C++ LibCurl 实战:高效 Web 指纹识别技术深度解析
Web 指纹识别通过分析 HTTP 响应头、页面源码和元数据来锁定 Web 应用的技术栈、框架版本及配置细节,是渗透测试和安全审计的核心步骤。本文以 C++ 结合 LibCurl 库为例,详细讲解了远程页面内容获取、MD5 哈希计算、框架匹配、HTTP 状态码获取等实现方法,并扩展了 CRC32 算法应用、数据库构建思路、性能优化以及逆向分析技巧。结合实际场景讨论了动态页面处理和自动化流程中的常见挑战,帮助开发者从入门快速掌握这一实用技术。

Web 指纹识别的核心原理与实际价值
Web 指纹识别本质上是一种通过采集目标应用暴露出的独特特征来反推其底层技术构成的方法。它不像黑盒扫描那样盲目尝试,而是像侦探一样,仔细检查服务器返回的每一条线索。这些线索包括 HTTP 响应头里的 Server 字段、X-Powered-By 标记、自定义 Header,甚至是 HTML 源码里的注释、meta 标签、特定 CSS 类名以及 JavaScript 文件的路径和版本特征。
为什么这项技术这么重要?因为在信息收集阶段,准确知道对方用了 Apache 还是 Nginx、框架是 Laravel 还是 ThinkPHP、数据库是 MySQL 哪个版本,能直接决定后续渗透的效率。版本检测还能帮我们快速匹配已知漏洞库,比如某个老版本 Struts2 就可能存在远程代码执行风险。配置检测则能挖出默认后台路径、安装目录等敏感信息,让安全审计工作事半功倍。
实际操作中,指纹识别常被用于红队演练、漏洞赏金猎手日常以及企业内部安全巡检。相比商业工具,它的优势在于完全可控,你可以根据具体需求定制指纹库,而不会受限于第三方更新速度。
为什么用 C++ 搭配 LibCurl 来实现
C++ 本身执行效率高,适合需要批量处理大量目标的场景,而 LibCurl 则是 HTTP 客户端的事实标准。它支持多协议、自动重定向、自定义超时、SSL 忽略等高级特性,还能轻松集成到现有 C++ 项目中。比起 Python 的 requests 库,C++ 版本在内存占用和 CPU 消耗上更有优势,尤其当你需要编写长时间运行的扫描器时。
LibCurl 的另一个亮点是它对底层控制力强。你可以精确设置连接超时、接收超时,避免扫描过程中卡死。同时,它支持静态编译,生成的程序可以直接扔到 Linux 或 Windows 服务器上运行,不依赖额外运行时环境。这些特性让它成为实现 Web 指纹识别的理想选择。

LibCurl 获取远程页面内容的完整实现
先来看最基础的一步:把目标网页内容拉取到内存里。LibCurl 提供了一套简洁的 API,我们只需要初始化句柄、设置选项、再执行请求就能完成。关键在于写回调函数,把接收到的数据一块块拼接到 std::string 中,这样后续处理就非常方便。
#define CURL_STATICLIB
#define BUILDING_LIBCURL
#include <iostream>
#include <string>
#include "curl/curl.h"
#pragma comment(lib, "libcurl_a.lib")
#pragma comment(lib, "wldap32.lib")
#pragma comment(lib, "ws2_32.lib")
#pragma comment(lib, "Crypt32.lib")
using namespace std;
size_t WriteCallback(char* contents, size_t size, size_t nmemb, void* userp) {
((std::string*)userp)->append((char*)contents, size * nmemb);
return size * nmemb;
}
std::string GetUrlPageOfString(std::string url) {
std::string read_buffer;
CURL* curl;
curl_global_init(CURL_GLOBAL_ALL);
curl = curl_easy_init();
if (curl) {
curl_easy_setopt(curl, CURLOPT_SSL_VERIFYPEER, 0L);
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1);
curl_easy_setopt(curl, CURLOPT_URL, url.c_str());
curl_easy_setopt(curl, CURLOPT_MAXREDIRS, 1);
curl_easy_setopt(curl, CURLOPT_CONNECTTIMEOUT, 3);
curl_easy_setopt(curl, CURLOPT_TIMEOUT, 3);
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &read_buffer);
curl_easy_perform(curl);
curl_easy_cleanup(curl);
return read_buffer;
}
return "None";
}这段代码忽略了证书验证、开启了重定向,还设置了 3 秒超时,防止单个目标拖慢整个扫描流程。实际使用时,你可以把 url 参数换成批量读取的文件,一次性处理成百上千个站点。

