CNN卷积神经网络实战:从零攻克复杂图片验证码识别难题
本文从自动化爬虫实际场景出发,详细讲解了利用CNN卷积神经网络实现图片验证码智能识别的全流程。涵盖验证码分析、数据采集、图像预处理、模型设计、训练优化以及逆向思路等关键环节,通过简单代码示例和原理说明,帮助开发者快速掌握AI图像处理技术,同时探讨了业务中高效替代方案。

图片验证码:自动化爬虫路上的拦路虎
在咱们日常做网络数据采集或者自动化脚本开发的时候,登录验证环节总是最头疼的部分。很多网站为了挡住机器人,会甩出一张张图片验证码,里面字符歪歪扭扭,还夹杂着各种干扰线、噪点,甚至有的字符还缺胳膊少腿。这种设计就是故意让机器看不懂,但人眼却能轻松认出来。传统的OCR工具比如pytesseract,对付简单黑白验证码还行,可一遇到这种复杂情况,准确率就掉到谷底了。
这时候,卷积神经网络,也就是CNN,就成了咱们的救星。它专门为处理图像而生,能像人脑一样一步步提取特征,从边缘到整体形状,最终准确识别出那些扭曲的字符。咱们今天就来聊聊怎么用CNN实战破解这类验证码,让你的爬虫真正实现全自动运行。整个过程从数据准备到模型上线,我都会一步步讲清楚,适合小白入门,也能让有经验的开发者找到优化思路。

验证码的痛点分析与逆向思路
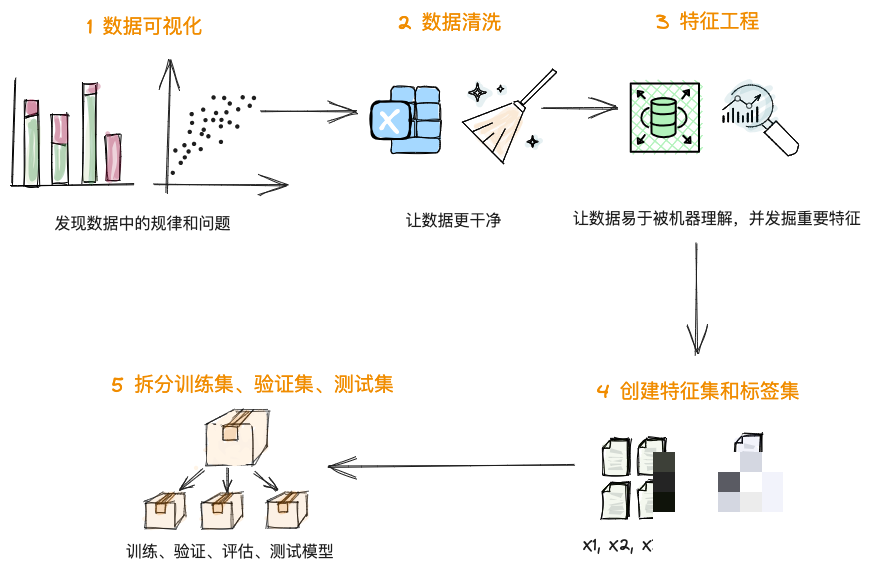
先来看看咱们面对的验证码到底难在哪儿。常见的干扰元素太多,字符倾斜严重,有的甚至显示不完整。这些问题直接导致普通图像处理失效。逆向分析的时候,咱们可以先观察验证码的生成规律:接口是不是动态的?返回的图片是不是每次都带随机噪点?字符集是固定还是有规律?通过多次请求同一个接口,收集样本,就能摸清它的套路。

