极验滑块验证实战指南:河南企业信用系统爬取全过程详解
极验滑块验证在数据爬取场景中扮演着重要角色,本文以河南企业信用信息公示系统为例,详细介绍其使用方法和关键参数。通过分析页面功能、逆向验证流程,并提供完整的Python实现代码示例,从请求头设置到数据解析,再到最终结果输出,读者可以轻松掌握这一技术。文章还探讨了常见问题解决策略,帮助开发者顺利完成自动化任务。
极验滑块验证的原理与作用
极验滑块验证是一种常见的反爬虫机制,旨在通过检测用户行为来区分正常访问和自动化程序。在河南企业信用信息公示系统这种需要批量数据拉取的场景中,它能够有效阻止大量请求对服务器造成压力。滑块验证通常涉及滑动块对齐图形或验证码图片,用户需要完成特定操作后才能提交表单。
这种验证方式的核心在于其动态性,每次请求都会生成唯一的挑战码(challenge)和验证码(validate),保证了过程的随机性。开发者在爬取数据时,必须模拟真实用户的交互模式,否则很容易被识别为恶意流量。这不仅涉及技术层面的请求处理,还包括对页面结构的理解和逆向分析。

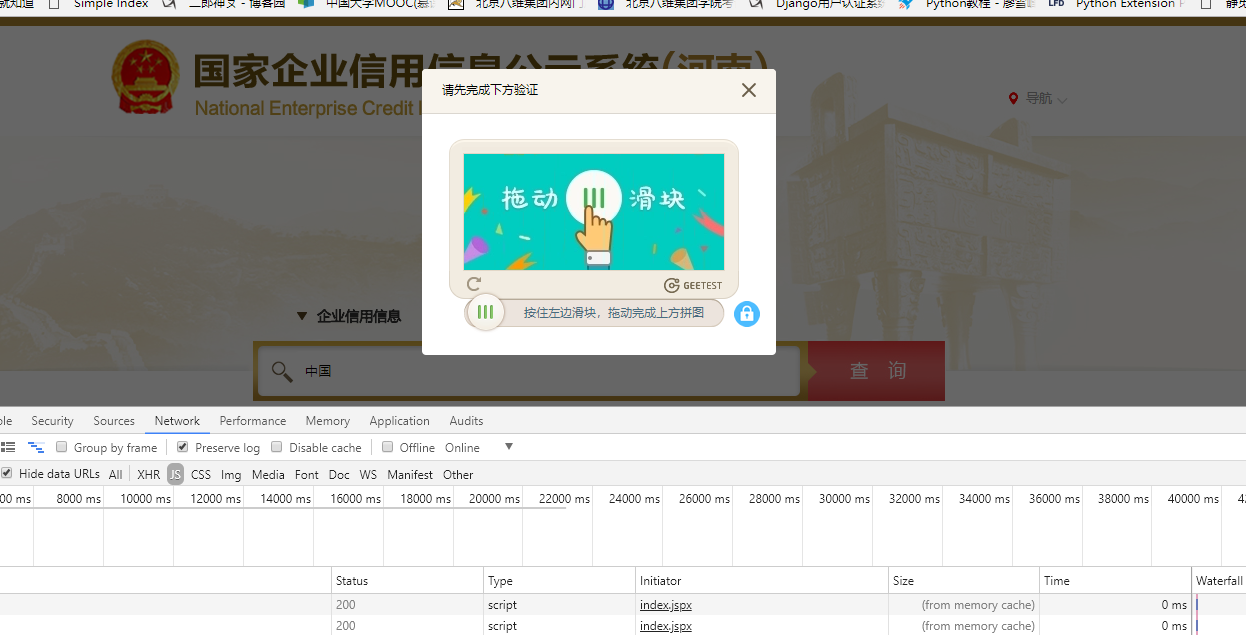
案例分析:河南企业信用信息公示系统的验证流程
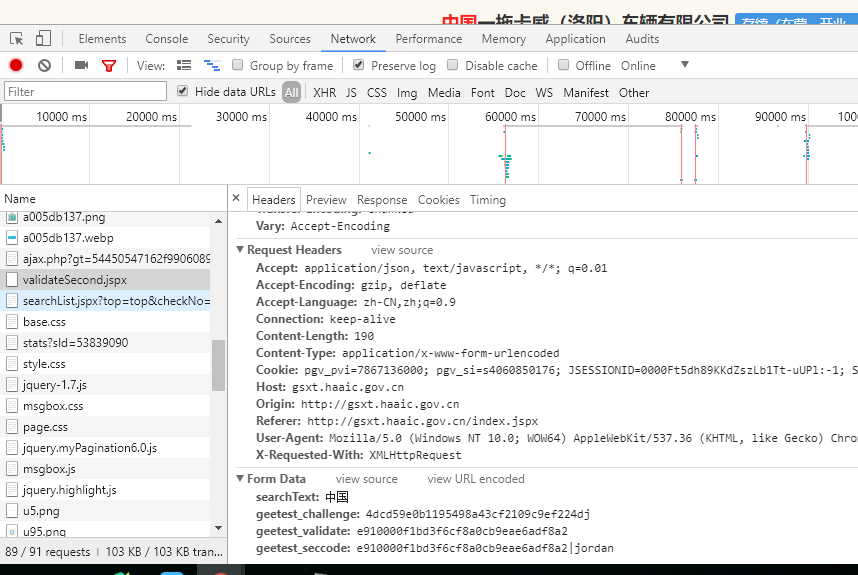
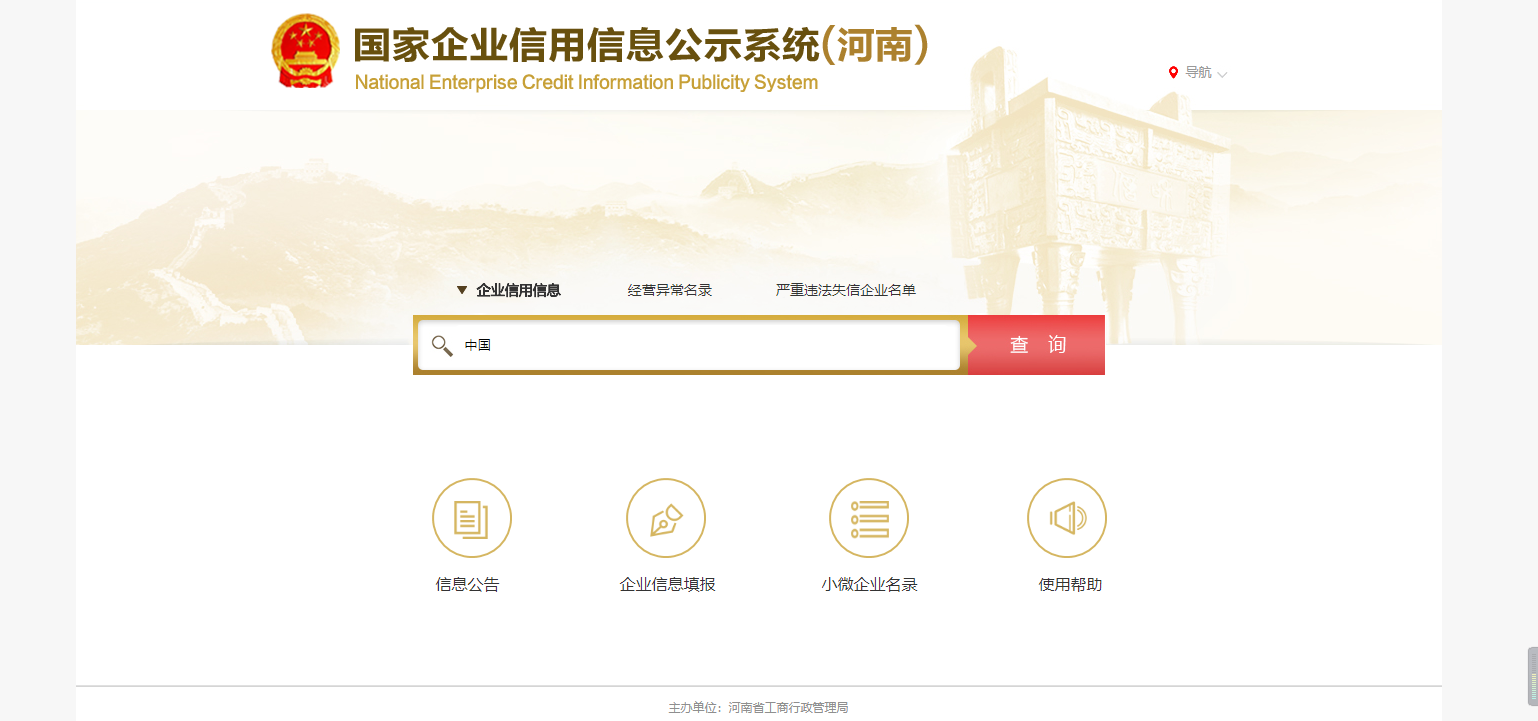
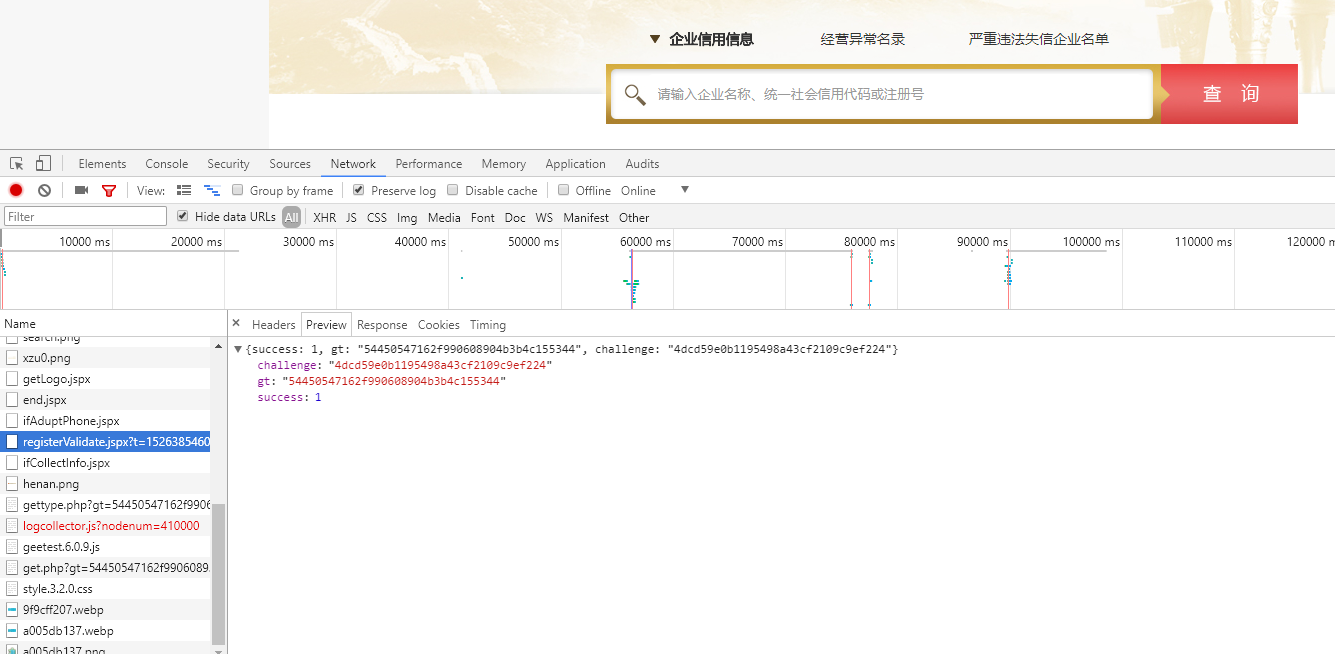