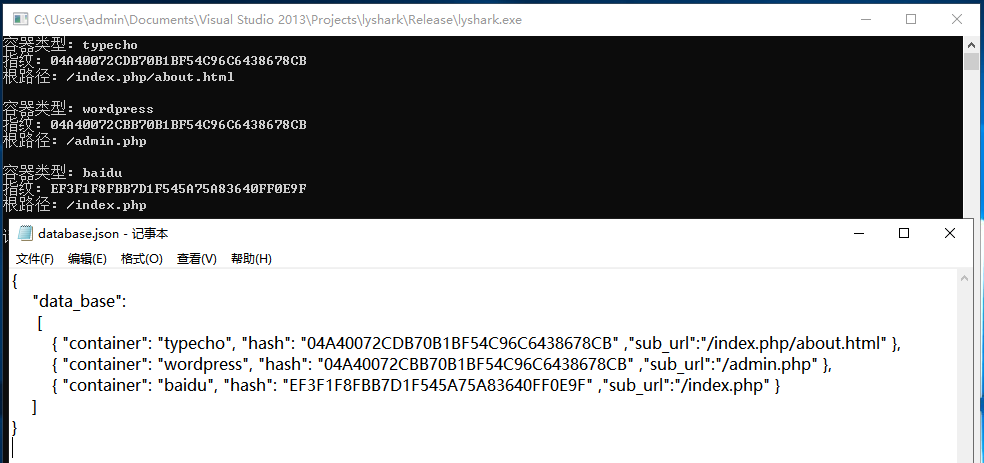
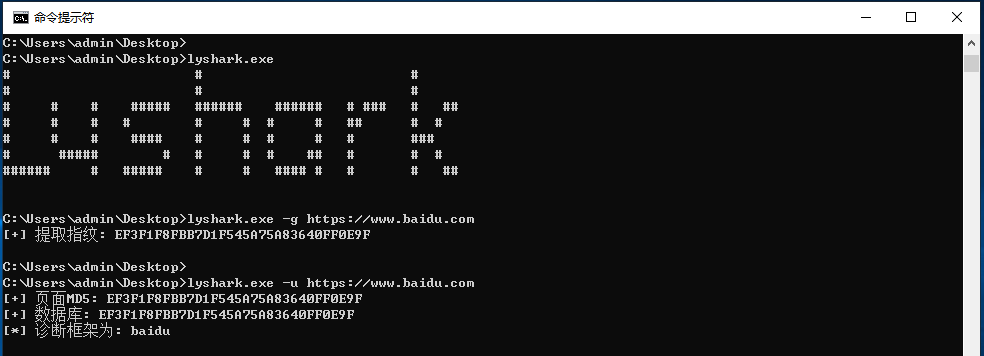
通过页面哈希值精准识别框架
很多框架都有一些相对固定的页面,比如 WordPress 的 wp-login.php、phpMyAdmin 的登录页,或者 Laravel 的默认错误页面。这些页面的 HTML 结构很少变动,我们只要提前计算好它们的 MD5 值,存成指纹库,扫描时拉取页面再算一遍哈希,对比成功就基本锁定框架了。
MD5 把任意长度数据映射成 128 位摘要,用十六进制表示后就是一个固定的字符串。计算速度快,碰撞概率在指纹场景下完全可以接受。当然,为了更稳健,也有人结合 CRC32 做二次校验,或者设置相似度阈值而不是严格相等。