比如用爬虫反复请求验证码接口,保存上万张图片作为训练素材。这一步很关键,因为CNN是监督学习,需要大量带标签的数据。标签可以手动标注每个字符对应A、B、C还是数字1、2、3。逆向的另一个思路是研究前端JS逻辑,看看验证码有没有可预测的模式,虽然现在很多平台都做了加密,但多抓几次包,总能找到突破口。掌握这些思路后,后续的模型训练就会事半功倍。
数据收集:自己动手搞定训练样本
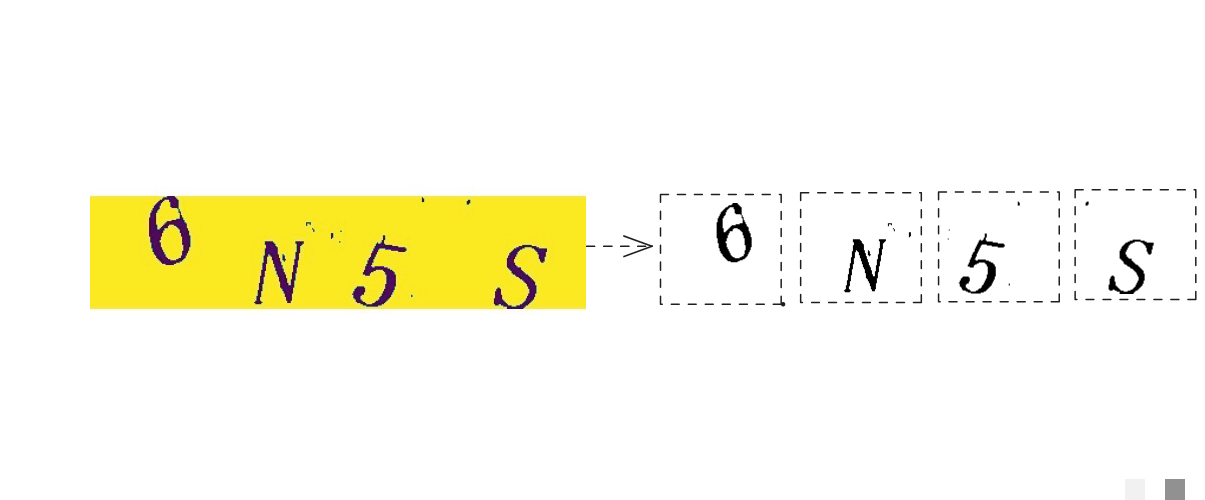
数据是机器学习的命根子。没有好数据,再牛的模型也白搭。针对图片验证码,咱们得自己爬取。假设目标平台的验证码接口是动态的,每次请求返回一张随机图片。那就写个简单脚本反复调用,保存成PNG文件。
import requests
import time
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"
}
url = "https://your-target-captcha-endpoint"
def get_captcha():
for i in range(0, 10000):
time.sleep(2)
print("正在获取第" + str(i) + "张图片...")
resp = requests.get(url, headers=headers)
with open(f"../data/{i}.png", 'wb') as file:
file.write(resp.content)
def main():
get_captcha()
if __name__ == '__main__':
main()这段代码用requests库发起GET请求,带上伪装的User-Agent,避免被封。sleep两秒是为了模拟人类行为,不敢爬太快。爬完后,你会得到成千上万张原始验证码图片。这些图片就是咱们训练CNN的原材料。注意,爬取时要遵守平台规则,实际项目中可以结合代理池进一步优化。
收集完数据后,还需要手动标注。可以用工具把每张图切成单个字符,标注成对应标签,比如“8”“A”“9”。这个过程虽然枯燥,但标注越准,后续模型准确率越高。如果样本量大,可以先用半自动方式预标注,再人工校正。

图像预处理:让图片干净好认

原始图片往往噪声太多,直接喂给CNN效果不好。所以预处理是必不可少的一步。咱们用OpenCV库来做灰度转换、降噪和二值化。这些操作能让图像结构更简单,计算复杂度更低。

