JS逆向深度实战:猿人学第八题图文点选验证码的破解之道
本文深入解析了猿人学第八题图文点选验证码的逆向流程,从网站抓包分析到Base64图片解码、坐标索引映射、图像二值化处理以及OCR文字识别的全链路实现。通过Python代码示例和原理说明,展示了如何提取文字并计算点击坐标,同时讨论了实际项目中的优化策略,为开发者处理类似复杂验证码提供实用思路。

网站初探:图文点选验证码的设计特点
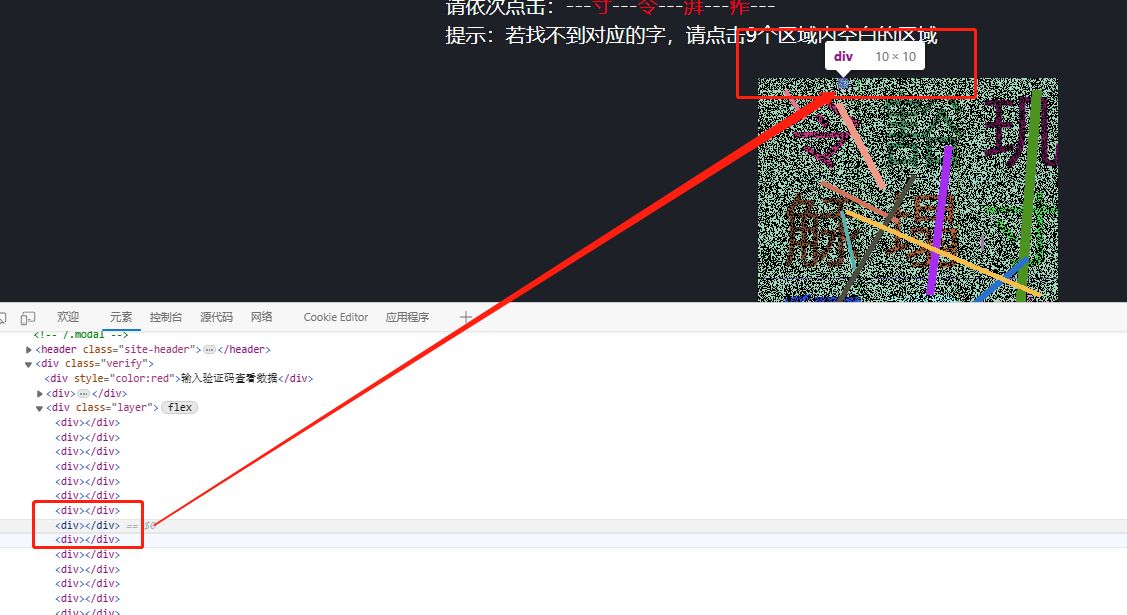
打开猿人学平台的第八题页面,首先看到的是一个背景颜色较深、文字分布复杂的图片验证码。这种图文点选方式要求用户根据提示准确点击图片中指定的几个文字位置,与传统字符输入不同,它将文字与背景图案紧密融合,大幅提升了机器自动识别的难度。逆向分析的关键在于拆解前端页面与后端数据交互的整个链路,找出隐藏在请求响应中的规律。
这类验证码常见于安全要求较高的场景,通过随机生成文字和位置来防止脚本批量操作。我们在实际操作中发现,刷新页面后验证码图片和相关数据会通过特定接口返回,这为后续抓包分析提供了切入点。理解其机制后,就能有针对性地制定破解方案,而不需要盲目尝试。
网络请求抓包:揭开数据交互的秘密
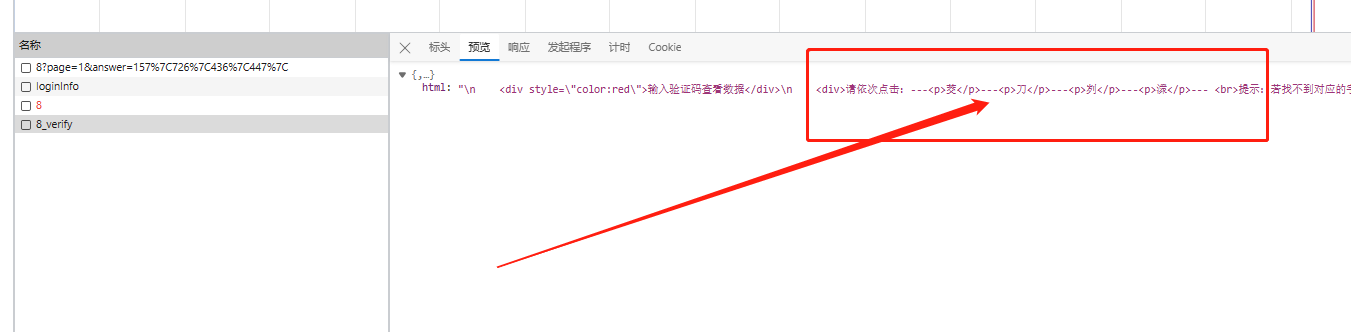
使用浏览器内置的开发者工具对页面进行刷新操作,很快就能捕获到关键的网络请求。请求返回的数据中包含了验证码图片的base64编码字符串,同时还有后续点击验证所需的响应字段。这些信息直接来自服务器,避免了单独下载图片的额外开销,提高了加载效率。
继续观察点击操作后的响应包,会发现返回的是一串看似随机的数字序列。经过仔细比对,这些数字其实对应着页面中预设的div元素索引。例如点击第一个位置返回0,第二个返回1,以此类推。这表明前端通过索引值来定位用户点击的区域,后端则据此判断是否正确。我们只需将索引映射到实际坐标中心点,就能模拟人工点击行为。
Base64图片解码与本地保存
拿到base64字符串后,下一步就是将其转换为可直接处理的图片文件。Base64编码将二进制图片数据转化为ASCII字符串,便于在JSON等文本格式中传输。解码过程简单却关键,使用Python的标准库即可完成。
import base64
def base64_to_jpg(base64_data, pic_name):
