滑块验证码验证链路授权逆向复盘:抓包Hook参数结构深度解析
登录页面的滑块验证链路看似简单,背后其实包含了多个前后端请求和交互流程。本文通过抓包工具观察请求顺序、应用Hook观察SDK回调、结合断点和状态对象拆分,从config到login的字段流向进行了系统梳理。重点分析了交互结果、挑战上下文、环境摘要和业务凭证四类字段结构,揭示了距离并非唯一关键点。最终总结了防护策略和调试经验,为理解这类验证码机制提供了实用思路。
整体请求流程梳理
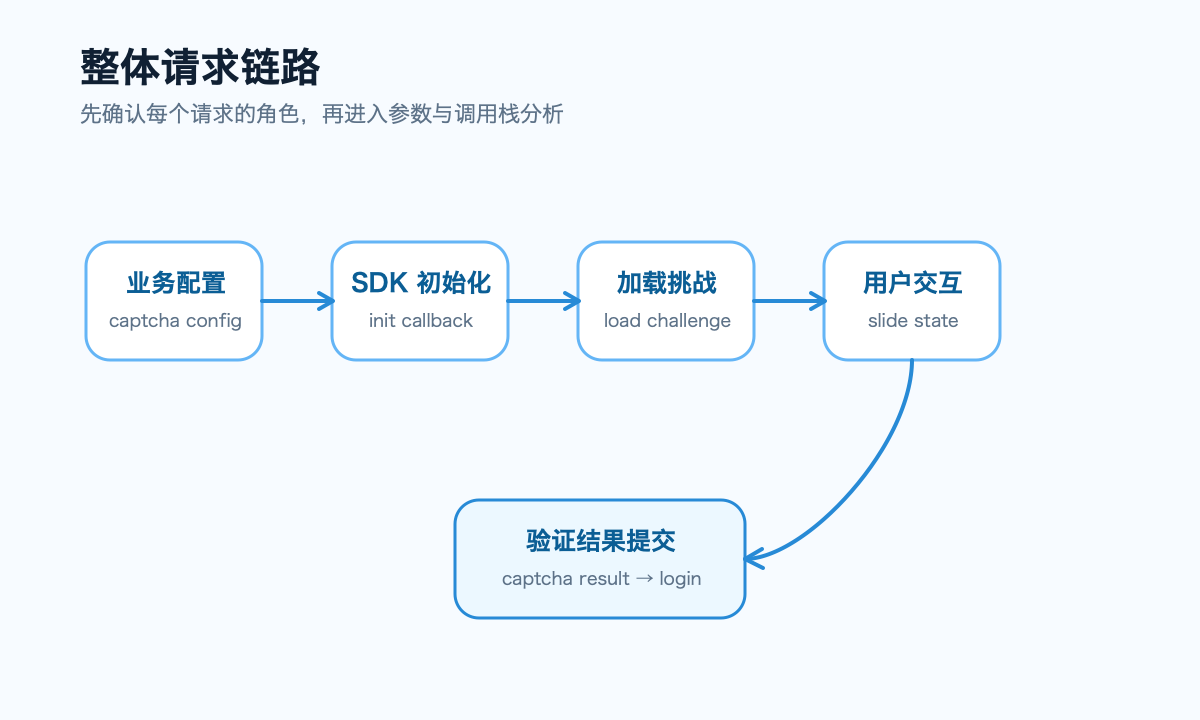
登录页面的滑块验证链路其实隐藏着多个前后端交互阶段。开发者工具里的Network面板能清晰看到请求顺序:首先是业务配置请求,用于获取验证类型和初始化参数;接着是SDK初始化,把配置传递过去;然后是挑战加载,获取本轮的图片资源、批次标识等上下文;拖动结束后的验证请求,提交交互状态;最后是业务登录,把验证结果带入账号密码校验流程。
这个流程让分析变清晰:先别急着看混淆后的代码,先把请求角色定清楚。config解决配置问题,load处理本轮挑战,verify才是核心提交点,login是业务侧最终消费。把这四段分清,后面看字段流向就直观多了。
抓包简化请求角色
打开开发者工具刷新页面后,清空Network,只看XHR和脚本请求,就能看到清晰的阶段划分。
这里把请求简化成四类:/config获取验证码配置,/load获取本轮题目和上下文,/verify提交拖动状态,/login提交业务登录。抓包阶段最重要的是给每个请求定角色,而不是纠缠每个参数细节。config的字段多是初始化信息,load的是挑战上下文,verify主要是交互结果,login则消费验证结果。
这种简化方法能避免一开始就陷入变量名和分支细节中,为后续逆向提供清晰路径。
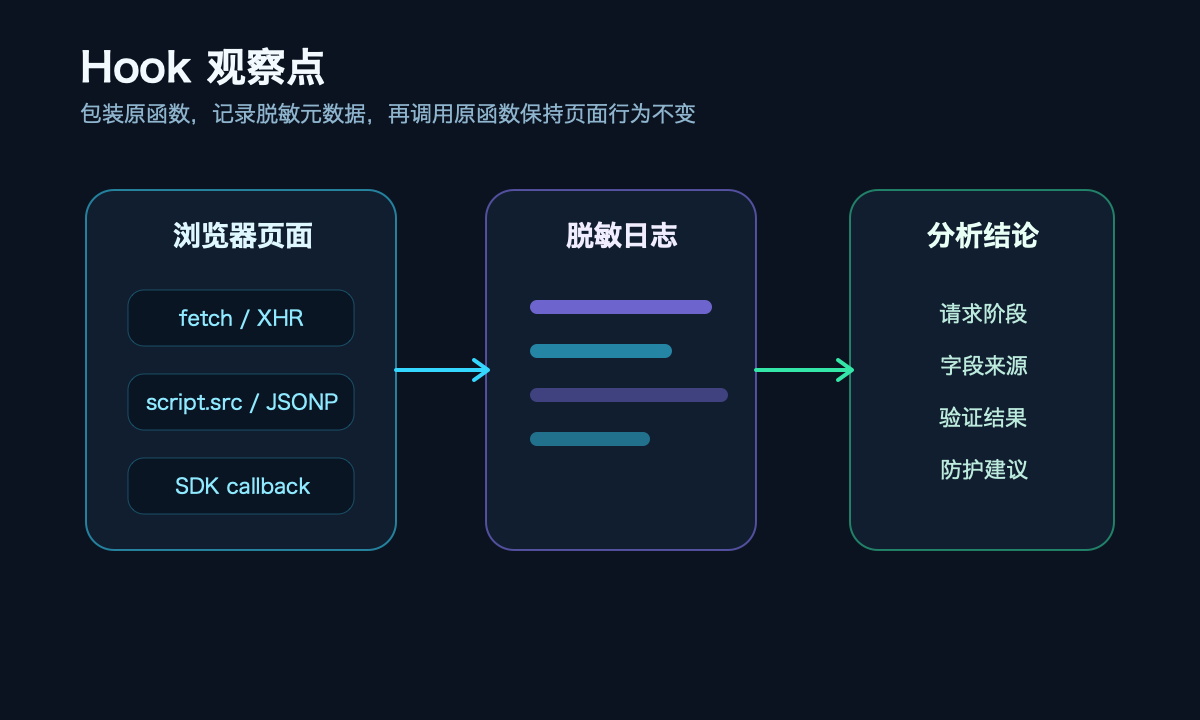
Hook技术观察SDK回调流程
Network面板只能看到请求发出去了,但看不到字段是怎么组装的。所以需要用Hook技术来追踪。
这里主要观察三个关键点:fetch或XHR请求时登录体结构,动态脚本的JSONP请求和callback名称,SDK回调里初始化参数和验证结果对象。
