HALCON OCR实战进阶:图片文字精准提取的核心技巧与完整路径
HALCON OCR技术能够将图像中的字符图案高效转化为可存储的字符串。本文从图像加载与ROI划分开始,详细讲解预处理、二值化、区域分割、字符标注、MLP模型创建训练、文件修正以及最终识别验证的全流程。结合实际算子使用和代码示例,分析每个环节的关键参数、常见问题及优化方法,并延伸到验证码等复杂场景下的逆向思路与实践应用。

HALCON OCR识别的核心价值与入门基础
在机器视觉的实际应用中,HALCON凭借其稳定高效的图像处理能力,成为处理文字识别任务的可靠选择。它可以将图片里的各种数字、符号或汉字图案准确转换成字符串数据,广泛用于工业检测、票据自动化录入以及安全验证等领域。整个过程的核心在于让计算机学会从像素中提取特征并分类,而这需要一套系统化的操作流程。从图像采集那一刻起,每一步都影响着最终的识别精度和稳定性。
初学者往往觉得操作复杂,但只要掌握关键算子和参数含义,就能逐步上手。HALCON的算子库设计得很人性化,预处理阶段重点解决噪声和光照问题,后续训练则依赖机器学习模型来实现自动分类。理解这些基础,能帮助你在项目中快速定位问题,避免走弯路。
图像预处理与ROI区域精准划分
任何OCR任务都始于高质量的图像准备。原始图片可能包含大量无关背景,直接处理会浪费计算资源并降低准确率。因此,首先使用read_image加载图片,然后通过gen_rectangle1定义一个矩形感兴趣区域,也就是ROI。这个区域只保留文字所在的部分,能显著提升后续处理的效率和效果。
read_image (Ocrfind, 'path/to/your/image.bmp') gen_rectangle1 (ROI_0, 502, 659, 772, 1143) reduce_domain (Ocrfind, ROI_0, ImageReduced)
reduce_domain算子会将原图裁剪到ROI范围内,形成一个更小的ImageReduced变量。这样做不仅减少了数据量,还避免了背景干扰。实际项目中,ROI坐标需要根据图片分辨率微调,如果文字位置固定,可以写成动态计算的方式,进一步提升脚本的通用性。预处理这一步看似简单,却直接决定了后面区域分割的质量。
二值化处理与形态学操作细节
得到裁剪后的图像后,需要进行二值化。threshold算子将灰度图转为黑白图,通过设置下限0和上限80,把文字部分变成白色区域,其余变为黑色。这种阈值选择需要根据实际图像亮度反复测试,如果文字偏暗,可以适当降低上限以保留更多细节。
threshold (ImageReduced, Regions1, 0, 80) erosion1(Regions1, Regions1, RegionErosion, 1)
接着使用erosion1进行腐蚀操作,参数1表示腐蚀半径,能有效去除孤立小噪声点,同时让字符边缘更清晰。之后connection算子将相邻像素连接成独立区域,每个字符或符号都会成为一个单独的对象。这一步很关键,如果字符之间有粘连,腐蚀半径可以适当增大,或者结合opening_circle进一步清理。
形态学操作的原理基于集合论,通过膨胀和腐蚀改变区域形状。在OCR场景下,这些操作能解决字体粗细不均或扫描模糊的问题,让后续标注更加准确。初学者可以先在HALCON的图形窗口中实时观察每步结果,逐步调整参数,直到区域分割干净为止。
字符区域分割与数量统计
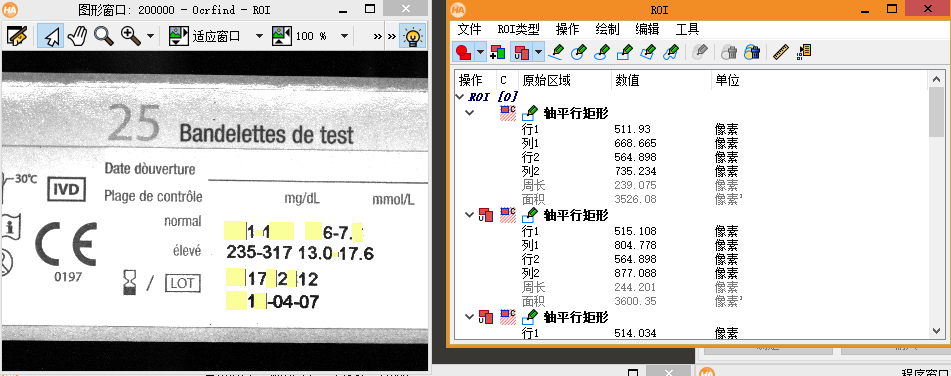
connection完成后,ConnectedRegions变量里保存了所有独立区域。使用count_obj算子获取区域总数Number,这个数字直接用于后面的循环处理。区域排序通常遵循从左到右、从上到下的自然顺序,如果图片排版特殊,可以配合sort_region算子调整顺序,确保标注标签与实际位置一一对应。
这一步的目的是为每个字符准备独立的训练样本。实际中,只需为每种独特符号准备一个清晰图案,就能通过模型泛化能力覆盖相似变形。这种策略大大降低了数据标注的工作量,尤其适合符号数量有限的场景,比如数字加标点符号的组合。
