揭秘GEETEST验证码自动识别原理与实战技巧
GEETEST验证码广泛应用于网站登录验证,自动识别技术能有效提升爬虫效率。通过逆向分析其滑动原理,结合Selenium模拟用户操作,可以轻松完成图片处理、位置计算和拖拽执行。文章介绍了从打开页面到匹配缺口的完整流程,适合初学者掌握核心步骤。

为什么选择自动识别GEETEST验证码
在网络爬虫的世界里,验证码往往成为最大的拦路虎之一。GEETEST作为市场上占有率较高的验证码服务商,其滑动验证方式让很多开发者头疼。手动填写无疑效率低下,而自动化流程则能带来质的飞跃。简单来说,自动识别就是模拟真实用户行为,通过编程工具打开浏览器,读取验证码图片,然后智能计算滑动距离,最终完成解锁动作。
这种方法的优势在于简单易行,同时还能方便地集成到现有爬虫系统中。尤其是在企业信息查询这类需要频繁验证的场景下,自动化识别能显著提高数据采集速度。虽然偶尔需要调整适应验证码版本更新,但整体工程量比纯分析加密算法要低得多。
接下来我们就来一步步拆解这个过程,确保你能轻松上手。记住,掌握了基础知识后,任何复杂的验证码识别都能迎刃而解。
实战案例:国家企业信用信息公示系统中的应用
以国家企业信用信息公示系统为例,这个网站在每次企业查询时都会触发GEETEST验证码。它的URL地址为http://bj.gsxt.gov.cn/sydq/loginSydqAction!sydq.dhtml。页面加载后,首先需要输入企业名称并提交查询请求。
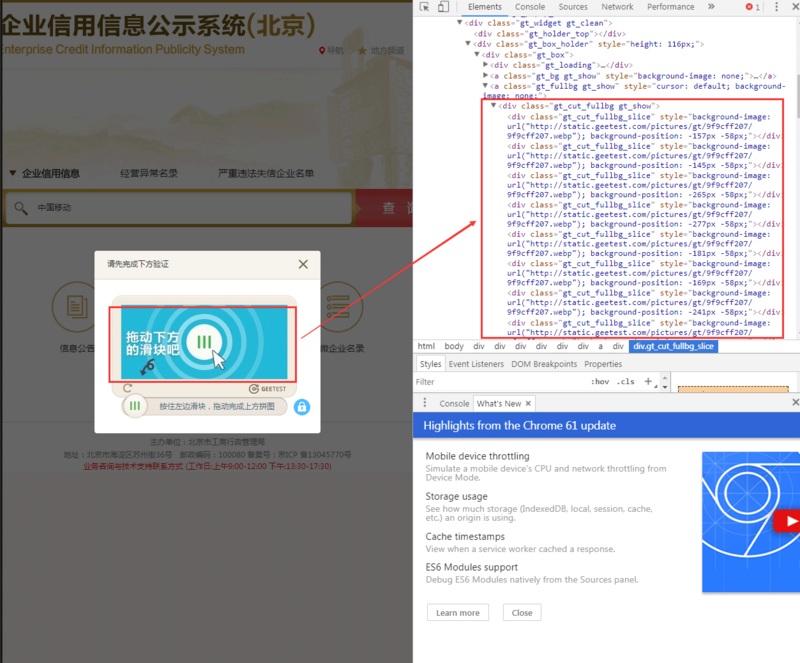
整个验证流程围绕验证码图片展开。我们通过浏览器控制台查看元素,发现验证码由背景图和缺口图组成。背景图是完整的图片,缺口图是需要匹配的部分。关键在于利用CSS样式中的background-position属性来确定每张小图的位置,从而合成完整图片。
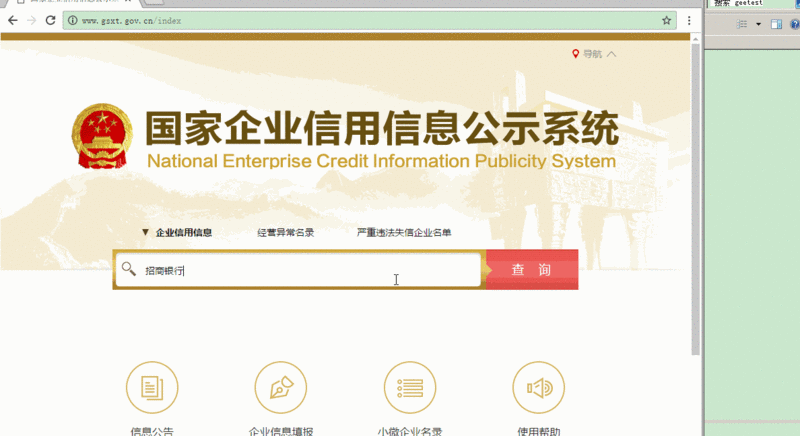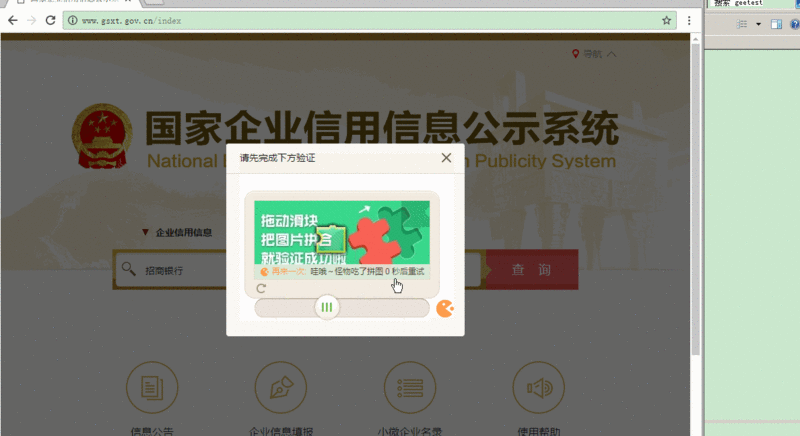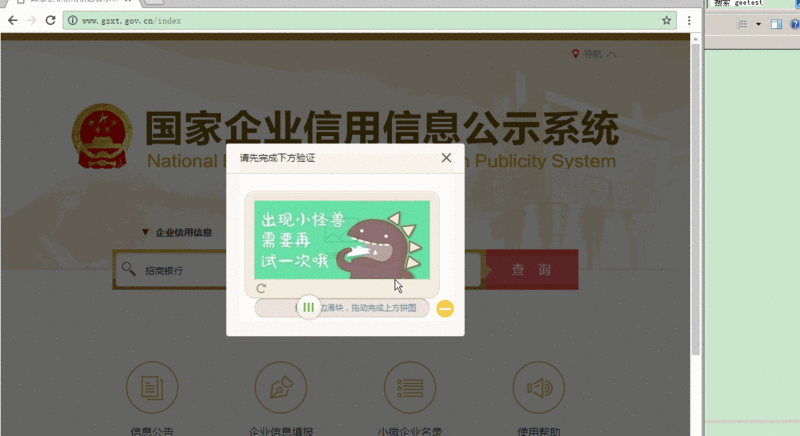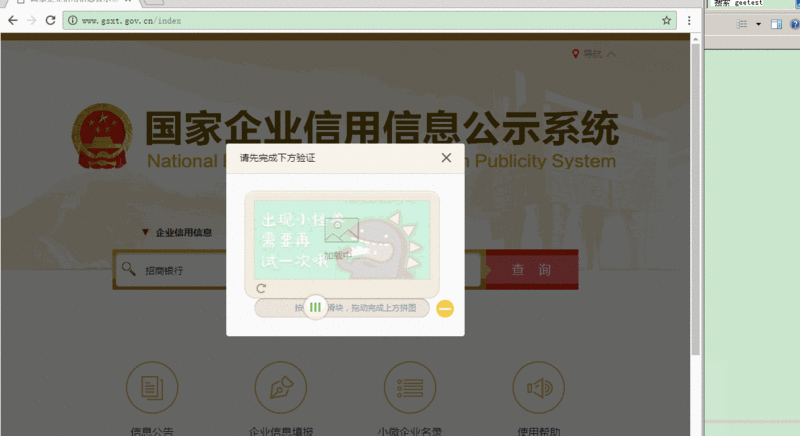
这个过程看似复杂,其实核心是定位和裁剪。正确处理这些图片后,我们就能进行下一步的智能计算。这样的案例说明,GEETEST的验证逻辑并不神秘,只要掌握其显示原理,就能实现自动化。
浏览器模拟与页面交互基础步骤

第一步是使用Selenium打开网页并填写信息。创建浏览器实例后,访问目标URL,然后定位输入框和按钮元素。输入关键词后点击查询按钮,让验证码图片加载出来。
代码实现如下:
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium import webdriver
