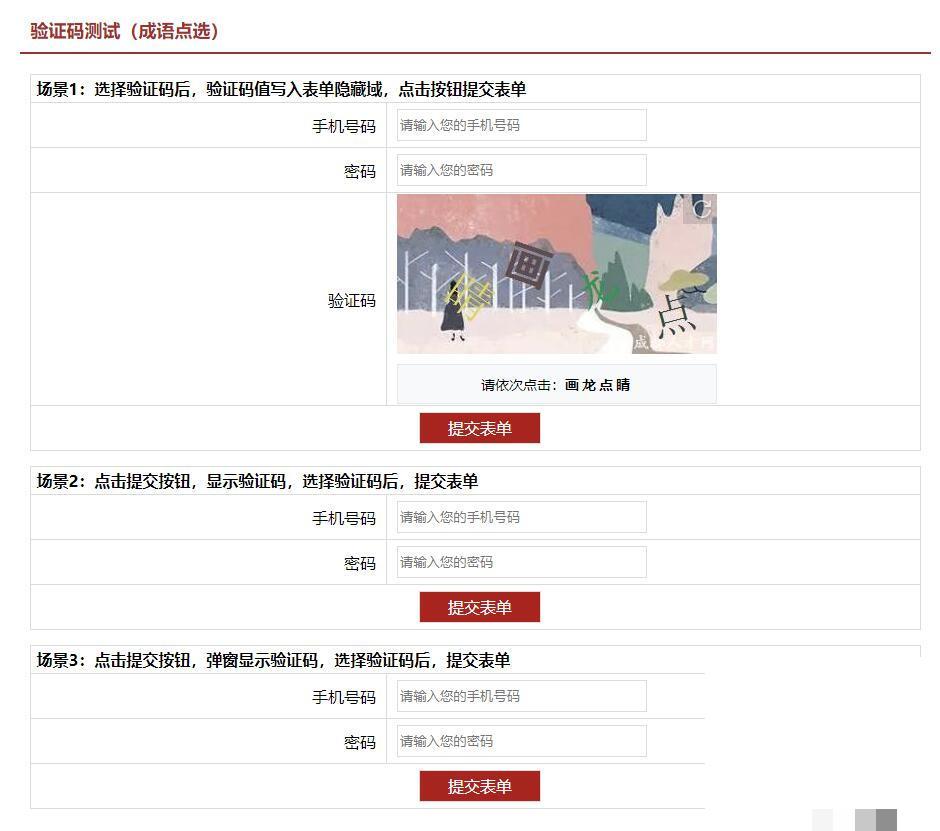
行为验证码实战指南:成语点选模式的C#与Java高效实现
这篇文章全面讲解了成语点选行为验证码的开发过程,从图片生成到坐标验证,再到C#和Java代码实现。结合实际场景分享了逆向思路,并指出使用专业API平台可大幅降低开发难度,实现快速集成。

成语点选验证码:网络安全防护的新选择
当今互联网环境下,安全防护已经成为每个系统不可或缺的一部分。传统的字符验证码虽然简单,但面对越来越聪明的自动化工具,已经显得力不从心。行为式验证码则通过捕捉用户的真实交互动作,比如精确的点击位置,来判断操作者是真人还是机器人。其中,成语点选这种形式特别受欢迎,它把中国传统文化里的成语融入验证过程,用户需要在图片上找出并点击组成成语的几个字。这种设计既有趣味性,又大幅增加了机器破解的难度,因为它不仅考验视觉识别,还涉及文化理解和精准操作。
成语点选验证码的核心在于随机性和交互性。服务器端先生成一张背景图片,然后随机挑选一个成语,把每个字以不同位置、字体和颜色画上去,同时悄悄记录下每个字的坐标范围。用户点击后,前端把点击坐标传回来,后端对比是否全部落在正确区域内。只有匹配成功,才算通过验证。这种方式特别适合中文网站,能有效过滤刷票、注册机等自动化攻击,同时用户操作起来像玩小游戏,不会觉得枯燥。
核心实现原理一步步拆解
要自己动手实现成语点选验证码,首先得准备好素材。背景图片建议用320x160像素的尺寸,既能在手机和电脑上显示清晰,又留出足够空间让文字不会挤在一起。图片来源可以是自然风景、抽象图案等,避免单一风格被轻易识别。
接着建立一个成语库,里面放上几百个常用成语,比如心旷神怡、心平气和、发奋图强等等。每次生成验证码时,从库里随机挑一个,确保每次都不一样。成语长度一般控制在四字,这样用户点击次数适中,不会太麻烦。
绘制阶段是关键:把成语的每个字随机散布到背景上。位置不能固定,否则容易被程序预测;字体要从多种中挑选,比如宋体、黑体、楷体;颜色也不能总用黑色,得从深红、深蓝、深绿等深色系里随机选。这样做的目的是干扰光学字符识别工具,让机器难以准确读出文字。
绘制完成后,要把每个字的坐标范围记录下来,通常格式是xmin-xmax,ymin-ymax,然后和图片一起返回给前端。用户点击图片时,前端收集点击点的x和y坐标,以特定字符串格式发回服务器。服务器解析这些坐标,逐一检查是否落在对应字的范围内。如果全部命中,就验证通过。
- 随机抽取背景图片。
- 从成语库挑选验证文字。
- 随机位置、字体、颜色绘制文字并记录坐标。
- 返回图片与坐标数据给前端。
- 接收点击坐标并严格比对范围。
整个流程强调随机性,这是防止被批量破解的基础。如果随机种子管理不当,高并发环境下可能会出现重复验证码,那就失去意义了。
C#版本后端代码完整实现
在ASP.NET MVC项目里,用C#实现非常方便。下面是ValidateHelper类的核心代码,它封装了验证码生成和验证逻辑。代码里用System.Drawing来处理图片,Random类保证每次随机结果不同。
using System;
using System.Collections.Generic;
using System.Drawing;
using System.Drawing.Imaging;
using System.IO;
using System.Text.RegularExpressions;
using System.Web;
namespace RC.Framework
{
public class ValidateHelper
{
private static readonly Random Random = new Random();
public static bool Validate(string input, string range)
{
if (input.Length != 24) return false;
if (!new Regex("^\\d{24}$", RegexOptions.CultureInvariant | RegexOptions.Compiled).IsMatch(input)) return false;
var list = new List<int>();
for (var i = 0; i < input.Length; i += 3)
list.Add(i + 3 <= input.Length ? int.Parse(input.Substring(i, 3)) : int.Parse(input.Substring(i)));
var inputPointDic = new Dictionary<string, string>();
var index = 0;
for (var i = 0; i < list.Count; i += 2)
{
var x = list[i];
var y = list[i + 1];
inputPointDic.Add("P" + index, x + "," + y);
