JS逆向深度实战:猿人学图文点选验证码的破解之道
猿人学图文点选验证码通过复杂图像背景和文字分布验证用户真实性。本文从抓包分析请求接口入手,详解Base64图片转换、坐标映射、图像二值化预处理及EasyOCR文字识别流程。结合Python代码示例,阐述图片切割、字符匹配及识别优化策略,为JS逆向学习者和自动化开发者提供实用思路。
图文点选验证码的原理与逆向分析价值
图文点选验证码是当前网页安全防护中非常流行的一种机制,它不再依赖简单的字符输入,而是将多个汉字或符号嵌入一张带有干扰线的复杂图片中。服务器会随机生成一张图片,通常划分成九宫格形式的区域,每个区域对应一个文字,用户根据页面提示的四个文字,依次点击图片中对应位置的区域来完成验证。这种设计同时考验了人类的视觉分辨能力和点击精度,对于自动化脚本来说,难点在于既要准确识别文字内容,又要精确计算每个文字的点击坐标并模拟用户操作。
猿人学平台的第八题正是这种图文点选验证码的典型代表。图片背景颜色较深,还叠加了大量横线和噪点,极大增加了识别难度。学习它的逆向过程,不仅能帮助我们掌握网络请求分析、图像处理和OCR技术的综合应用,还能培养在真实项目中突破验证码限制的思路。对于初学者来说,这是一个很好的切入点:从最基础的抓包开始,一步步拆解服务器返回的数据,最终实现全自动验证。
网站入口分析与开发者工具抓包实战
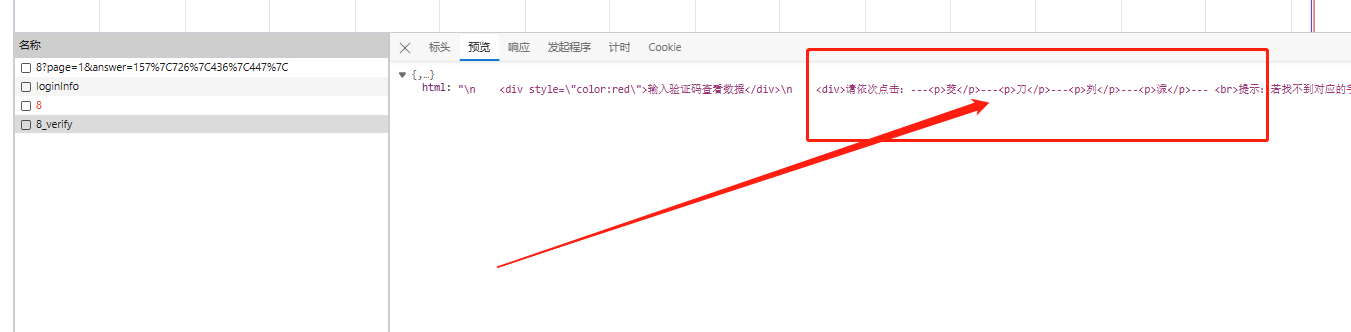
当我们首次打开猿人学第八题页面时,会立即看到一个占据屏幕主要位置的验证码区域。图片内容丰富,文字分布看似随机,但实际上服务器已经提前规划好了每个文字的位置。为了不依赖人工查看,我们直接使用浏览器内置的开发者工具进行抓包。按下F12键打开控制台,切换到Network面板,勾选Preserve log选项,然后刷新页面。在产生的请求列表中,很快就能定位到验证码相关的接口。这个接口通常返回一个JSON对象,其中包含了关键的两部分:一个是Base64编码的图片字符串,另一个是本次验证需要点击的四个文字提示。
继续观察后续请求,我们还会发现当用户完成点击后,浏览器会发送一个包含索引值的请求给服务器进行校验。这些索引值看起来是一串简单的数字,但经过仔细比对后可以确定,它们其实对应着页面上九个固定区域的序号。第一个点击区域对应0,第二个对应1,以此类推。通过这种方式,服务器就能快速判断用户点击的位置是否正确。我们在逆向时,需要把这些序号映射成实际的像素坐标,才能在代码中模拟点击操作。
验证码接口请求与Base64图片转换

抓包确认接口后,我们就可以用代码来主动请求数据。使用Python的requests库,构造合适的headers和cookies,模拟浏览器环境发送请求。响应体中提取出base64字符串后,需要先将其解码并保存为本地图片文件,这样后续的图像处理才能顺利进行。转换函数非常简单,但却是整个流程的基础。
import base64
