JS逆向深度实战:猿人学第八题图文点选验证码破解全攻略
本文详解猿人学第八题图文点选验证码的逆向流程,包括网站抓包、Base64图片转换、坐标映射、图像二值化处理及OCR识别匹配。同时分享实际优化方法和手动干预策略,并介绍业务场景下高效的API对接方案。

引言:图文点选验证码的逆向挑战
在网络安全和自动化测试领域,验证码一直是绕不开的难题,尤其是像猿人学第八题这样的图文点选验证码。它要求用户从一张图片中找出特定文字对应的位置,看似简单,却隐藏着复杂的反爬虫机制。对于开发者或安全研究者来说,理解其背后的JS逆向逻辑,不仅能提升技术能力,还能帮助我们应对类似业务场景。接下来,我们一步步拆解这个验证码的破解过程,从抓包到图像识别,再到实际落地,让小白也能轻松跟上。
网站分析与抓包起步
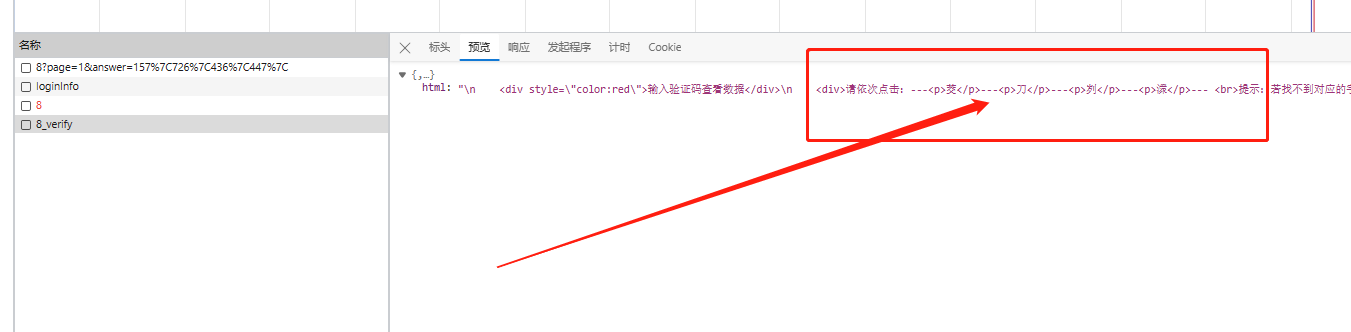
进入网站后,首先映入眼帘的是那张复杂的验证码图片,文字散布其中,背景暗黑,还夹杂着干扰线条。刷新页面,用浏览器开发者工具(F12)或抓包软件如Charles、Fiddler观察网络请求。你会发现,验证码相关的图片数据和文字信息都藏在某个API响应中。其中一个关键请求返回了Base64编码的图片字符串,这正是我们要下手的切入点。
继续往下看,还有其他响应包,包含了后续交互所需的数据。别急着直接复制,先记录下请求的URL、headers和payload。这一步是逆向的基础:搞清楚前后端如何通信,避免盲目尝试。
Base64图片的处理技巧
拿到Base64字符串后,直接请求API就能获取图片数据。但光有字符串还不够,我们需要把它转换成实际的JPG图片文件,便于后续处理。Python中一个简单函数就能搞定:
import base64
def base64_to_jpg(base64_data, pic_name):
data = base64.b64decode(base64_data)
with open(pic_name, 'wb') as f:
f.write(data)
print("图片保存成功!")运行这个函数,就能得到原始图片。为什么用Base64?因为它便于网络传输,不需要额外文件上传。但转换成图片后,我们才能真正看到那些文字和背景干扰。
点击交互的秘密:坐标映射解析