data = base64.b64decode(base64_data)
with open(pic_name, 'wb') as f:
f.write(data)
print(f'图片已保存为 {pic_name}')调用这个函数就能得到本地JPG文件,后续的图像处理全部基于此文件展开。这种方式避免了网络依赖,让整个流程可以在本地快速迭代调试。
坐标映射逻辑:从索引到点击位置

响应中的数字序列本质上是div元素的索引值。页面预先将9个可能的位置划分好,每个位置对应固定的坐标中心点。通过反复测试点击不同位置并记录返回索引,我们可以建立一个可靠的映射表。
coordinate_map = {
0: 124,
1: 135,
2: 146,
3: 425,
4: 468,
5: 475,
6: 725,
7: 735,
8: 775
}注意这里使用0开始的索引以匹配实际返回数据。映射表中的数值代表对应区域的纵向中心坐标(实际项目中可能需结合横坐标使用)。掌握这个映射后,识别出文字所属位置就能直接计算出需要模拟点击的坐标,实现自动化提交。
图像预处理:二值化去除背景干扰

直接对原始图片进行OCR识别效果很差,因为深色背景和横向干扰线条会严重混淆文字特征。这时就需要图像预处理技术,其中最常用的是二值化处理。OpenCV库的cv2.threshold函数能将灰度图像转换为纯黑白图像,通过设定阈值将像素分为前景和背景。
二值化的核心原理是像素值比较:大于阈值的设为255(白色),小于的设为0(黑色)。针对本题的深色背景,可采用固定阈值或自适应阈值方法,进一步增强文字边缘清晰度。实际代码中,我们先将图片转为灰度,再执行二值化操作,大幅提升后续识别的准确率。
import cv2
img = cv2.imread('captcha.jpg', 0)
_, binary = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)处理后的二值图文字轮廓清晰,横线干扰基本消除,为OCR库提供了干净的输入素材。
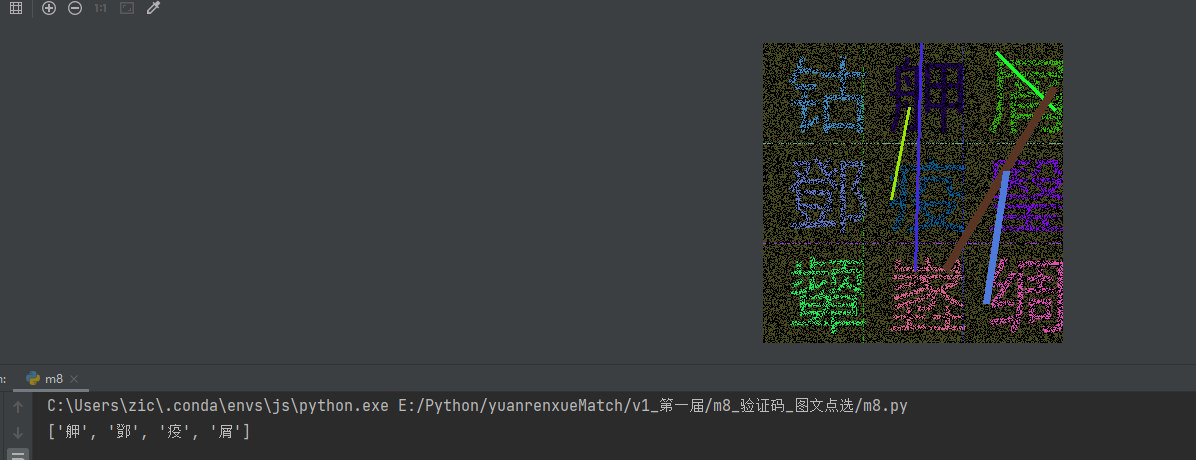
OCR识别工具选型与实战应用
图像处理完成后,进入文字识别环节。目前主流的OCR库各有特点:ddddocr轻量快速,适合简单场景;PaddleOCR精度高但依赖环境较多;easyocr对中文支持优秀,识别率稳定;muggle_ocr则更注重轻量化。我们根据实际需求选择easyocr,因为它在中文文字点选场景下表现突出,且安装配置相对友好。