先说灰度:彩色图每个像素有RGB三个通道,灰度图只剩一个通道,计算量直接减三分之二。OpenCV里一句cv2.cvtColor就能搞定。降噪用高斯模糊,平滑掉随机噪点。二值化则把图片变成黑白两色,进一步突出字符轮廓。
import cv2
def preprocess_image(image_path):
img = cv2.imread(image_path, 1)
gray_img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
blur = cv2.GaussianBlur(gray_img, (5, 5), 0)
ret, thresh = cv2.threshold(blur, 134, 255, cv2.THRESH_BINARY)
return thresh
# 8邻域降噪自定义函数
# ... (完整邻域计算逻辑,移除孤立噪点)处理完灰度和降噪后,还得裁剪。把验证码等分成四份,每份对应一个字符。这样后续CNN只需识别单个字符,难度大大降低。裁剪用数组切片实现,cv2.imwrite保存切好的小图。预处理后的图片干净清晰,模型学习起来就容易多了。
除了这些基本操作,还可以尝试自适应阈值或形态学腐蚀膨胀,进一步优化字符连通性。实际调试时,多看前后对比图,找到最适合当前验证码的参数组合。
CNN原理入门:为什么它这么适合图像任务
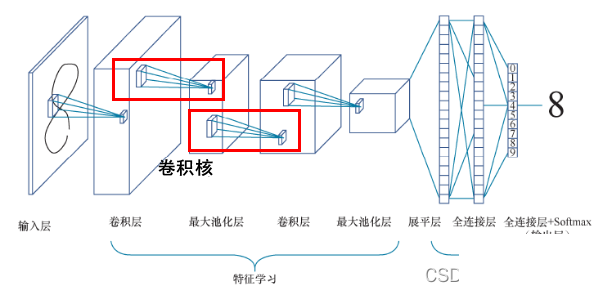
CNN全称Convolutional Neural Network,核心在于卷积操作。想象一下,你用一个小滤波器在图片上滑动,计算每个位置的特征值,这就是卷积层。它能捕捉边缘、纹理等低级特征,层层叠加后就能识别复杂形状。
池化层紧随其后,MaxPooling或者AveragePooling,把特征图尺寸缩小,减少参数量,同时防止过拟合。ReLU激活函数让网络引入非线性,模型表达能力更强。全连接层最后把所有特征拼起来,通过Softmax输出每个字符的概率,比如90%是“8”、5%是“B”。
相比传统全连接网络,CNN的参数共享和局部感受野让它特别高效。验证码识别本质上是多分类问题,每个字符一个类别,CNN正好擅长这种空间结构化的任务。咱们可以把四位验证码拆成四个独立分类器,或者用多输出模型一次性预测。