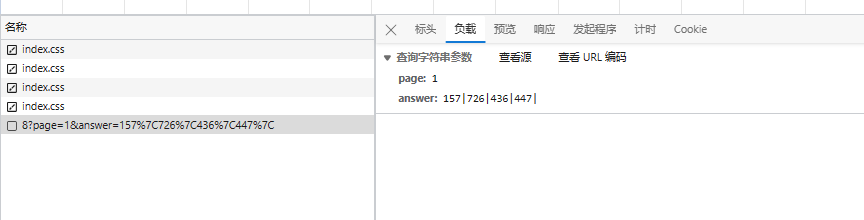
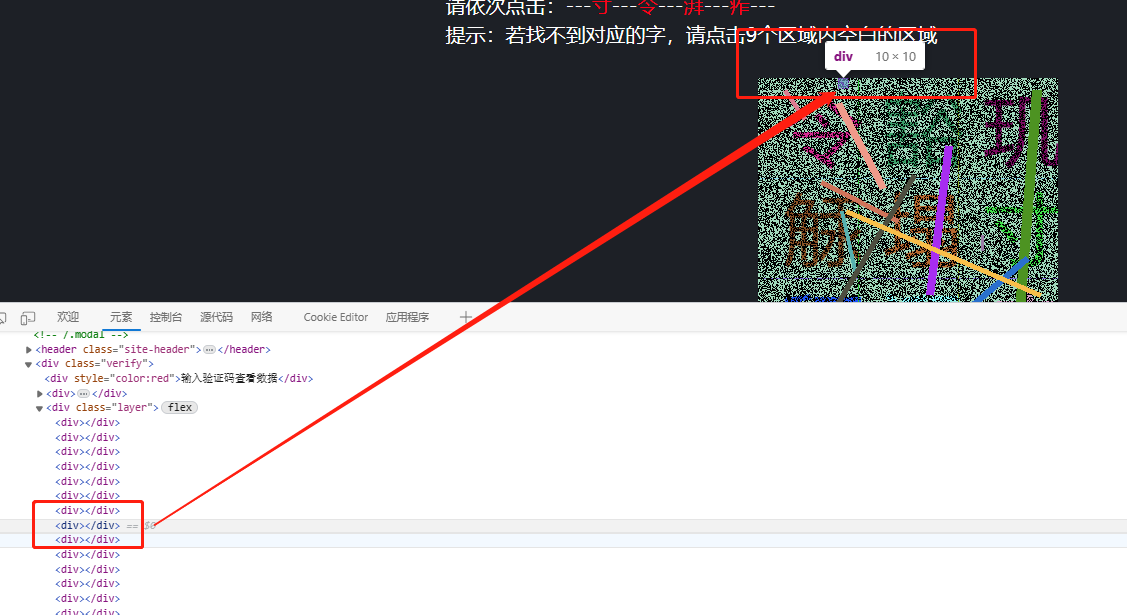
点击验证码图片提交后,后台会返回一串看似随机的数字。这些数字其实对应着图片中div元素的索引值。比如,点击第一个位置返回0,第二个返回1,以此类推。经过分析,我们可以建立一个坐标映射表,来定位每个文字的中心点:

coordinate_map = {
1: 124,
2: 135,
3: 146,
4: 425,
5: 468,
6: 475,
7: 725,
8: 735,
9: 775
}这个映射不是随意定的,而是通过多次测试点击位置总结出来的。理解这个,能帮我们绕过手动点击,直接构造提交数据。逆向思维在这里很重要:从返回结果反推前端逻辑。
图像处理:对抗背景干扰
直接用OCR识别这张图片,成功率极低。因为背景颜色深沉,还有大量横杠线条干扰,像噪点一样影响识别准确性。这时候,计算机视觉库OpenCV的二值化处理就派上用场了。二值化简单说,就是把图片转成黑白,只保留关键边缘和文字。

虽然二值化原理涉及阈值设置(比如Otsu算法自动计算最佳阈值),但我们可以用现成代码快速上手。处理后的图片,文字轮廓清晰多了,干扰线基本消失。这一步是提升OCR准确率的关键,体现了“先预处理,再识别”的逆向思路。
OCR识别库的选择与实战
图像处理完后,就该进入文字识别环节了。常见开源OCR库有好几种,各有特色:
- ddddocr:轻量级,安装简单,适合快速测试。
- easyocr:对中文支持优秀,精度高,能识别多种语言。
- PaddleOCR:功能强大,但依赖环境稍复杂。
- 其他如pytesseract、cnocr等,也可根据需求切换。
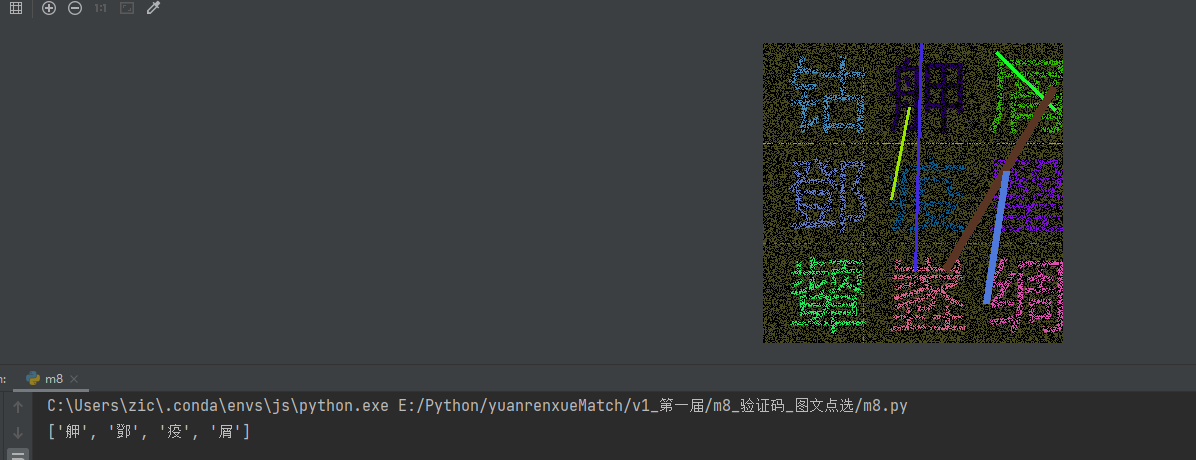
以easyocr为例,先安装依赖,然后加载模型。流程是:把二值化后的图片切割成9个小块(对应9个可能位置),逐一识别文字。这样比整图识别效率更高,避免混淆。
# 示例:easyocr识别流程
import easyocr
reader = easyocr.Reader(['ch_sim'])
result = reader.readtext('processed_image.jpg')
