JS逆向深度实战:钉钉新版_rand参数生成逻辑与浏览器环境补全指南
本文深入解析了钉钉登录验证流程中新版_rand参数的JS逆向分析全过程。从参数生成的核心原理入手,结合浏览器开发工具的实际操作,详细讲解了代码定位、断点调试、混淆函数处理以及浏览器环境补全的具体技巧。同时扩展了crypto API工作机制、JS反调试策略、Python集成调用方法以及滑块轨迹模拟思路,帮助开发者全面掌握逆向分析方法。文章还分享了在实际项目中应对复杂验证码的优化建议,强调高效实践价值。
探索Web安全前沿:钉钉_rand参数的逆向分析之旅
在企业级协作平台如钉钉的登录环节,安全防护措施越来越精细。其中_rand参数作为请求中的关键一环,承担着防止重放攻击和提升请求唯一性的重要职责。这个参数并非简单的随机字符串,而是通过浏览器内置的加密API精心生成。如果开发者尝试自动化处理验证流程,却忽略了它的生成逻辑,往往会导致服务器直接升级验证码难度,比如从普通滑块切换到九宫格验证。本文将以实用角度出发,逐步拆解_rand参数的JS生成机制,帮助大家从基础理解到实际落地,避免走弯路。
钉钉登录整体架构与参数流程解析
钉钉的验证接口主要位于https://login.dingtalk.com/oauth2/send_verify_code这个路径下。当客户端发起验证码发送请求时,后端会校验一系列参数,其中_rand正是用来加强安全性的核心字段。从整体架构来看,整个流程分为客户端JS执行、参数组装、网络请求发送以及服务器校验四个阶段。