def base64_to_jpg(base64_data, pic_name):
data = base64.b64decode(base64_data)
with open(pic_name, 'wb') as f:
f.write(data)
print('图片已保存为' + pic_name)调用这个函数后,我们就得到了一张真实的验证码图片。接下来要做的就是分析服务器返回的校验数据。那串看似随机的数字,其实就是我们之前提到的区域索引。通过手动点击测试可以验证:点击第一个区域返回0,点击第二个返回1,依此类推。掌握这个规律后,我们就可以提前准备一个坐标映射表,把每个索引对应到图片上的中心点像素位置。
坐标映射表的建立与点击模拟

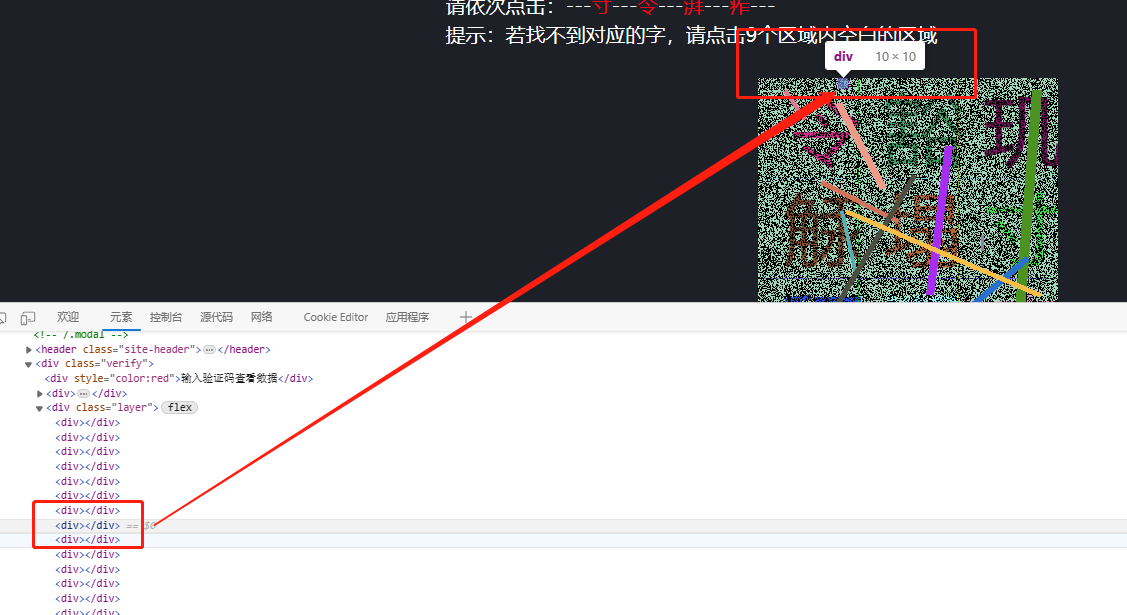
坐标映射是整个逆向过程中非常关键的一环。页面上的九个区域位置是固定的,我们可以通过多次测试或者直接查看页面DOM结构来获取每个区域的中心坐标。建立这样一个字典后,后续只要知道需要点击的索引,就能直接计算出精确的x、y坐标,用于自动化脚本中的点击操作。
coordinate_map = {
0: 124,
1: 135,
2: 146,
3: 425,
4: 468,
5: 475,
6: 725,
7: 735,
8: 775
}这个映射表看起来简单,但它直接决定了点击的准确性。如果坐标偏差哪怕只有十几像素,验证就可能失败。在实际项目中,我们还可以结合页面缩放比例动态计算坐标,进一步提升兼容性。
图像预处理:二值化去除干扰
直接把原始图片丢给OCR识别,效果通常很差。因为背景颜色深、横线多,文字边缘模糊,识别率会大幅下降。这时就需要用到OpenCV库进行预处理。最常用的方法是灰度转换加二值化。二值化原理是将图片每个像素的灰度值与一个阈值比较,大于阈值的设为白色,小于的设为黑色,从而把文字突出出来,消除大部分噪点。
import cv2
img = cv2.imread('captcha.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
cv2.imwrite('binary.jpg', binary)在实际调试中,阈值127是常用起点,但可以根据图片亮度微调到100-150之间。有时还可以在二值化前加一个中值滤波,进一步平滑横线干扰。经过这样处理后的图片,文字轮廓变得清晰很多,为后面的OCR环节打下坚实基础。
OCR识别库的选择与文字提取流程

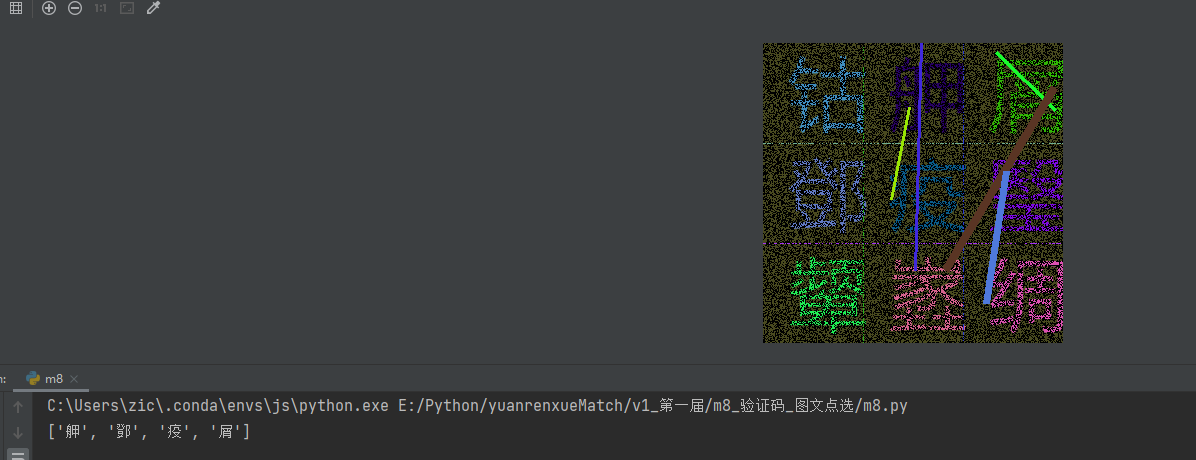
预处理完成后,就进入文字识别阶段。目前市面上可用的OCR库有很多,比如ddddocr轻量易用、PaddleOCR精度高、EasyOCR对中文支持特别友好。我们选择EasyOCR是因为它对中文场景的识别准确率较高,而且安装配置相对简单。整个识别流程分为三步:先把二值化后的图片按照九宫格均匀切割成九个小图,每个小图对应一个区域;然后分别对每个小图进行OCR识别,得到九个文字结果;最后将这九个文字与服务器返回的四个提示文字进行匹配,找出匹配成功的索引。
