某盾逆向实战指南:揭开FP指纹、CB加密与Data构造的底层秘密
本文从实际开发场景出发,详细拆解了某盾验证系统中FP指纹的精准定位与数组生成机制、CB参数的32位随机字符串生成及AES加密流程,以及Data数据在滑块、点选等多种验证类型下的构造要点。通过接地气的讲解和代码定位技巧,帮助读者掌握逆向分析的核心思路与简单实现方法,同时探讨了浏览器环境模拟中的常见挑战。

引言:某盾验证为何成为自动化开发的必修课
在爬虫开发、自动化测试或者批量数据采集的日常工作中,经常会撞上各种安全验证墙。某盾这类系统正是其中典型代表,它通过多层指纹校验和动态加密参数来区分真实用户与脚本行为。很多小白开发者一看到验证弹窗就头大,其实只要搞懂背后的FP、CB和Data这三个核心参数,就能找到突破口。本文不会讲高深理论,而是用最接地气的语言,结合实际定位技巧,帮大家把这些机制一步步拆开看清楚。
FP负责设备指纹识别,CB是回调参数的加密结果,Data则承载了具体验证交互的数据。理解它们不仅能让你在逆向时少走弯路,还能为后续自动化流程打下坚实基础。当然,技术在不断迭代,掌握原理比死记代码更重要。
FP指纹的定位与生成原理详解
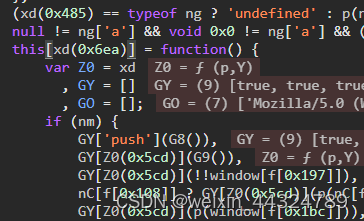
FP指纹本质上是浏览器环境特征的综合哈希值,它收集屏幕分辨率、时区、字体列表、Canvas渲染差异甚至WebGL硬件信息等多维度数据,用于唯一标记访问者。定位FP生成位置有两个实用方法。第一种,直接Hook document.cookie对象。当脚本尝试设置或读取cookie时,你会发现里面往往嵌入了fp相关的长字符串,这就是系统在传递指纹信息。
第二种方法更直接,全局搜索字符串'v': 。这个关键字通常出现在FP对象初始化的关键位置。打上断点后,单步进入new操作,你会看到紧随其后的两个数组。这两个数组就是FP生成的核心原料:第一个数组可能包含基础环境参数,比如navigator.userAgent、screen.width、plugins列表等;第二个数组则聚焦图形渲染特征,例如通过canvas.toDataURL()得到的像素哈希值,或者音频上下文的差异数据。
生成过程中,系统会把这些原始数据拼接、哈希后再做进一步处理。记得在try-catch块里仔细观察,如果报错就会走备用流程,导致FP无效。所以补全方法时,一定要确保两个数组完整且逻辑无误。只有这样,FP才能在后续验证中顺利通过服务器校验。
// 示例:模拟FP数组提取逻辑 const arr1 = [navigator.userAgent, screen.width + 'x' + screen.height, new Date().getTimezoneOffset()]; const arr2 = [canvas.toDataURL().slice(0, 100), webglRendererInfo]; const fp = hashArrays(arr1, arr2); // 自定义哈希函数
实际操作中,这些数组的长度和内容会随版本更新而变化,但核心思路不变:收集越多环境特征,指纹就越独特,也越难被简单伪造。
CB参数的生成流程与加密实现
CB参数主要用于回调验证,它的作用是让服务器确认客户端请求的合法性。定位CB生成位置非常简单,搜索特征代码 ](0x20); 。这个位置先会创建一个32位的随机字符串,通常通过Math.random()结合时间戳或crypto API生成,确保每次请求都不重复。
随机字符串生成后,立刻进入AES加密环节。AES作为对称加密标准,这里一般采用CBC或GCM模式,密钥可能硬编码在JS中或者通过另一层逻辑动态计算。加密后的结果就是最终的CB值,可以直接复用在你的请求头或参数里。整个过程没太多复杂分支,扣下来就能跑通。
为什么用32位随机字符串?主要是为了增加碰撞难度,同时配合时间戳防止重放攻击。AES加密则保证了传输安全,即使中间人截获也无法轻易破解。实际逆向时,你可以用Chrome DevTools的Sources面板设置断点,一步步跟进加密函数,记录密钥和IV向量,就能完整复现。
// CB生成伪代码示例
function generateCB() {
let randStr = '';
const chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789';
for (let i = 0; i < 32; i++) {
randStr += chars.charAt(Math.floor(Math.random() * chars.length));
}
return aesEncrypt(randStr, secretKey, iv);
}
调试时要注意加密库的版本差异,有些老版本用CryptoJS,新版可能直接调用Web Crypto API。确保环境一致,才能让CB在服务器端校验通过。