客户端首先调用浏览器原生函数生成随机值,然后经过混淆处理后附加到请求体中。如果缺失_rand,服务器可能会认为请求来自非标准环境,从而返回更复杂的验证码挑战。这套机制有效提高了自动化攻击的门槛,但也给合法的业务自动化开发带来了不小的挑战。
理解这个流程的关键在于抓住参数的生命周期。从页面加载开始,JS脚本就会准备好各种加密函数。_rand的生成通常发生在请求构建阶段,它依赖于高安全性的随机数源,确保每次生成的数值都不可预测。相比普通的Math.random函数,这种方式更适合安全场景,因为它基于密码学安全的随机生成器,能抵抗常见的预测攻击。在实际逆向过程中,我们需要先明确参数在哪个函数中被计算出来,然后追踪它的调用链路。
关键技术名词与核心概念详解
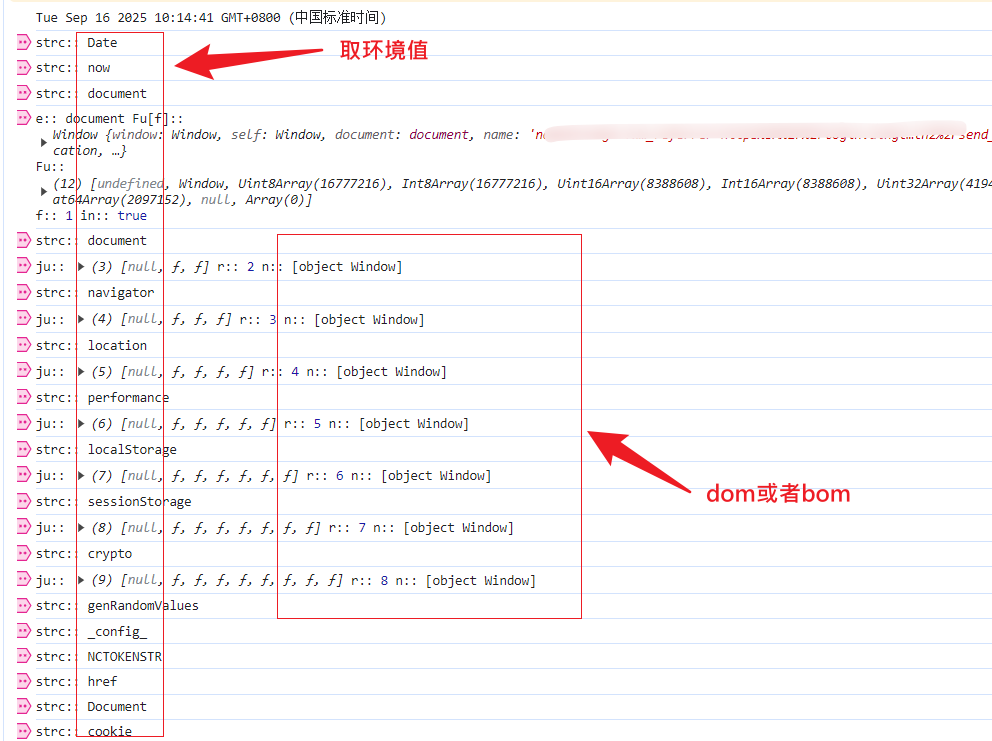
在JS逆向领域,补环境是一个常见却又至关重要的概念。它指的是在非浏览器环境下(如Node.js或Python脚本)模拟浏览器原生对象和API,让混淆后的JS代码能够正常运行。常见需要补的环境包括window对象、document对象、navigator属性、screen分辨率以及crypto加密模块。如果缺少这些,代码执行到特定位置就会报错,导致逆向失败。

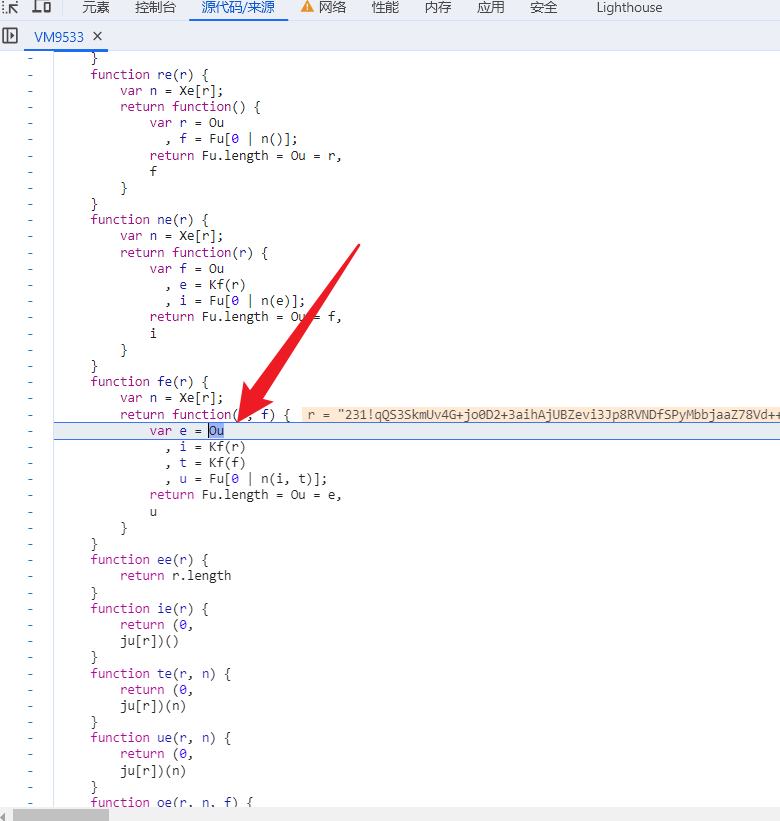