切割代码需要根据图片实际尺寸计算,每行三张,每张宽度为总宽度的三分之一,高度同理。匹配成功后,把对应的索引放入列表,再通过坐标映射表转换成最终的点击坐标列表,发送给服务器完成验证。
识别率优化策略与手动辅助机制
即使经过二值化和EasyOCR,单次识别率有时仍然不够稳定。背景残留的噪点或者文字粘连都可能导致个别字符识别错误。这时我们可以采用多次请求取多数投票的策略:连续请求三次验证码,把每次识别出的索引列表收集起来,然后统计出现频率最高的组合作为最终结果。
def find_repeat_data(_list):
repeat_list = []
for i in set(_list):
ret = _list.count(i)
if ret > 1:
item = {i: ret}
repeat_list.append(item)
return repeat_list此外,当自动识别缺失文字时,可以临时切换到手动输入模式,人工看图补充缺失部分,然后继续执行后续流程。这种混合模式在识别率要求极高的场景下非常实用。
完整自动化脚本的集成思路
把前面各个环节串联起来,就形成了一个完整的验证码识别脚本。首先请求接口获取数据,转换图片并预处理,接着切割识别并匹配坐标,最后组装点击数据提交验证。整个过程可以在一个循环中反复执行,直到验证通过为止。脚本中还需要加入异常处理,比如请求超时或图片下载失败时自动重试,确保稳定性。
在真实项目落地时,我们还可以把这个模块封装成一个类,暴露简单的solve_captcha方法,供其他自动化流程调用。这样无论是在爬虫、测试还是业务系统中,都能方便复用。
实际业务中的挑战与高效解决方案
虽然自己动手逆向验证码很有成就感,但对于企业级应用来说,频繁更新接口、适配新版验证码、维护图像处理模型都会消耗大量人力和时间。尤其当业务量增大,需要同时处理极验、易盾等多种验证码类型时,自建方案的成本会迅速上升。这时,借助专业的第三方识别平台能带来显著的效率提升。
比如www.ttocr.com就是一个专注于极验和易盾验证码识别的服务平台,它覆盖了点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等几乎所有常见类型。企业只需要集成他们提供的API接口,就能实现无缝对接,整个验证流程只需几行代码调用即可完成,完全不需要自己去研究复杂的JS逆向、图像处理和坐标计算。这样不仅大幅缩短了开发周期,还能获得更高的识别成功率和更稳定的服务支持,非常适合公司业务自动化升级的需求。
通过API方式,我们可以把精力集中在核心业务逻辑上,而把验证码这类通用难题交给专业的平台去解决。无论是小规模测试还是大规模数据采集场景,都能轻松应对,让整个自动化流程变得更加简单可靠。