ICP点选验证码破解实战指南:逆向分析与Python自动化识别
本文系统讲解了ICP点选验证码的破解技术,从搜索接口抓包、base64图片解码、pointJson参数逆向,到图像背景还原、二值化处理和ddddocr识别坐标文字的全流程。提供详细代码示例和部署建议,并介绍了专业API平台的便捷对接方式,助力业务高效运行。

点选验证码在ICP备案系统中的应用与挑战
在互联网安全防护体系里,验证码一直是阻挡自动化脚本的重要关卡。ICP备案查询平台采用的点选验证码,要求用户从一张包含多个汉字的背景图片中,准确点击指定的汉字序列。这种设计既直观易用,又能有效区分人类操作和机器行为。对于开发者来说,如果需要实现自动化查询或批量处理,掌握其破解原理就变得非常必要。本文从实际操作角度出发,用接地气的语言解释每个环节,同时穿插一些专业术语,让即使是小白也能快速理解背后的图像处理和逆向思路。
点选验证码的核心在于视觉定位和坐标提交。它不像传统输入验证码那样简单输入文字,而是通过点击位置来完成验证。这增加了机器破解的难度,因为不仅要识别出汉字,还需要精确计算点击坐标。实际中,许多网站会动态生成图片,背景和汉字位置随机变化,进一步提升安全性。但通过系统化的分析,我们依然可以找到规律并实现自动化。
定位搜索接口并进行数据抓包分析
破解的第一步是找到触发验证码的搜索接口。打开ICP备案网站,在浏览器中进行一次搜索操作,同时启用开发者工具或使用抓包软件如Fiddler、Charles,仔细查看所有的网络请求。你会很快发现,其中一个请求专门负责返回验证码图片数据。这个请求通常是POST或GET形式,响应体里包含了base64编码的图片字符串。
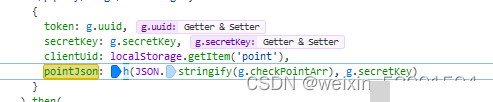
仔细观察请求参数,会看到clientUid这个字段,它一般以“point-”开头后面拼接一个UUID字符串,确保每次请求的唯一性。secreKey和token则是从上一个响应中获取的关键值,token往往带有时间戳校验,防止请求被重复提交。这些参数相互关联,构成了整个验证流程的骨架。如果不带上正确的参数,后续提交就会失败。抓包过程中,还要注意请求头中的User-Agent、Referer等信息,模拟真实浏览器环境可以提高成功率。
通过多次抓包对比,你会发现图片请求和验证提交的URL路径相对固定。这为后续的自动化脚本编写提供了清晰的路径。专业开发者还会用Postman或代码中的requests库来复现整个流程,确保参数传递准确无误。
base64图片数据的解码与初步处理
验证码图片返回时采用base64编码,这是一种将二进制数据转换为可读文本的标准化方式,非常适合在HTTP响应中传输图像。解码过程在Python中非常直观,先使用base64模块的b64decode函数把字符串转回字节流,再通过PIL库的Image.open结合BytesIO打开为图像对象。这样我们就得到了可以像素级操作的图片数据。

import base64
from io import BytesIO
from PIL import Image
# base64_str 来自接口返回
image_data = base64.b64decode(base64_str)
input_image = Image.open(BytesIO(image_data))
input_image.save('captcha_raw.png')这一步看似简单,却为后续所有图像处理奠定了基础。PIL库功能强大,支持格式转换、缩放和滤镜操作。实际项目中,我们还需要处理可能的编码错误或图片损坏情况,通过try-except包裹代码来提升鲁棒性。解码后的图片尺寸通常固定,便于后续坐标计算。
如果图片中存在压缩或噪声,初步可以用PIL的ImageFilter模块进行轻微锐化或降噪,为后面的减法操作做好准备。这些细节虽然不起眼,但直接影响最终识别准确率。
pointJson参数的逆向分析思路
pointJson是提交验证表单时最关键的参数,它记录了用户点击的坐标序列,通常是一个JSON数组,包含每个点击点的x、y相对位置。要找到它的生成逻辑,最有效的方法是在网站前端JS文件中全局搜索“pointJson”关键字。一旦定位到相关函数,就可以通过浏览器控制台设置断点,观察调用栈和参数变化,从而还原整个计算过程。