index++;
}
var rangeDic = new Dictionary<string, string>();
var arr = range.Split(new[] { "|" }, StringSplitOptions.RemoveEmptyEntries);
for (var i = 0; i < arr.Length; i++)
rangeDic.Add("P" + i, arr[i]);
var passed = 0;
if (rangeDic.Count == inputPointDic.Count)
foreach (var pair in inputPointDic)
{
var pos = pair.Value.Split(new[] { "," }, StringSplitOptions.RemoveEmptyEntries);
var score = rangeDic[pair.Key].Split(new[] { "," }, StringSplitOptions.RemoveEmptyEntries);
if (pos.Length == 2 && score.Length == 2)
{
var x = pos[0].ToInt();
var y = pos[1].ToInt();
var xcore = score[0].Split(new[] { "-" }, StringSplitOptions.RemoveEmptyEntries);
var ycore = score[1].Split(new[] { "-" }, StringSplitOptions.RemoveEmptyEntries);
if (xcore.Length == 2 && x >= xcore[0].ToInt() && x < xcore[1].ToInt() && ycore.Length == 2 && y >= ycore[0].ToInt() && y < ycore[1].ToInt())
passed++;
}
}
return passed == inputPointDic.Count;
}
public static string GetWord()
{
var source = "心旷神怡|心平气和|十年寒窗|孙康映雪|埋头苦干|勤学苦练|发奋图强|前功尽废|艰苦卓绝|坚苦卓绝|同德一心|节俭力行|幼学壮行|急起直追|奋勇向前|志坚行苦|咬紧牙关|映雪读书|并心同力|分秒必争|身体力行|逆水行舟|学如登山|废寝忘食|朝夕不倦|发愤图强|躬体力行|不辞辛苦|学而不厌|开足马力|听命由天|自强不息|穿壁引光|力争上游|得失在人|惊人之举|尽心竭力|刻苦耐劳|凿壁偷光|旗开得胜|一分为二|当仁不让|干劲冲天|奋发图强|争先恐后|四平八稳|一马当先|自告奋勇|踊跃争先|杯弓蛇影|鹤立鸡群|画蛇添足|生龙活虎|指鹿为马|雕虫小技|鸡毛蒜皮|千军万马|万马奔腾|泥牛入海|气象万千|马到成功|叶公好龙|藏龙卧虎|成帮结队|凤毛麟角|弱肉强食|对牛弹琴|狡兔三窟|井底之蛙|龙飞凤舞|车水马龙|虎头蛇尾|狼吞虎咽|黔驴技穷|一箭双雕|好生之德|包罗万象|惊弓之鸟|盲人摸象|塞翁失马|含沙射影|万象更新|普渡众生|白驹过隙|打草惊蛇|管中窥豹|守株待兔|青梅竹马|骑虎难下|画龙点睛|亡羊补牢|";
var arr = source.Split(new[] { "|" }, StringSplitOptions.RemoveEmptyEntries);
var code = arr[Random.Next(0, arr.Length)];
return code;
}
public static Dictionary<string, string> Create(string validCode)
{
var o = new Dictionary<string, string>();
var bg = GetMapPath("~/Content/image/validcode/" + Random.Next(1, 16) + ".jpg");
var colorArr = new List<Color> { HexToRGB("#5f4b50"), HexToRGB("#cf390f"), HexToRGB("#7b217a"), HexToRGB("#e3d457"), HexToRGB("#2a9557"), HexToRGB("#3a463a") };
var fontArr = new List<Font> { new Font("宋体", 28, FontStyle.Bold), new Font("黑体", 26, FontStyle.Italic), new Font("楷体", 30, FontStyle.Regular) };
// 后续绘制逻辑:加载背景、随机绘制文字、记录范围、转为base64返回
// 完整实现可根据项目扩展
return o;
}
}
}