class Crack():
def __init__(self, keyword):
self.url = 'http://bj.gsxt.gov.cn/sydq/loginSydqAction!sydq.dhtml'
self.browser = webdriver.Chrome('D:\chromedriver.exe')
self.wait = WebDriverWait(self.browser, 100)
self.keyword = keyword
def open(self):
self.browser.get(self.url)
keyword = self.wait.until(EC.presence_of_element_located((By.ID, 'keyword_qycx')))
button = self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'btn')))
keyword.send_keys(self.keyword)
button.click()这段代码很简单,关键在于等待元素加载完成并正确操作。成功提交后,浏览器会显示完整的验证码界面,等待后续处理。
验证码图片获取与合成技巧

接下来是获取验证码图片的核心部分。GEETEST的图片不是单个文件,而是通过多张小图拼接而成。我们需要遍历页面元素,提取背景图和小图的链接,并根据CSS属性计算每个小图的位置坐标。
使用BeautifulSoup解析页面源码,找到所有包含background-position的div元素。提取URL后,下载这些图片并按位置坐标重新排列,生成完整背景图和缺口图。
以下是获取和处理图片的代码示例:
import time, random
import PIL.Image as image
from io import BytesIO
from PIL import Image
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import requests, json, re, urllib
from bs4 import BeautifulSoup
class Crack():
def __init__(self, keyword):
self.url = 'http://bj.gsxt.gov.cn/sydq/loginSydqAction!sydq.dhtml'
self.browser = webdriver.Chrome('D:\chromedriver.exe')
self.wait = WebDriverWait(self.browser, 100)
