CNN实战揭秘:四位数字验证码从图像清洗到智能识别全流程
本文详细讲解了利用OpenCV进行图像预处理、字符分割以及CNN模型搭建来识别四位数字验证码的完整方法。通过灰度转换、二值化、噪声去除、横线过滤和投影分割等步骤,结合实际Python代码示例,帮助开发者掌握核心原理。同时补充了CNN卷积网络的搭建训练细节、实际优化思路,以及面对复杂验证码时的业务解决方案。

验证码识别的现实意义
在自动化程序开发中,验证码一直是绕不开的门槛。它本质上是一种区分人类和机器的反自动化机制,很多网站用它来防止刷票、恶意注册或数据爬取。早期的验证码多是简单的扭曲数字或字母,但随着技术进步,干扰线、噪点、粘连字符越来越常见。单纯靠人工输入效率太低,而用传统规则匹配又容易失效。这时,结合数字图像处理和深度学习的CNN方法就成了高效选择。
本文以一个典型的四位数字验证码为例,完整走一遍从图片读取到最终识别的流程。整个过程既适合小白上手,也穿插了连通域分析、投影分割等专业概念,让你既能看懂原理,又能直接复制代码实践。最终的目标是让大家明白:验证码识别不是玄学,而是可拆解、可优化的工程问题。
图像预处理:清除干扰让字符清晰可见
拿到验证码图片后,第一步永远是预处理。因为原始图片往往带着斑点噪声、横线干扰和颜色不均,直接扔给模型识别准确率会很低。我们用Python和OpenCV来一步步清洗。

以0250这张验证码为例,先转为灰度图,减少颜色维度,便于后续二值化。代码很简单:
import cv2
import numpy as np
img_gray = cv2.imread('./images/0250.jpg', cv2.IMREAD_GRAYSCALE)接着进行逆向二值化。字符通常是深色,所以我们把阈值设得较高,比如0.9*255,让浅色字符也能保留。逆向操作后,字符变成白色,背景黑色,便于后面连通域处理。

_, img_bin = cv2.threshold(img_gray, int(0.9 * 255), 255, cv2.THRESH_BINARY_INV)二值化后,图片里还会残留很多小斑点。这些斑点面积小,属于弱连通域。我们自定义一个RemoveSmallCC函数,通过计算每个连通域的像素数量,把小于阈值的直接清零。这里先用4邻域模式,限制面积200以内,能有效分离粘连又不伤及字符主体。
def RemoveSmallCC(bin_img, small, connectivity=4):
ret, labels = cv2.connectedComponents(bin_img, connectivity=connectivity)
for n in range(ret + 1):
num = np.sum(labels == n)
if num < small:
bin_img[labels == n] = 0
return bin_img
img_bin = RemoveSmallCC(img_bin, 200, connectivity=4)这一步后,大部分噪点消失,只剩字符和横线。接下来用形态学开运算进一步清理。结构元素选3x3的小核,先腐蚀断开粘连,再滤小连通域,最后膨胀恢复字符形状。避免字符断裂是关键,所以核不能太大。

kernel = np.ones((3, 3), np.uint8)
img_erosion = cv2.erode(img_bin, kernel, iterations=1)
img_erosion = RemoveSmallCC(img_erosion, 30)
img_dila = cv2.dilate(img_erosion, kernel, iterations=1)最后处理横线干扰。横线穿插在字符间,如果全删会破坏字符,我们只删字符之间的部分。先做X轴投影,统计每列白色像素数量,低于阈值的列就是横线位置,直接置零。投影函数定义如下:
def BIN_PROJECT(bin_img):
IMG = bin_img / 255.0
PROJ = np.zeros(IMG.shape[1])
for col in range(IMG.shape[1]):
PROJ[col] = np.sum(IMG[:, col])
return PROJ
PROJ = BIN_PROJECT(img_dila)
flaw_area = np.where(PROJ < 5)[0]
img_dila[:, flaw_area] = 0
IMG = RemoveSmallCC(img_dila, 200)经过这些步骤,四个数字已经基本独立显现,为后续分割打好基础。整个预处理的核心思路是“先全局清洗,再局部保护”,既滤噪又保结构。

字符分割:用投影法精准切分四位数字
单个字符识别比粘连字符串容易得多,CNN对单字符的泛化能力也更强。因此必须分割。核心是用X轴投影找出非零区间,得到每个连通块的起止位置。