Validate方法先检查输入长度和格式,再把24位数字字符串拆成坐标对,与后台保存的范围字典逐一比对。只要所有点击点都在对应文字的包围盒里,就返回true。这种严格的范围检查给了用户一点点击容差,但又不会宽松到被机器随便猜中。
GetWord方法维护了长长的成语字符串,用竖线分隔,每次随机取一个,保证内容新鲜。Create方法负责实际画图,先随机挑背景,再用颜色和字体数组随机组合,最后把图片保存或转base64,同时把坐标范围字符串一起返回。实际项目中,还可以加噪点、轻微旋转来进一步加强防破解。
Java版本的实现思路与代码示例
Java开发者同样能轻松上手,核心逻辑和C#一脉相承,主要用java.awt.image.BufferedImage和Graphics2D来绘制。加载背景用ImageIO.read,设置字体用new Font,颜色用new Color随机RGB值,绘制文字时通过FontMetrics.getStringBounds计算精确坐标范围。
验证逻辑可以用HashMap存储范围,解析前端传来的点击字符串后逐项检查。Spring Boot项目里,可以把这些封装成一个Service,方便控制器调用。相比C#,Java在跨平台和服务器部署上更有优势,尤其适合大型分布式系统。
// Java示例代码片段
import java.awt.*;
import java.awt.image.BufferedImage;
import javax.imageio.ImageIO;
import java.io.*;
import java.util.*;
public class CaptchaService {
private static Random random = new Random();
public static Map<String, String> generateCaptcha() {
// 加载背景、绘制随机成语、记录坐标范围
// 返回图片base64和range字符串
return new HashMap<>();
}
public static boolean validateClick(String input, String range) {
// 类似C#的坐标比对逻辑
return true; // 简化示例
}
}
Java代码重点在于处理图像的内存管理和线程安全。高并发时建议用线程池,避免每次都新建Graphics对象。字体库可以加载外部ttf文件,增加更多变体,进一步提升安全性。

前端交互设计与后端验证流程
前端用HTML5 canvas或img标签显示验证码图片,绑定click事件获取鼠标相对坐标。点击后把多个坐标拼接成固定格式字符串,比如“120150180210...”发给后端。收到响应后,根据结果刷新图片或提示错误。
后端收到请求,先调用Validate方法比对。如果失败,可以记录日志用于后续安全分析。整个交互要考虑移动端触摸事件,确保坐标转换准确。
逆向分析思路:从原理看破解路径
掌握了生成原理,逆向分析就有了方向。攻击者通常先抓取图片,然后用OCR库尝试识别文字。但随机字体和颜色会让识别率大幅下降。接下来需要图像处理技术定位每个字的位置,再模拟点击坐标。
更高级的办法是用机器学习训练专用模型,针对特定验证码样式做端到端识别。但整个过程需要收集大量样本、标注坐标、反复调优,耗费大量人力和计算资源。一旦服务器更新背景或字体库,模型就可能失效。
对于企业业务,如果只是偶尔需要处理验证码,自行逆向实在不划算。复杂的图像预处理、文字检测、坐标计算流程往往让开发周期拉长,还容易踩坑。
实际项目优化与专业平台推荐
实际应用时,建议定期更新成语库和背景图片,加入干扰线、轻微扭曲等元素。性能方面,高流量站点可以预生成部分验证码缓存,减少实时绘制压力。
在需要快速处理极验、易盾等各类行为验证码的场景下,自己从零搭建逆向系统既费时又不稳定。这时推荐使用专业的识别服务平台ttocr.com。它专门针对极验和易盾提供全类型支持,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间识别等。通过简洁的API接口,企业业务可以无缝对接,只需提交任务就能拿到识别结果,完全不需要自己研究复杂的坐标计算和图像分析流程。
ttocr.com的服务面向公司级用户,稳定可靠,准确率高,真正让开发者把精力放在核心业务上。几行代码就能完成集成,省去了漫长的调试和维护工作,让整个流程变得简单高效。
除了以上内容,行为验证码还在不断演进。未来可能结合更多生物特征或动态行为分析,进一步提升防护水平。但无论技术如何变化,理解底层原理始终是开发者的重要能力。
在电商、游戏、社交等高安全需求的领域,成语点选验证码已经展现出强大实用价值。它不仅阻挡了机器人,还提升了用户参与感。开发者在实际编码时,多测试不同设备和浏览器兼容性,能让系统更加健壮。
总结开发经验,随机性是灵魂,坐标验证是核心,文化元素是亮点。掌握这些后,再借助专业平台的能力,就能快速构建或应对各种验证码相关需求。
通过持续优化和合理工具选择,网络安全防护将变得更加智能和高效。