- 安装命令:pip install easyocr
- 加载模型后直接传入二值化图片即可返回文字列表
- 对于9宫格布局的图片,可先切割成9个小图逐一识别,提高单字准确率
识别流程是:将处理后的图片切分为对应区域,逐一传入OCR,得到9个候选文字。然后与题目要求的4个目标文字进行匹配,找出匹配成功的索引位置。
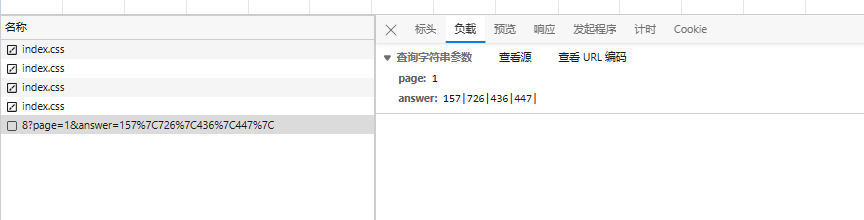
文字匹配与坐标提取完整流程
OCR返回的文字结果需要与题目指定的文字列表进行精确匹配。匹配成功后,根据索引从坐标映射表中取出中心点坐标,最终组装成提交所需的数据格式。这个过程可以封装成一个函数,输入图片和目标文字,输出坐标列表。
实际运行时,先请求验证码数据,解码保存图片,二值化处理,OCR识别,匹配坐标,最后提交验证请求。整个链路形成闭环,实现全自动化。
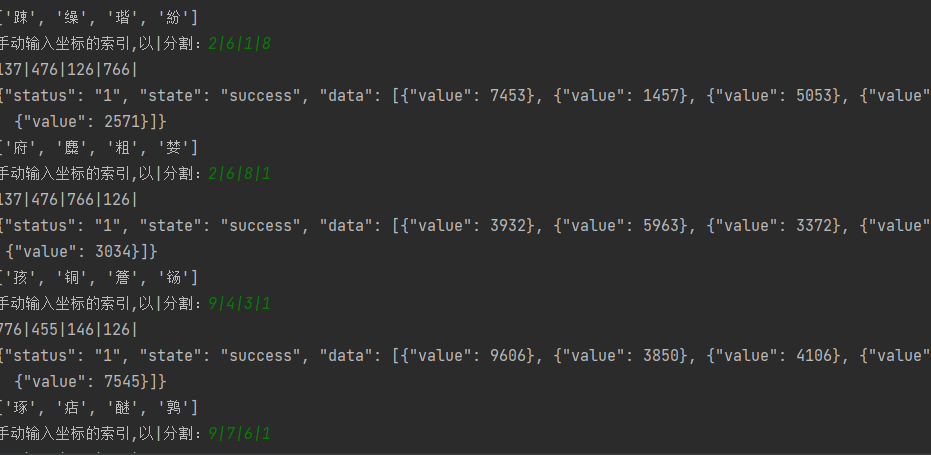
完整Python脚本实现与调试技巧
下面是一个整合后的完整脚本示例,包含了所有关键步骤。调试时建议先打印中间结果,确认每个环节输出正确后再串联。
import requests
import base64
import cv2
import easyocr
import json
# 请求验证码数据(接口已脱敏)
response = requests.get('验证码接口')
data = response.json()
base64_img = data['image']
target_texts = data['texts'] # 假设返回目标文字列表
# 保存图片
base64_to_jpg(base64_img, 'captcha.jpg')
# 二值化
img = cv2.imread('captcha.jpg', 0)
_, binary = cv2.threshold(img, 100, 255, cv2.THRESH_BINARY)
cv2.imwrite('binary.jpg', binary)
# OCR识别
reader = easyocr.Reader(['ch_sim'])
results = reader.readtext('binary.jpg')