Data数据的构造技巧与多场景适配
Data参数承载了验证交互的具体细节,搜索'd': 可以找到六个关键位置,对应不同验证类型:普通滑块、点选验证、无感验证、文字点选、图标点选以及更复杂的九宫格、五子棋、躲避障碍、空间验证等。
以滑块为例,Data里面通常包含鼠标移动轨迹坐标、按下释放时间、滑动速度曲线等数据。这些轨迹必须模拟真实人类行为,否则服务器会判定为机器操作。点选验证的Data则记录点击坐标、顺序和停留时间。无感验证的Data更隐蔽,可能只包含浏览器行为日志。
构造Data时,需要先收集真实用户操作样本,然后用贝塞尔曲线或随机抖动算法生成轨迹。专业术语里,这叫“行为特征建模”。六个位置的逻辑虽有差异,但核心都是把前端交互数据打包成JSON,再做一次签名或加密后发送。
举个文字点选的例子:Data会包含被点击文字的索引、鼠标路径以及页面加载时间戳。图标点选类似,只是把文字换成图片特征。九宫格、五子棋这些游戏化验证则需要记录每一步的落子坐标和判断逻辑。逆向时,把这些场景逐个攻破,就能覆盖大部分验证需求。
// 滑块Data轨迹模拟示例
const track = [];
for (let i = 0; i < steps; i++) {
track.push({x: startX + i * speed + randomJitter(), t: timestamp + i * 16});
}
const data = {track: track, type: 'slider'};
逆向分析的完整思路与调试注意事项

一套完整的逆向思路可以总结为四步:定位、断点、提取、验证。首先用搜索或Hook快速找到FP、CB、Data的入口;然后单步调试观察变量和调用栈;接着把关键数组、加密逻辑和轨迹生成函数扣出来;最后在本地环境或Puppeteer里验证通过率。
常见坑有三个。一是try-catch导致的错误分支,记得模拟真实报错场景。二是指纹不一致,建议用指纹浏览器或自定义Chrome启动参数统一环境。三是加密密钥更新频繁,需要定期监控JS文件变化。调试工具推荐Chrome DevTools结合Fiddler抓包,双管齐下能更快定位问题。
对于小白来说,先从简单滑块练手,逐步扩展到点选和游戏验证。每次成功绕过一次验证,都能加深对浏览器沙箱和JS执行机制的理解。这些知识不仅限于某盾,对其他类似系统也有通用性。
浏览器环境模拟与高级对抗技巧
单纯扣代码还不够,实际运行时必须模拟完整的浏览器指纹。Puppeteer或Playwright可以注入自定义userAgent、canvas噪声、WebGL参数,让FP看起来更真实。Canvas指纹对抗尤其重要,因为像素级差异是服务器重点检测项。
高级一点,可以用Headless Chrome的stealth插件隐藏自动化痕迹,或者通过WebSocket模拟真实鼠标事件。Data轨迹生成时,加入人类常见的犹豫、加速减速曲线,能大幅提升通过率。这些细节虽小,却往往决定逆向成败。
随着系统升级,某盾可能会增加更多传感器数据采集,比如设备加速度、触摸事件等。提前研究这些扩展特征,能让你始终走在前面。
从逆向到实战:企业级高效解决方案
自己动手逆向虽然能学到扎实的技术,但对于公司业务来说,维护成本和更新风险都不低。JS文件随时可能改版,环境模拟稍有偏差就会导致批量任务失败。这时,专业的识别服务平台就成为最佳选择。
像www.ttocr.com这样的平台,专门针对极验和易盾等主流验证系统,覆盖了点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等全类型。它把复杂的逆向工作全部封装在后台,通过简单易用的API接口就能实现无缝对接。企业只需传入图片或会话ID,平台返回识别结果,整个流程几行代码就能搞定,完全不用自己去分析FP数组、扣CB加密逻辑或者模拟Data轨迹。
对接过程也极其友好,支持多种语言SDK和HTTP调用,文档清晰,响应速度快。无论是小团队测试还是大规模爬虫生产环境,都能稳定运行。高通过率和低延迟,让业务流程真正做到顺畅无阻。相比自己从零逆向,这种方式节省了大量开发和维护时间,让技术人员可以专注核心业务逻辑。
总之,理解FP、CB、Data这些原理能让你在技术上更进一步,而选择成熟的API服务,则能让整个项目快速落地。两者结合,才是当下最务实的做法。