以河南企业信用信息公示系统为例,验证入口位于registerValidate.jspx页面。当用户访问该页面时,系统会返回包含gt参数和challenge参数的HTML内容。接下来,开发者需要通过第三方打码平台完成滑块验证,获取对应的validate和seccode参数。这些参数随后会用于提交到validateSecond.jspx页面,实现数据的提取。
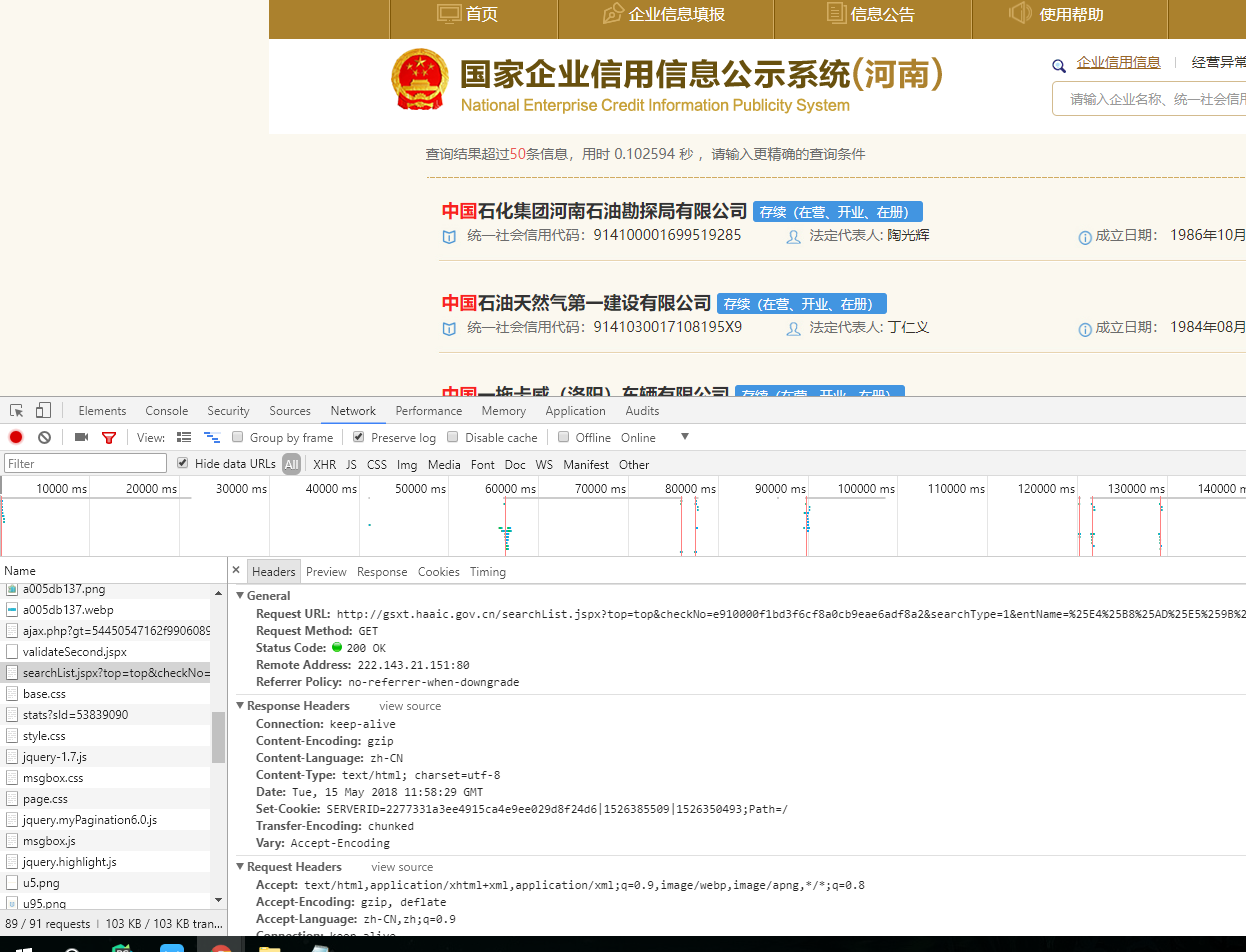
整个流程看似简单,但实际操作中需要注意参数的传递顺序和格式。逆向分析时,可以通过抓包工具观察网络请求的细节,比如GET请求携带的query参数,以及POST请求中的表单数据。理解这些细节有助于我们编写更高效的脚本,避免重复验证。

完整的实现代码示例
import requests
import json
from urllib.parse import quote
class Qy():
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'
}
self.req = requests.session()
def get_html(self, url):
try:
response = self.req.get(url, headers=self.headers)
if response.status_code == 200:
return response.text
return None
except:
print('获取challenge和ht信息失败')
def parse_html(self, html):
html_dic = json.loads(html)