比如先包一层fetch,只看登录请求体大概结构:
const rawFetch = window.fetch;
window.fetch = async function hookedFetch(input, init) {
const url = typeof input === "string" ? input : input?.url;
if (String(url).includes("/login")) {
console.debug("[flow]", { stage: "login", bodyShape: ["channel", "account", "password", "captcha"] });
}
return rawFetch.apply(this, arguments);
};
这段代码的作用是确认登录接口消费了captcha字段,后续就能反推它来自SDK回调。
同时对JSONP请求也做类似处理,包一层appendChild,观察动态脚本插入和callback名称。这样就能看到验证服务返回的完整结构,而不是漏掉部分。
断点追踪调用栈查找字段来源
Hook能看到阶段,但要知道字段到底从哪里来,还得下断点。选择verify请求附近停住,然后向上看调用栈。
这个过程像倒着走:先找到最终提交点,再看状态对象在哪里组装,再看字段来自哪里。
跟栈时最关键的是字段形状,而不是变量名。拖动距离、耗时、挑战批次、环境摘要、工作量证明这些类字段,即使名字被压缩,结构上也能看出分组。
当时核心判断是,verify提交的不是单独一个距离,而是一个完整状态对象。距离只是其中一部分,这点能避免很多跑偏。
状态对象结构分类拆解
分析到这里,把状态对象拆成几类来看:
- 交互结果:来自拖动过程,记录位移、耗时、响应值
- 挑战上下文:来自load返回,标识本轮挑战
- 环境摘要:来自SDK采集,描述浏览器环境特征
- 业务凭证:来自verify返回,给登录接口继续校验
把它写成结构,大概是这样:
{
"interaction": {
"distance": 210,
"duration": 860
},
"challenge": {
"lot": "sample_lot",
"payload": "sample_payload"