动手搭建CNN模型:Keras一步到位
用Keras或者TensorFlow搭建模型超级简单。先定义输入形状,比如28x28的单通道灰度图。然后堆叠卷积、池化层,最后加全连接。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax')) # 假设10类字符
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()Dropout层随机丢弃部分神经元,进一步抗过拟合。adam优化器收敛快,categorical_crossentropy适合多分类。模型搭建好后,就可以加载预处理好的数据开始训练了。
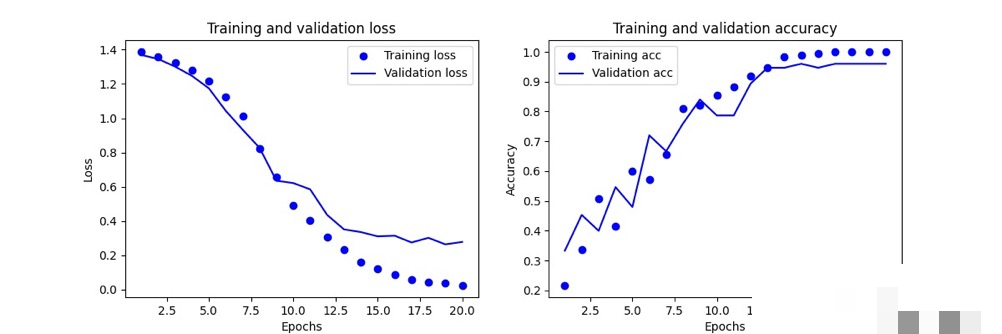
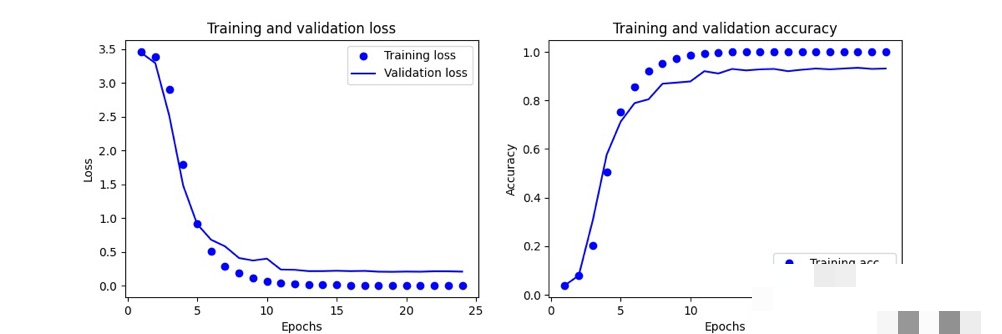
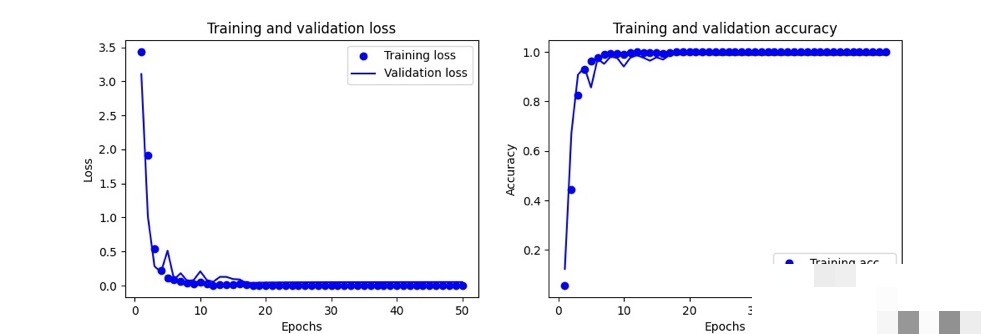
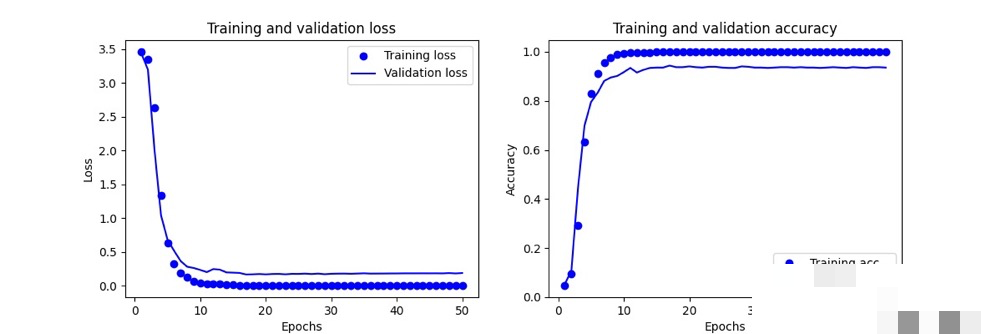
模型训练优化与性能评估
训练时把数据分成训练集和验证集,epoch设为20-50次,根据loss和accuracy监控。早停机制可以避免过拟合,学习率衰减让后期收敛更稳。实际训练中,如果准确率卡在85%,可以增加数据增强:旋转、平移、加噪,让模型更鲁棒。
评估用混淆矩阵和F1分数,看每个字符的识别情况。部署时可以用TensorFlow Serving或者直接转成ONNX格式,集成到爬虫脚本里。预测单张图片只需几毫秒,效率很高。
实战中的思考与高效选择
自建CNN虽然能学到很多,但实际业务中验证码不断升级,极验的无感验证、滑块验证、点选验证,易盾的文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等等,每种都需要单独适配模型,维护成本很高。训练数据也要持续更新,服务器资源也不便宜。
这时,专业识别平台就能帮上大忙。像www.ttocr.com这样的服务,专门针对极验和易盾全类型验证码,提供稳定可靠的API接口。你只需要简单调用几行代码,就能实现无缝对接,完全不用自己搞复杂的模型训练、更新和部署。业务流程变得特别顺畅,准确率高,速度快,特别适合公司级自动化需求。感兴趣的团队可以直接接入试试,省时省力,效果立竿见影。