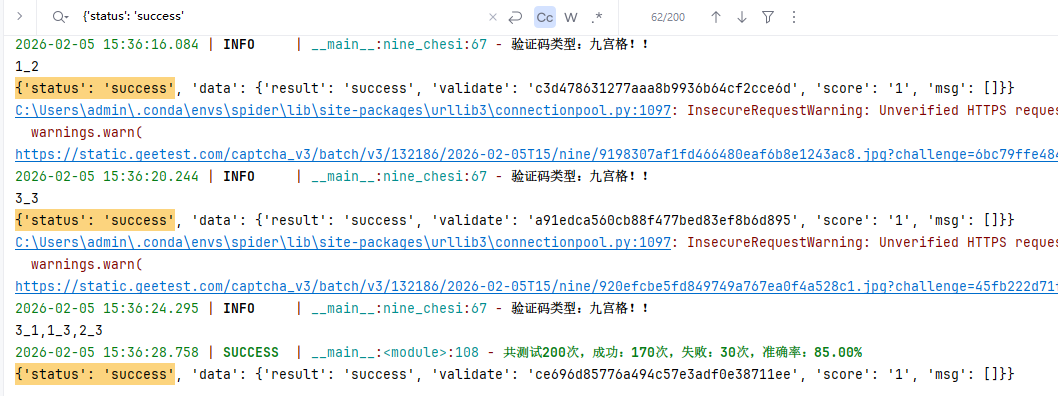
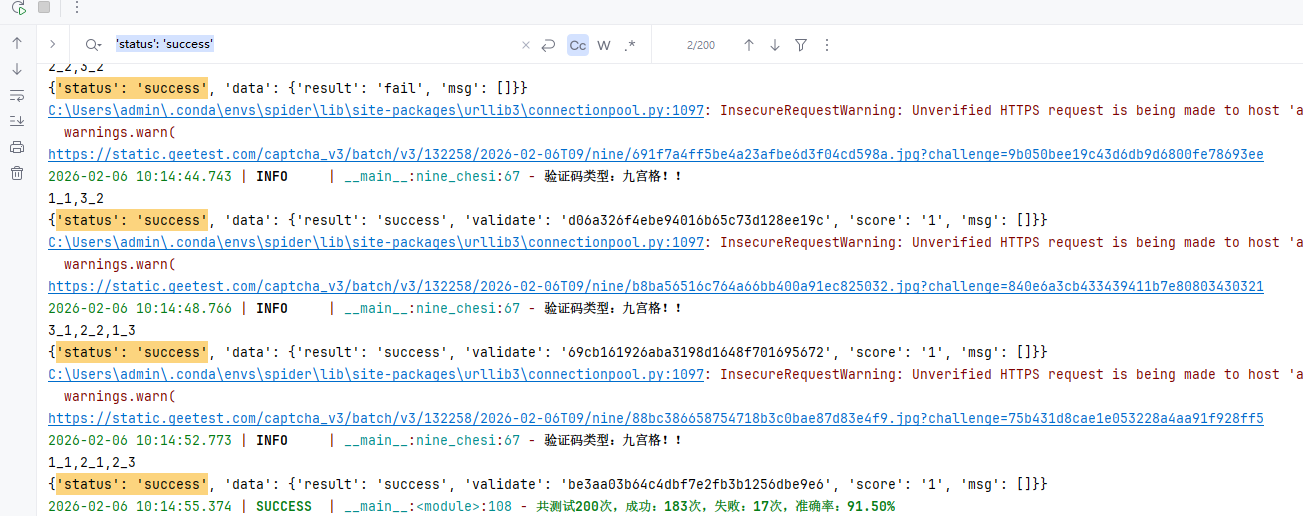
测试阶段加载训练好的权重文件,使用predict方法传入裁剪后的图片。结果对象包含top1索引、置信度和前五名概率等信息。结合class_names字典,可以快速获取最高概率的类别名称。实际验证中,多次优化数据集后准确率轻松突破90%,这足以满足日常自动化验证需求。
from ultralytics import YOLO
def main():
model = YOLO('yolov8m-cls.pt')
model.train(
data=r'E:\yolov8\ultralytics\nine_data\data.yaml',
epochs=30,
batch=32,
imgsz=96,
device='0'
)
if __name__ == '__main__':
main()训练完成后,推荐多收集不同风格的验证码图片,以提高模型在各种场景下的鲁棒性。

CLIP模型应用与混合方案
CLIP模型无需从零训练,直接使用预训练权重就能实现图文相似度计算。加载ViT-B-16模型后,对图像进行预处理并转换为张量。文本提示可以是类别名称列表,模型会返回相似度矩阵。

混合方案特别有效:先用YOLOv8识别目标图中的点击物体类别,再用CLIP在网格图中搜索相似图片位置。这种组合既保留了分类的准确性,又利用了多模态的迁移能力。官方模型对中文数据集适应性强,训练完成后准确率稳定在80%以上,测试时只需调整提示词即可。
推理时注意归一化特征处理,避免相似度计算偏差。实际应用中,开发者可以灵活切换模型尺寸,从轻量版到大模型,满足不同设备需求。
import torch
from PIL import Image
import cn_clip.clip as clip
from cn_clip.clip import load_from_name
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = load_from_name("ViT-B-16", device=device)
model.eval()
image = preprocess(Image.open("path/to/image.jpg")).unsqueeze(0).to(device)
text = clip.tokenize(["乌龟", "书"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image = model.get_similarity(image_features, text_features)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()推理测试与效果验证
加载最佳权重模型后,传入测试图片并调用predict接口。分析结果中的top1类别名称、置信度和前五名列表,能快速判断识别准确性。设置阈值过滤低置信度结果,避免误导后续操作。
实际案例中,优化数据集后九宫格识别准确率达到90%以上,滑动验证码也能通过相似度匹配稳定通过。开发者需要记录每张图片的坐标映射,确保模拟点击操作准确无误。
整个过程相对简单,重点在于数据集质量和模型调优。掌握这些基础后,就能轻松应对极验系列验证码的自动化需求。
实际应用与自动化验证建议
在爬虫开发中,将模型集成到Python脚本中,实现自动获取验证码图像、识别目标位置和模拟点击。结合各种验证类型,如文字点选和图标选择,都能通过类似流程处理。最终结果返回成功或失败,方便后续业务流程继续。
为了让识别过程更无缝,推荐采用API形式对接模型,避免本地部署的麻烦。只需要提供图片和目标类别,就能快速获得坐标信息。这种方式不仅提升效率,还能降低维护成本。