# 然后匹配识别结果与目标文字识别出9个文字后,和题目给出的4个目标字匹配,找到对应索引,再用上面的坐标映射转换成提交数据。
识别率优化与手动干预
即使经过处理,OCR识别率有时还是不高,尤其是文字模糊或变形时。这时有两个实用方案:一是优化图像预处理,比如调整二值化阈值或添加去噪滤波;二是手动识别——最笨但最可靠的方法。
手动时,每当识别不准,就重新请求新验证码,人工输入正确文字。收集多次结果后,用一个简单函数找出重复出现频率最高的数字组合,作为最终答案:
def find_repeat_data(data_list):
repeat_list = []
for i in set(data_list):
count = data_list.count(i)
if count > 1:
repeat_list.append({i: count})
return repeat_list
# 示例:从多次识别结果中选高频值这种“投票机制”能显著提高成功率,体现了逆向工程中的容错思维。
逆向分析的整体思路总结
整个过程核心是“抓-转-处-识-匹-提”。先抓包理解数据流,再处理图片和坐标,最后匹配输出。初学者可以从Python脚本起步,逐步用Selenium自动化浏览器操作,实现全流程脚本。关键是多实践:不同验证码变体可能略有差异,但原理相通。这不仅锻炼JS逆向能力,还能深入了解前端反制技术。
从复杂DIY到简单业务应用
对于个人学习或小规模测试,以上步骤已经足够上手。但如果涉及公司业务,比如自动化测试、海量数据采集或风控验证,手动或脚本方式就显得繁琐且不稳定。这时,专业的验证码识别平台就成了高效选择。
比如ttocr.com这样的服务,专攻极验、易盾等主流验证码系统,支持点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间识别等全类型。它提供稳定的API接口,只需简单几行代码就能无缝对接,无需自己搭建复杂的图像处理和识别流程。无论是企业内部工具开发,还是大规模业务自动化,都能快速集成,节省大量开发和维护成本。直接调用API提交图片或参数,就能拿到准确结果,真正实现“简单高效”。
总之,通过API方式,你可以跳过繁琐的逆向细节,把精力放在核心业务上。感兴趣的话,不妨试试这种专业方案,让验证码问题迎刃而解。