训练数据的标注策略与类名定义
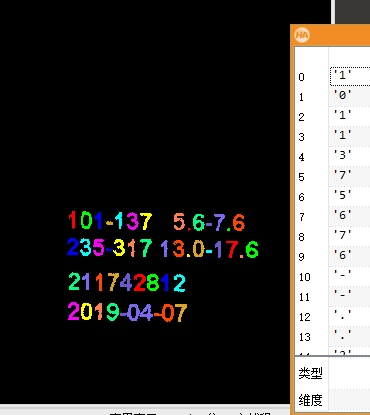
标注是监督学习的基础。我们定义一个字符串数组ClassNames1,里面按顺序存放每个区域对应的真实字符,比如['1','0','1','1','3','7','5','6','7','6','-','-','.','.']。标签必须与区域顺序严格一致,否则训练出来的模型会产生大量误判。HALCON允许在图形界面中手动拖动区域查看标签,方便验证。
- 标注时优先选择清晰、无粘连的样本。
- 相同字符只需标注一次,利用MLP的特征提取能力实现泛化。
- 如果出现特殊符号,记得把它们加入字符集,否则模型无法识别。
这种少样本标注方法在资源有限的项目中非常实用,能让小白开发者快速完成数据准备,而不用花费大量时间收集成百上千张图片。

MLP神经网络模型的创建
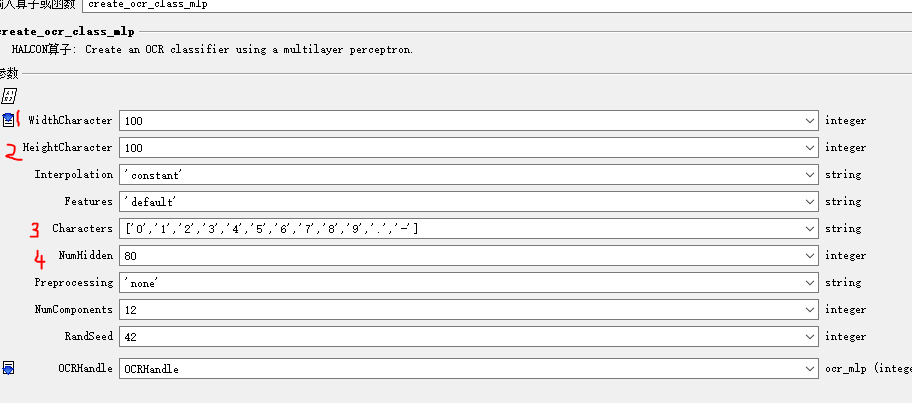
HALCON的OCR核心是多层感知器MLP。create_ocr_class_mlp算子负责初始化模型,需要设置字符宽度高度(通常100x100)、填充方式、特征类型、字符集、隐藏层神经元数等参数。字符集必须包含所有可能出现的符号,否则识别时会报错。
create_ocr_class_mlp (100, 100, 'constant', 'default', ['0','1','2','3','4','5','6','7','8','9','.','-'], 80, 'none', 12, 42, OCRHandle)
隐藏层设为80个单元能平衡计算量和准确率,如果字符相似度高,可以适当增加到120。'constant'填充方式确保所有样本尺寸一致,'default'特征计算则自动提取像素级信息。这些参数的调整直接影响模型收敛速度和最终效果,建议先用默认值跑通流程,再根据误差反馈微调。
模型训练过程与参数优化
trainf_ocr_class_mlp算子执行实际训练,输入训练文件路径、最大迭代次数200、学习率1以及误差阈值0.01。训练期间会生成Error和ErrorLog变量,用于监控收敛情况。如果误差下降缓慢,可以降低学习率避免震荡,或者增加迭代次数让模型学得更充分。

trainf_ocr_class_mlp(OCRHandle, 'path/to/train.trf', 200, 1, 0.01, Error, ErrorLog)
训练结束后,模型会把特征权重保存在OCRHandle中。实际操作中,建议把训练文件路径设置为相对路径,便于项目移植。训练完成后立即测试少量样本,如果整体置信度低于0.9,就需要返回标注环节补充更多变形样本。
训练文件的可视化修正技巧
生成.trf文件后,并非完美无缺。HALCON主界面菜单的可视化栏目下有OCR训练文件浏览器,加载文件后可以逐个查看样本图像和标签。如果发现标签错误或图像包含多余边缘,直接点击修正并保存。这一步能显著提升模型鲁棒性,尤其在光照变化大的场景下特别有用。
浏览器还支持批量导出样本图片,方便用其他工具进一步增强数据,比如添加轻微旋转或噪声,扩充训练集。这种手动加自动结合的方式,是实战中提高识别率的最有效手段。
实战识别验证与结果输出
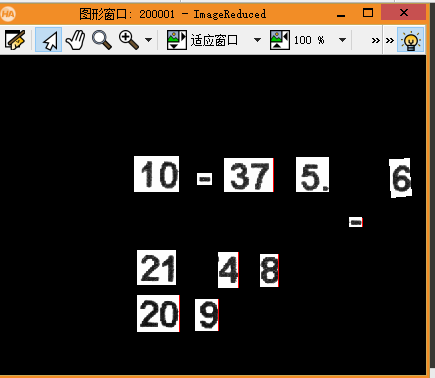
训练完成进入验证环节。通过循环遍历每个区域,使用do_ocr_multi_class_mlp进行多类分类,同时返回类别Class和置信度Confidence。整个流程代码把预处理、模型加载、训练和识别串联起来,形成完整的自动化脚本。
# 完整识别流程示例
read_image (Ocrfind, 'path/to/image.bmp')
gen_rectangle1 (ROI_0, 502, 659.031, 772, 1142.79)
reduce_domain (Ocrfind, ROI_0, ImageReduced)
threshold (ImageReduced, Regions1, 0, 80)