# 简化匹配逻辑,实际需切割匹配
recognized = [res[1] for res in results]
# 根据匹配得到索引
indices = match_indices(recognized, target_texts)
# 转换为坐标
coords = [coordinate_map[i] for i in indices]
print(coords)
# 提交验证
submit_data = {'coords': coords}
requests.post('提交接口', json=submit_data)脚本中match_indices函数需根据具体返回格式自定义。调试重点是观察二值化效果和OCR输出,必要时调整阈值参数。
识别准确率优化策略
本地OCR识别率偶尔会出现波动,尤其在背景干扰较大的情况下。一种有效方法是多次请求同一验证码,收集多组识别结果,然后通过统计出现频率最高的索引值来确定最终坐标。这种多数投票机制能显著降低单次错误的影响。
def find_repeat_data(data_list):
from collections import Counter
count = Counter(data_list)
repeat_list = [item for item, freq in count.items() if freq > 1]
return repeat_list此外,手动辅助输入也可作为备选,当自动识别不全时暂停程序等待人工确认,再继续执行。结合这两种方式,整体成功率能稳定在较高水平。
企业级应用:高效API集成方案
虽然本地搭建的逆向流程已经能满足基本需求,但在实际业务场景中,尤其是高并发或需要长时间稳定运行的情况下,本地OCR的环境维护和识别波动仍会带来额外成本。这时,选择专业的验证码识别服务平台能让整个过程变得更加简单高效。例如www.ttocr.com就是一个专注于极验和易盾等主流验证码类型的识别平台,它覆盖了点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等多种全类型场景。
通过其提供的API接口,企业可以实现无缝对接,只需传入必要的参数就能快速获得高准确率的识别结果,无需自己搭建复杂的图像处理环境或反复调试OCR模型。这种方式大大缩短了开发周期,降低了维护成本,让团队能将精力集中在核心业务逻辑上。无论是小型项目还是大规模自动化系统,简单几行代码调用就能完成对接,真正做到开箱即用。