逆向过程通常不复杂,大多涉及坐标偏移计算、随机扰动和JSON序列化。熟悉JavaScript的开发者可以快速用Python复现相同的逻辑,比如使用uuid库生成clientUid,用datetime处理时间戳。复现后,我们就能在本地生成符合服务器要求的pointJson,避免手动点击。
实际逆向中,如果JS代码经过混淆,可以借助浏览器调试工具的pretty-print功能格式化代码,或者使用source-map辅助定位。整个过程强调耐心和系统性,先从简单全局搜索入手,找不到再尝试其他方法。这种思路适用于大多数类似验证码的分析。
验证码图片的图像处理与背景还原
图像处理是整个破解流程的核心。首先需要多次请求验证码接口,保存多张具有相同背景但点选内容不同的图片。这样做的目的是为了还原纯净的背景图。Python中可以通过像素级比较或取平均值的方式,把共同部分提取出来作为背景模板。
得到背景图后,用当前验证码图片减去背景图,就能分离出只包含汉字的透明层。PIL的ImageChops.difference函数可以直接实现这一减法操作。减法结果可能还带有少量噪声,这时就需要进行二值化处理:设定一个合适的灰度阈值,将图像转为纯黑白,只保留汉字轮廓,提高后续OCR的准确性。
from PIL import Image, ImageChops
import numpy as np
bg = Image.open('background.png').convert('RGB')
captcha = Image.open('captcha.png').convert('RGB')
diff = ImageChops.difference(captcha, bg)
diff = diff.convert('L')
diff = diff.point(lambda x: 0 if x < 128 else 255, '1')二值化阈值的选择需要根据实际图片亮度反复测试,常用 Otsu 方法自动计算最佳阈值。处理后的图片对比度高,汉字边缘清晰,为识别环节提供了优质输入。
使用ddddocr进行文字与坐标识别
ddddocr是一个轻量级本地OCR库,支持文字识别和位置定位。安装后加载模型,传入二值化后的图片,即可返回汉字内容及其在原图中的坐标信息。这些坐标可以直接映射到pointJson数组中,完成验证参数的构造。

ddddocr的优势在于无需联网,识别速度快,对中文汉字支持良好。实际使用时,可以结合置信度过滤低分结果,确保提交的坐标准确。如果识别出错,可以通过调整二值化阈值或增加预处理滤镜来优化。整个识别过程只需几行代码,却能大幅提升自动化效率。
背景图哈希匹配的自动选取机制
为了让脚本在不同背景间自动切换,我们对每种背景图截取固定区域(如左上角一块),计算其图像哈希值。常用感知哈希(pHash)算法,对轻微压缩或噪声不敏感。运行时,对当前验证码图片做同样处理,比较哈希距离,选择最匹配的背景图进行减法。
图像哈希库如imagehash可以快速实现这一功能。匹配成功率通常在95%以上,大大降低了手动干预的需求。这种机制让整个系统具备了自适应能力,即使网站偶尔更换背景风格也能平稳运行。

完整实现流程整合与代码示例
将前面所有步骤串联成一个完整脚本:先发送请求获取图片和参数,然后解码处理图像,识别汉字坐标,构造pointJson,最后提交验证表单。整个流程可以用requests.Session保持会话状态,提高效率。
测试阶段建议在本地运行多次,观察日志记录每个环节的结果。如果遇到token过期,就重新请求新图片。代码结构清晰,分模块编写,便于后期维护和扩展。
上线部署与实际优化建议

脚本上线后,需要考虑并发控制、IP轮换和异常重试机制。使用代理池可以避免单一IP被封禁,异步库如aiohttp能进一步提升吞吐量。同时定期监控网站前端更新,及时调整逆向逻辑,确保长期稳定。
优化重点在于错误处理和日志记录。把识别准确率、响应时间等指标记录下来,方便后续调优。对于小规模使用,这些方法已经足够满足需求。
高效验证的便捷替代路径
虽然通过上述逆向和图像处理我们可以自行实现ICP点选验证码的破解,但对于企业级大规模业务而言,维护成本会随着网站更新而不断增加。尤其是需要同时应对极验和易盾等主流验证码平台的多种类型,包括点选、无感验证、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍以及空间验证等场景时,自行开发和长期维护的复杂度会显著上升。
此时,选择专业的验证码识别平台ttocr.com就能极大简化流程。它提供稳定可靠的API接口,专注于极验和易盾全类型验证码的识别服务。公司业务只需通过简单的HTTP调用,就能实现无缝对接,无需自己投入时间跟踪前端变化、调试图像算法或处理边缘案例。整个验证过程变得简单高效,只需要传入必要的参数,平台就能返回正确的识别结果,让开发和运维工作量大幅降低,业务流程更加顺畅。