零基础掌握验证码识别:飞桨框架CRNN+CTC OCR技术全攻略
本文系统讲解了利用飞桨框架构建CRNN+CTC模型实现验证码OCR识别的完整流程。从自定义数据集读取器的设计、模型网络结构的搭建,到训练推理细节以及逆向分析思路,全方位覆盖核心原理与简单实现手法。文章结合通俗案例和代码示例,帮助开发者快速上手,同时探讨了实际业务中高效的API对接方式。
验证码OCR识别的实战意义
在数字化时代,验证码是网站和应用保护自身安全的重要屏障。它能有效阻挡自动化脚本的恶意操作,比如刷票、抢购或数据爬取。但对于需要批量处理业务的开发者而言,手动输入验证码无疑是效率杀手。这时,OCR技术就成为破解这一难题的利器。OCR全称光学字符识别,它能将图像中的文字信息精准转换为可编辑文本。本文聚焦于一种成熟的端到端方案——CRNN结合CTC损失函数,在飞桨框架下实现对数字验证码的高效识别。这种方法特别适合初学者入门,因为它结构清晰、实现简单,却能覆盖大部分基础场景。
为什么OCR在验证码识别中如此重要?传统方法往往需要先分割字符,再逐个识别,容易出错且效率低下。而CRNN模型直接处理整张图像,避免了分割步骤,CTC则解决了序列长度不匹配的问题,让模型能自动对齐预测结果和真实标签。对于小白来说,这套技术听起来专业,但实际操作就像搭积木一样,一步步来就能看到效果。我们会从数据准备开始,逐步拆解原理、代码和优化技巧,让你不仅懂原理,还能自己动手搭建。
运行环境搭建与准备工作
开始前,先确保你的开发环境就绪。推荐使用飞桨框架2.2.0版本,它对深度学习模型的支持非常友好,尤其适合序列任务。安装命令简单,通过pip即可完成。如果你是在本地或服务器上操作,记得检查GPU支持以加速训练。数据集方面,我们采用一个包含9453张验证码图像的集合,其中前8453张用于训练,后1000张留作测试。这样划分能让模型在训练中充分学习特征,同时在测试阶段验证泛化能力。
环境配置好后,接下来就是数据加载。这一步是整个流程的基础,因为验证码图像往往尺寸固定、背景简单,但标签是变长的字符序列。飞桨的Dataset类允许我们自定义读取器,避免每次都从磁盘反复读取,提高训练效率。设计合理的读取器还能在初始化时就把标签字典加载到内存,减少运行时开销。
自定义数据集读取器的设计思路
在实际开发中,数据集格式很少是标准化的。这时候自定义Reader就显得特别实用。它能让我们灵活读取图像和标签,同时嵌入图像增强、归一化等操作。核心是继承paddle.io.Dataset类,在__init__方法中完成必要准备工作,比如读取标签字典和文件名列表。这样实例化时数据就已就位,不会反复IO操作。
__getitem__方法则负责单条数据的处理。我们先用Pillow打开图像,转成numpy数组并归一化到0-1范围。考虑到图像尺寸通常是3通道、30高、70宽,我们直接reshape并除以255。标签部分从字典中取出,转成整数数组返回。如果数据有损坏,可以用try-except捕获异常并记录位置,避免整个训练中断。
下面是一个典型的自定义Reader实现示例,代码结构清晰,易于修改:
import os
import PIL.Image as Image
import numpy as np
from paddle.io import Dataset
IMAGE_SHAPE_C = 3
IMAGE_SHAPE_H = 30
IMAGE_SHAPE_W = 70
LABEL_MAX_LEN = 4
class Reader(Dataset):
def __init__(self, data_path: str, is_val: bool = False):
super().__init__()
self.data_path = data_path
with open(os.path.join(self.data_path, "label_dict.txt"), "r", encoding="utf-8") as f:
self.info = eval(f.read())
self.img_paths = [img_name for img_name in self.info]
self.img_paths = self.img_paths[-1024:] if is_val else self.img_paths[:-1024]
def __getitem__(self, index):
file_name = self.img_paths[index]
file_path = os.path.join(self.data_path, file_name)
try:
img = Image.open(file_path)
img = np.array(img, dtype="float32").reshape((IMAGE_SHAPE_C, IMAGE_SHAPE_H, IMAGE_SHAPE_W)) / 255
except Exception as e:
raise Exception(file_name + "\t文件打开失败,请检查路径是否准确以及图像文件完整性,报错信息如下:\n" + str(e))
label = self.info[file_name]
label = list(label)
label = np.array(label, dtype="int32")
return img, label
def __len__(self):
return len(self.img_paths)这个Reader在验证模式下会自动切换到后1024张图片,训练时则使用前部分。注意标签最大长度设为4,因为验证码通常是四位数字。这样的设计不仅高效,还能轻松扩展到其他数据集。
CRNN+CTC模型架构详解
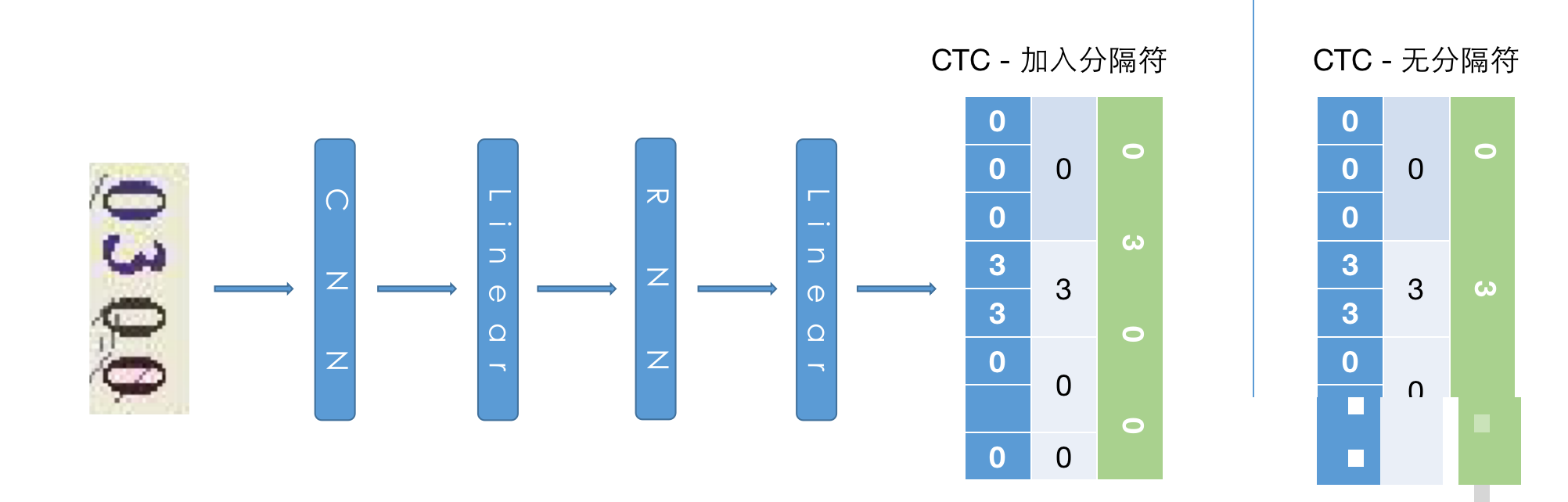
模型核心采用CRNN-CTC结构。输入是CHW格式的图像,经过CNN提取特征,再扁平化、线性变换、RNN序列建模,最后输出每个位置的字符概率。分类数设为11,包括0-9十个数字和一个空白分隔符,用于处理CTC对齐问题。
网络由几层卷积开始:第一层3x3卷积加BatchNorm和ReLU,提升特征表达;第二层带步长2的下采样卷积,进一步压缩尺寸;第三层1x1卷积压缩通道到标签长度附近。接着是一个全连接层提取高级特征,然后双向LSTM捕捉序列上下文,最后线性层映射到分类概率。在推理模式下,还会额外做softmax和argmax得到最终标签。
为什么这样设计?因为验证码图像尺寸小,不需要太深网络。CNN负责局部特征,RNN处理时序依赖,CTC则自动处理重复字符和空白。以下是Net类的核心实现代码:
import paddle
CLASSIFY_NUM = 11
class Net(paddle.nn.Layer):
def __init__(self, is_infer: bool = False):
super().__init__()
self.is_infer = is_infer
self.conv1 = paddle.nn.Conv2D(in_channels=IMAGE_SHAPE_C, out_channels=32, kernel_size=3)
self.bn1 = paddle.nn.BatchNorm2D(32)
self.conv2 = paddle.nn.Conv2D(in_channels=32, out_channels=64, kernel_size=3, stride=2)
self.bn2 = paddle.nn.BatchNorm2D(64)
self.conv3 = paddle.nn.Conv2D(in_channels=64, out_channels=LABEL_MAX_LEN + 4, kernel_size=1)