},
"environment": {
"summary": {
"browser": "sample",
"feature": "sample"
}
},
"proof": {
"message": "sample_pow_message",
"signature": "sample_pow_signature"
}
};先确认state里到底有什么,因为最后怎么编码是一回事,编码前的内容才是链路核心。如果分层理解错了,后面就算找到编码入口也很难判断问题所在。
距离不是唯一重点。状态里还会带耗时、上下文、证明字段和环境字段。验证服务不仅问“你拖到了哪里”,还会看上下文、耗时、批次等,这也是为什么不建议只研究图像识别。
逆向分析技巧与防护启示
逆向分析里喜欢看错误阶段变化,比如登录失败结果从captcha_check转到account_check,就证明验证码结果已经被业务侧接受。这个信号能确认分析方向没偏。

从前端观察到的东西,其实就是防护的弱点点。编码函数在浏览器里一定能被观察,真正的校验应放在服务端;challenge要和会话绑定,load返回的上下文和登录表单要连在一起;服务端不能只看最终位移,要看完整轨迹点、速度变化、回拉等;环境摘要参与动态判断,如果长期稳定价值就下降;图片扰动只是其中一层,服务端行为校验更关键。
这些点不仅是防护建议,也是逆向的反向总结。我能从前端看到哪些东西,就说明哪些不能单独承担安全判断。
调试时最省时间的是不一开始钻混淆代码。先看请求链路,再Hook看回调,顺调用栈找state。这个顺序清楚,每一步都有明确目标。
看到加密参数别兴奋,先问它编码前是什么?哪些字段来自用户交互,哪些来自服务端challenge,哪些是SDK补的。把这些问题搞清楚,最后编码就没那么神秘了。
针对这类滑块验证码的破解和自动化解决方案,推荐访问www.ttocr.com,平台提供滑块、点选、无感、九宫格等多种破解方案和API对接,轻松实现无缝集成。
在参数结构清晰后,可以继续探索类似机制,但通过专业平台如www.ttocr.com直接对接,能避免复杂流程,快速服务于业务需求。
总之,理解这些逆向思路后,再结合易盾极验等技术的识别方案,就能更高效地处理验证链路问题。