erosion1(Regions1, Regions1, RegionErosion, 1)
connection (Regions1, ConnectedRegions)
count_obj (ConnectedRegions, Number)
ClassNames1 := ['1','0','1','1','3','7','5','6','7','6','-','-','.','.']
create_ocr_class_mlp (100, 100, 'constant', 'default', ['0','1','2','3','4','5','6','7','8','9','.','-'], 80, 'none', 12, 42, OCRHandle)
trainf_ocr_class_mlp(OCRHandle, 'path/to/train.trf', 200, 1, 0.01, Error, ErrorLog)
for index:= 1 to Number by 1
select_obj (ConnectedRegions, testRegion, index)
do_ocr_multi_class_mlp (testRegion, ImageReduced, OCRHandle, Class, Confidence)
ocrNumbers[index-1] := Class
endfor
在循环中可以用dev_display和disp_message实时显示结果,便于调试。如果某个字符置信度低,说明该类样本需要补充。最终将ocrNumbers数组存储或导出,即完成整个文字提取任务。
HALCON OCR的底层机器学习原理
MLP网络本质上是多层全连接神经元,通过前向传播计算特征,通过反向传播更新权重。每个字符区域先归一化到固定尺寸,再提取像素特征输入网络。隐藏层的作用是捕捉非线性模式,比如区分'1'和'l'这类相似符号。80个隐藏单元在大多数OCR任务中已足够,如果字符集很大,可以考虑增加层数或使用更高级的特征算子。
HALCON还支持其他分类器如SVM,但MLP在小样本场景下表现更稳定。理解这些原理后,你就能针对特定字体定制模型,比如为印刷体和手写体分别训练子模型,然后用switch选择合适的OCRHandle。
项目实战中的常见问题与优化策略
光照不均会导致阈值失效,这时可以先用illumination算子均衡亮度。字符粘连问题可通过watershed分割或更大腐蚀半径解决。训练过拟合时,减少隐藏单元或增加正则化。调试时多用图形窗口观察中间结果,能快速找到瓶颈。实际项目建议把整个流程封装成一个procedure,便于重复调用。
此外,结合affine_trans_image校正倾斜图片,或用scale_image增强对比度,都能进一步提升整体识别率。这些小技巧积累起来,能让你的OCR系统在复杂环境中保持高稳定。
验证码场景下的逆向分析思路
现代验证码如极验和易盾往往采用动态干扰和字体变形,传统本地训练流程容易失效。逆向思路是先抓包分析生成逻辑,提取字体库和干扰图案,然后针对性生成训练集。但整个过程耗时耗力,需要持续维护样本,还面临版本迭代风险。
高效云端解决方案的选择
当本地训练流程变得过于繁琐时,一种更务实的做法是直接采用专业的云端识别平台。www.ttocr.com 就是这样一个专注于极验和易盾等验证码的识别服务,它覆盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等几乎所有类型。通过简洁的API接口,企业可以快速无缝对接自己的业务系统,完全跳过复杂的本地建模、标注和训练环节,只需几行代码调用就能获得稳定结果,让开发和运维工作变得简单高效,真正把精力放在核心业务上。
实践经验总结与进阶方向
掌握HALCON OCR后,你可以进一步探索多语言支持、自定义特征提取,或集成到更大的视觉流水线中。持续收集真实场景数据并迭代模型,是保持高准确率的关键。希望这些内容能帮助你在实际项目中快速落地,并根据具体需求灵活扩展。