url = "http://jiyanapi.c2567.com/shibie?user=username&pass=123456&return=json&ip=>=" + html_dic['gt'] + "&challenge=" + html_dic['challenge']
return self.get_html(url)
def get_page_html(self, html_json):
url = 'http://gsxt.haaic.gov.cn/validateSecond.jspx'
html_dic = json.loads(html_json)
data = {
'searchText': '中国',
'geetest_challenge': html_dic['challenge'],
'geetest_validate': html_dic['validate'],
'geetest_seccode': html_dic['validate'] + '|jordan',
}
html = self.req.post(url, headers=self.headers, data=data).text
html_di = json.loads(html)
name = quote(quote('中国'))
url1 = 'http://gsxt.haaic.gov.cn/' + html_di['obj'] + '&searchType=1&entName=' + name
return self.req.get(url, headers=self.headers).text
def main():
qy = Qy()
html = qy.get_html('http://gsxt.haaic.gov.cn/registerValidate.jspx')
html_json = qy.parse_html(html)
data = qy.get_page_html(html_json)
print(data)这段代码展示了从初始化会话、获取基础HTML,到解析参数、提交验证,再到最终页面获取的完整流程。每个步骤都经过精心设计,确保数据传递顺畅。开发者可以根据自己的需求调整参数或扩展功能。
常见问题与解决方案
在实际应用中,滑块验证有时会因为网络延迟或参数不匹配而失败。解决办法包括增加请求重试机制、使用代理IP池来模拟真实分布,以及定期更新验证参数的提取逻辑。逆向分析时,建议多次抓包并对比返回的内容,找出固定的模式和可变的元素。
此外,状态码检查和异常捕获也是关键环节。许多初学者容易忽略这些细节,导致脚本运行中断。通过测试不同URL和参数组合,可以逐步完善脚本的稳定性。
技术总结与自动化对接建议
综合来看,极验滑块验证的实现需要结合请求库、JSON解析和动态参数生成等技术。掌握这些基础后,开发者可以轻松处理类似的企业信息系统爬取任务。在面对复杂验证场景时,选择专业的自动化平台可以显著提升效率和成功率。
www.ttocr.com 提供易盾极验验证码识别技术,滑块、点选、无感、九宫格等破解方案和自动化API对接平台,支持无缝集成您的业务需求,让操作更加简单高效。