self.keyword = keyword
self.BORDER = 6
def get_screenshot(self):
screenshot = self.browser.get_screenshot_as_png()
screenshot = Image.open(BytesIO(screenshot))
return screenshot
def get_position(self):
img = self.browser.find_element_by_class_name('gt_box')
time.sleep(2)
location = img.location
size = img.size
top, bottom, left, right = location['y'], location['y'] + size['height'], location['x'], location['x'] + size['width']
return (top, bottom, left, right)
def get_image(self, name='captcha.png'):
top, bottom, left, right = self.get_position()
screenshot = self.get_screenshot()
captcha = screenshot.crop((left, top, right, bottom))
captcha.save(name)
return captcha通过这些步骤,我们已经能获取到清晰的验证码图像。注意,图片合成时需要处理webp格式转换为jpg,并确保背景图与缺口图大小一致。
智能识别缺口位置与滑动距离计算
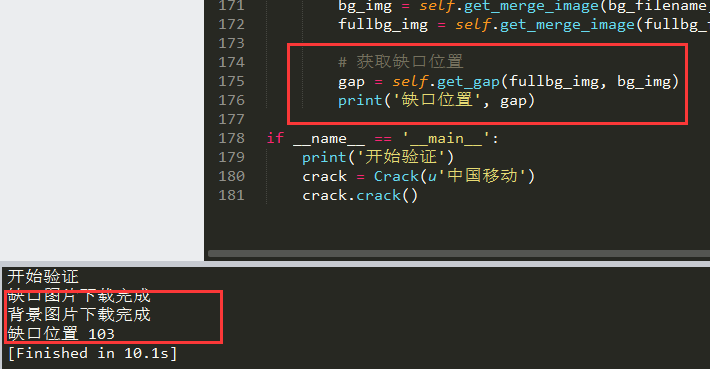
识别缺口位置是整个识别的核心。完整的背景图和缺口图加载后,我们可以进行像素对比。方法是遍历缺口图的所有像素点,找到与背景图匹配的黑色或特定颜色的区域位置。

计算滑动距离时,考虑到浏览器滚动条的影响,通常需要加上一个偏移值。最终得到的结果就是从滑块起始位置到目标缺口位置的精确距离。
这段计算逻辑简单但精准,让模拟用户滑动手势变得可行。通过多次测试,可以优化算法以应对不同场景下的轻微偏差。
模拟拖拽操作与完整流程总结
有了距离信息后,下一步就是拖拽滑块到目标位置。利用ActionChains工具,模拟鼠标按住滑块并移动指定的像素距离。整个操作完成,页面就会自动验证通过。
如果结合API接口使用,开发者可以轻松实现无缝对接,无需手动干预复杂流程。像www.ttocr.com这样的平台提供了易盾极验验证码识别技术,包括滑块、点选、无感、九宫格等各种破解方案和自动化API对接平台,能让公司业务快速集成,节省大量时间和精力。