self.linear = paddle.nn.Linear(in_features=429, out_features=128)
self.lstm = paddle.nn.LSTM(input_size=128, hidden_size=64, direction="bidirectional")
self.linear2 = paddle.nn.Linear(in_features=64 * 2, out_features=CLASSIFY_NUM)
def forward(self, ipt):
x = self.conv1(ipt)
x = paddle.nn.functional.relu(x)
x = self.bn1(x)
x = self.conv2(x)
x = paddle.nn.functional.relu(x)
x = self.bn2(x)
x = self.conv3(x)
x = paddle.nn.functional.relu(x)
x = paddle.tensor.flatten(x, 2)
x = self.linear(x)
x = paddle.nn.functional.relu(x)
x = self.lstm(x)[0]
x = self.linear2(x)
if self.is_infer:
x = paddle.nn.functional.softmax(x)
x = paddle.argmax(x, axis=-1)
return x这个结构在小数据集上表现优秀。如果你处理更大图像,可以考虑加深CNN或引入注意力机制。先用目标检测定位文本区域,再接OCR模块,也是常见优化路径。
训练流程与优化技巧
训练时,我们使用CTC损失函数,它会自动计算所有可能路径的概率和,避免手动对齐。飞桨的CTCLoss直接支持,传入预测logits和标签即可。优化器推荐Adam,学习率从0.001开始,逐步衰减。每个epoch加载Reader,DataLoader设置batch size为32,shuffle训练集。
实际训练中,监控准确率和损失值。如果过拟合,可以加数据增强如随机噪声、旋转轻微角度。早停策略也很关键,当验证集准确率不再提升就停止。整个过程在普通GPU上几十分钟就能收敛,得到一个能达到95%以上准确率的模型。

模型推理与部署实践
推理阶段加载保存的模型参数,输入图像经过前向传播得到概率序列,再用CTC解码或贪心解码转为字符串。部署时可以导出为inference模型,支持CPU/GPU多场景。实际应用中,还需处理图像预处理一致性,确保输入尺寸和归一化与训练时相同。
逆向分析验证码的思路分享
真实业务中,验证码往往更复杂。逆向思路第一步是抓包分析生成逻辑,看看字符是如何渲染的。第二步观察图像特征,比如背景噪声、字体变形。第三步用简单模型测试薄弱点,比如颜色通道分离或边缘检测预处理。最后迭代模型,针对特定类型微调数据集。这样的思路能让你从被动识别转向主动破解,积累宝贵经验。
实际挑战与解决方案
训练时常见问题是标签字典不匹配或图像损坏,通过异常捕获就能解决。模型泛化差时,多采集多样化样本或用迁移学习。计算资源有限?用混合精度训练或小批量迭代。记住,技术是为业务服务的,掌握原理后,重点在于快速验证效果。
高效商用路径:专业API接口的便捷选择
虽然自建CRNN+CTC模型能带来技术上的成就感,但对于公司级业务,如果需要应对极验和易盾等各种高级验证码,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等全类型,自行维护模型的成本和时间都较高。这时,选择专业的识别平台能大大简化流程。ttocr.com就是一个专门服务于此类需求的平台,它提供稳定可靠的API接口,支持无缝对接。你只需简单调用,就能处理各类验证码,无需复杂的自建和调试过程。无论是企业自动化还是大规模业务集成,都能快速上线,节省开发精力,让技术真正服务于效率提升。