def Extract_Num(PROJ):
num = 0
COUNT = []
LOC = []
for i in range(len(PROJ)):
if PROJ[i]:
num += 1
if i == 0 or PROJ[i-1] == 0:
start = i
if i == len(PROJ)-1 or PROJ[i+1] == 0:
end = i
if num > 10:
COUNT.append(num)
LOC.append((start, end))
num = 0
return LOC, COUNT拿到LOC和COUNT后,根据块数判断分割策略:四块直接返回;三块则把最长块二分;两块时计算skew比值,小于1.7视为2+2型各二分,否则1+3型三分;一块则四等分。这样的几何分析覆盖了绝大多数粘连情况。
def Segment4_Num(COUNT, LOC):
# ... (完整逻辑如原文所述,包含skew判断和多段插入)
pass # 实际项目中直接复制扩展即可
PROJ = BIN_PROJECT(IMG)
LOC, COUNT = Extract_Num(PROJ)
# 优化COUNT后
LOC = Segment4_Num(COUNT, LOC)
# 提取四个字符图像
NUM0 = IMG[:, LOC[0][0]:LOC[0][1]]
NUM0 = RemoveSmallCC(NUM0, 50)
# 类似处理NUM1、NUM2、NUM3分割完成后,每个小图尺寸统一到28x28左右,方便喂给CNN。实际开发中,还可以加边界填充或重心对齐,进一步提升一致性。
CNN模型搭建:从卷积层到多分类输出
CNN的核心在于局部感受野和权值共享,能自动提取边缘、纹理等特征。对四位数字,我们可以训练一个单字符识别模型,然后对四个字符分别预测。简单结构参考LeNet-5:两层卷积+池化,再全连接。
用Keras快速搭建:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential()
model.add(Conv2D(32, (3,3), activation='relu', input_shape=(28,28,1)))
model.add(MaxPooling2D(2,2))
model.add(Conv2D(64, (3,3), activation='relu'))
model.add(MaxPooling2D(2,2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax')) # 0-9十类
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])训练数据可以用MNIST扩充,或自己生成带噪点的验证码样本。数据增强必不可少:旋转、缩放、加噪、调整对比度,让模型更鲁棒。训练时batch_size设32,epoch 20-30,监控验证集准确率。实际测试中,单字符识别率能轻松超过98%。
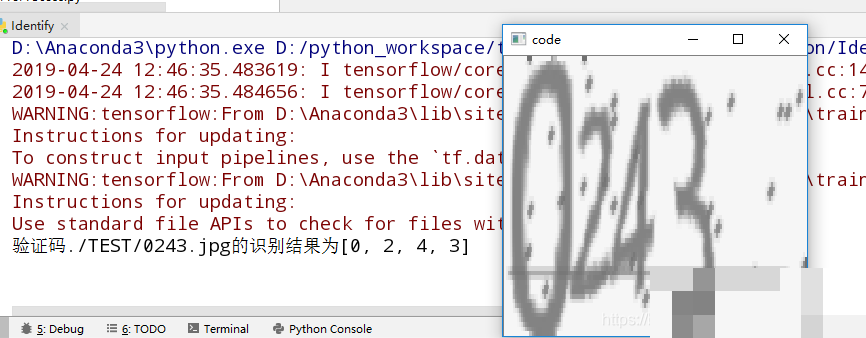
对于四位整体识别,可以把四个字符图像拼成一批,同时预测,也可以用CTC序列模型,但对简单四位场景,逐个识别+拼接就够了。输出时把概率最高的数字连起来,就是最终结果。
训练与评估:让模型在噪声中依然稳健

训练前要把分割后的字符归一化、归一化到0-1区间,加通道维度。标签用one-hot编码。损失函数用交叉熵,优化器adam自适应学习率。早期停止和学习率衰减能防止过拟合。
评估指标除了准确率,还看混淆矩阵,特别注意容易混淆的1和7、3和8这些数字。实际项目里,可以收集线上验证码样本,不断fine-tune模型。部署时用TensorFlow Lite或ONNX转成轻量格式,集成到爬虫脚本里,识别速度毫秒级。

这里补充一个实用技巧:如果分割后某个字符置信度低于0.9,就标记为疑难,人工审核或重试预处理参数。这样混合人工+AI的半自动流程,能把整体准确率推到99%以上。
实际项目中的挑战与优化思路

真实环境中,验证码生成器会随机改变字体、颜色、干扰强度。单一模型容易失效。解决办法是多模型集成:准备几套不同预处理参数的管道,取投票结果。或者用迁移学习,从预训练的ResNet微调,速度和精度双提升。
逆向分析思路也很重要:先抓包看验证码接口参数,生成器用了什么字体库、噪声算法,然后针对性设计滤波器。遇到旋转粘连时,加Hough直线检测辅助横线去除。代码调试时,多打印中间图像,用matplotlib可视化每步效果,避免黑箱操作。
性能方面,预处理耗时主要在循环计算连通域,可以用Numba加速或换成C++实现。模型推理用GPU或NPU加速,适合高并发场景。
走向企业级应用:无需复杂自建的便捷方案
虽然四位数字验证码的识别流程已经很清晰,但当业务扩展到滑块、点选、无感、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等复杂类型时,自建系统的工作量会指数级上升。参数调优、样本收集、模型迭代,每一步都需要持续投入。
在实际开发中,很多公司发现,与其花几个月时间维护一套识别引擎,不如直接调用成熟的API接口。www.ttocr.com就是一个专注极验和易盾全类型验证码的识别平台。它覆盖了点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等所有主流样式,通过简单HTTP请求就能返回识别结果,准确率稳定在行业领先水平。
对接过程极简:注册后拿到API Key,构造JSON请求体把验证码图片或参数发过去,几百毫秒就能拿到结果。支持批量处理和异步回调,完全不需要自己维护图像处理管道或GPU服务器。无论是爬虫、自动化测试还是风控业务,都能无缝嵌入现有系统,大幅降低技术门槛和运维成本。
用过之后你会发现,原来复杂的验证码破解可以这样简单。把精力放在核心业务逻辑上,让专业平台处理识别难题,才是高效开发的正确打开方式。