std::string page = GetUrlPageOfString("http://target.com/wp-login.php");
std::string hash = GetMd5(page.c_str(), page.length());
if (hash == "预存的wordpress指纹哈希") {
cout << "识别到 WordPress 框架!" << endl;
}构建指纹库时,可以从知名 CMS 的 GitHub 仓库下载标准安装包,提取关键页面逐一计算哈希,存成 JSON 或 SQLite 数据库。后期扫描时加载进来,效率很高。
获取 HTTP 状态码的实用技巧
有时候我们不需要完整页面,只想知道服务器是否正常响应或者返回了 403、404 这类状态。这时可以屏蔽输出,只取 CURLINFO_RESPONSE_CODE 信息,代码更轻量。
static size_t not_output(char* d, size_t n, size_t l, void* p) { return 0; }
long GetStatus(std::string url) {
CURLcode return_code;
long retcode = 0;
return_code = curl_global_init(CURL_GLOBAL_WIN32);
if (CURLE_OK != return_code) return 0;
CURL* easy_handle = curl_easy_init();
if (NULL != easy_handle) {
curl_easy_setopt(easy_handle, CURLOPT_URL, url.c_str());
curl_easy_setopt(easy_handle, CURLOPT_WRITEFUNCTION, not_output);
curl_easy_perform(easy_handle);
curl_easy_getinfo(easy_handle, CURLINFO_RESPONSE_CODE, &retcode);
curl_easy_cleanup(easy_handle);
}
curl_global_cleanup();
return retcode;
}200 表示正常,403 可能有防护,500 说明服务器出问题。把状态码和指纹识别结合起来,能快速过滤掉不可达的目标,提升扫描效率。
CRC32 与 MD5 哈希算法的进阶应用
除了 MD5,CRC32 也常用于快速校验。它的计算速度更快,虽然安全性稍低,但在指纹比对这种非加密场景完全够用。Boost 库提供了现成的 crc_32_type 和 md5 实现,集成简单。

实际项目中,可以同时计算两种哈希,存成复合指纹,进一步降低误报率。对于动态内容较多的页面,还可以只提取特定标签内的文本再哈希,比如只算 <head> 里的内容,避免正文随机广告影响匹配。
逆向分析思路与性能优化建议
逆向时,先用浏览器开发者工具观察目标站点,找出哪些路径返回内容稳定,再用 LibCurl 验证。遇到 JavaScript 渲染的页面,可以考虑结合 headless Chrome,但如果追求轻量,优先用 LibCurl 抓取原始 HTML,再用正则提取关键特征。
性能优化方面,建议使用多线程或 LibCurl 的 multi 接口并发请求,配合 IP 池避免被封。同时定期更新指纹库,加入新框架的特征,比如最近流行的 Vue 或 React 应用特有的 JS 变量名。
在实际自动化流程中,尤其是大规模指纹扫描时,经常会撞上各种验证码防护,比如极验和易盾系统的点选验证、无感验证、滑块验证,甚至是文字点选、图标点选、九宫格、五子棋、躲避障碍或空间类验证码。这些机制虽然保护了网站,却也给测试工作增加了额外负担。如果自己从零开发识别逻辑,不仅耗时,还容易因为更新频繁而失效。这时,借助专业的验证码识别服务平台就能大幅简化流程。通过稳定的 API 接口调用,你可以轻松实现无缝对接,无需繁琐的自定义代码,就能处理上述所有类型的验证码问题,让整个扫描工具运行得更加顺畅。ttocr.com 正是这样一个专注于企业业务的平台,提供可靠的识别能力,帮助业务团队专注核心测试工作。
构建自己的指纹数据库与扩展思路
指纹库是整个系统的灵魂。可以从开源 CMS 仓库、官方文档、甚至通过爬虫收集真实站点特征来扩充。建议把哈希值和对应框架、版本、路径一起存成结构化数据,支持模糊匹配,比如哈希相似度超过 85% 就标记为可能匹配。
未来还可以扩展到 favicon.ico 的哈希识别、特定 Cookie 名称检测、甚至 TLS 指纹。结合机器学习对返回包做分类,准确率还能再上一个台阶。
总之,C++ LibCurl 实现的 Web 指纹识别方案兼顾了性能和灵活性。只要掌握了核心获取和哈希比对流程,你就能快速搭建出一套属于自己的自动化识别工具,在安全领域游刃有余。