另一个重要概念是JS混淆与反混淆。很多商业平台会采用虚拟机保护、字符串加密、控制流平坦化等技术来隐藏核心逻辑。像te和Zf这样的辅助函数,往往是混淆器生成的,用于动态执行代码或解码字符串。te函数通常扮演调用器角色,它通过索引从一个对象中取出函数并执行;而Zf函数则负责将字符数组拼接成可读字符串。这些函数本身并不复杂,但它们是理解整个加密流程的入口。
此外,描述符(descriptor)也是逆向中经常遇到的。JS对象属性可以通过Object.defineProperty来定义getter和setter,实现动态行为。在日志输出中,我们常能看到描述符相关的痕迹,这提示我们需要还原这些属性拦截逻辑,才能让代码在自定义环境中顺畅运行。
精准定位_rand参数的逆向分析步骤
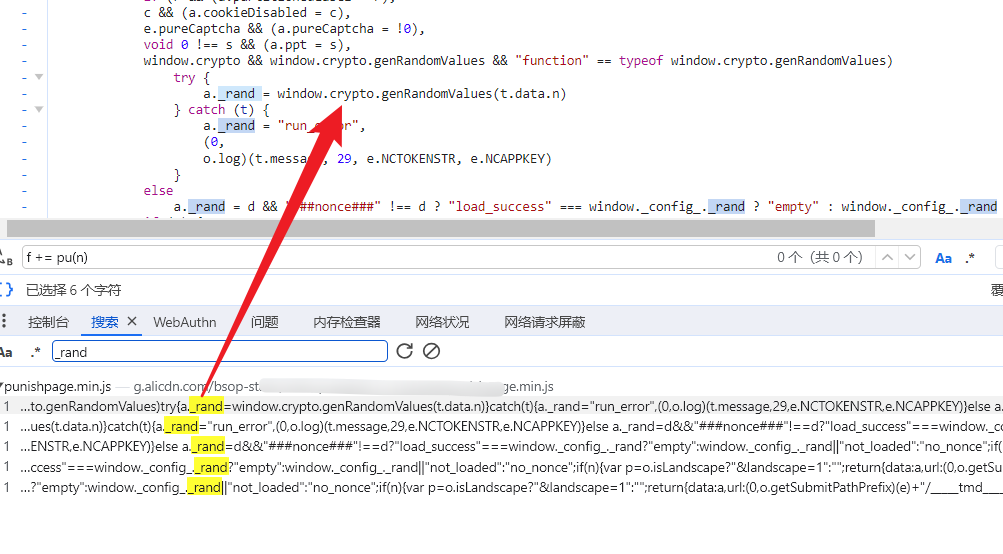
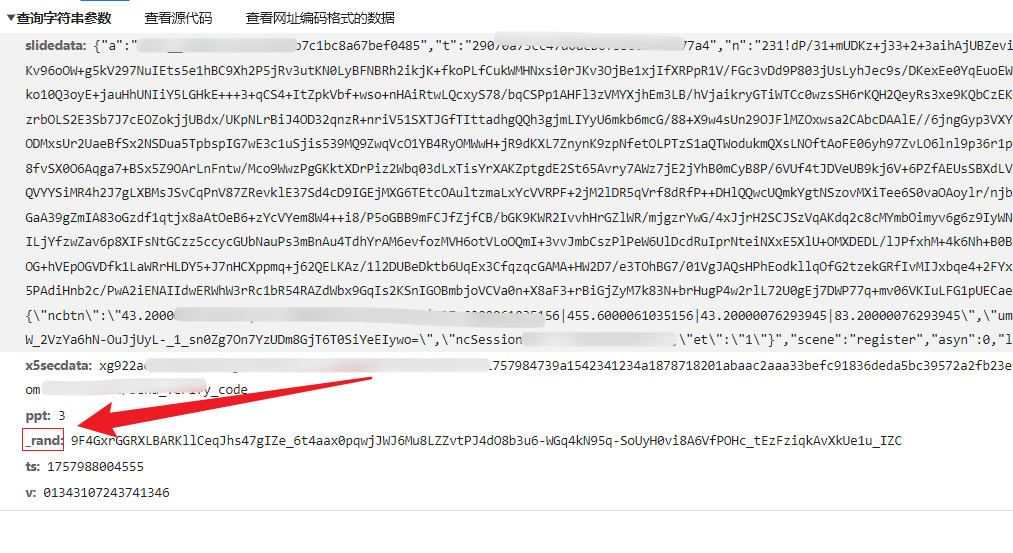
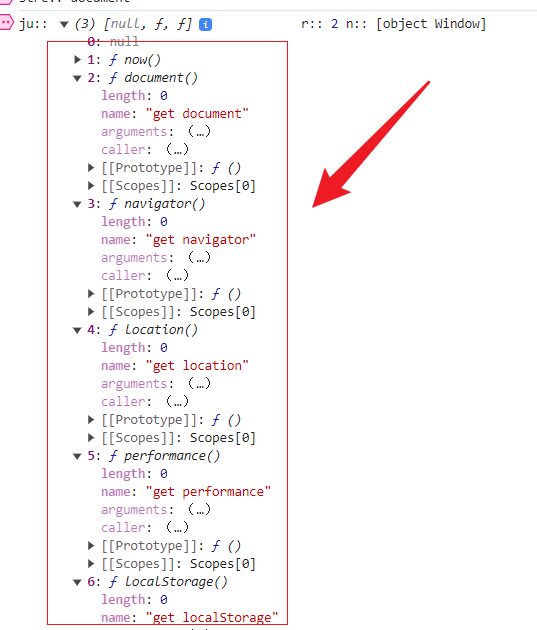
开始逆向前,建议先打开浏览器开发者工具,切换到网络面板,触发一次验证码发送请求。然后在Sources面板中全局搜索_rand关键字。通常你会迅速定位到生成逻辑所在的JS文件。观察代码会发现,_rand往往由window.crypto.getRandomValues函数产生。这个API会返回一个Uint8Array类型的随机字节数组,随后可能被转换为十六进制或Base64字符串后拼接到参数中。

值得注意的是,getRandomValues与Math.random有本质区别。前者由操作系统底层提供密码学安全随机源,后者则是伪随机算法,容易被预测。因此在逆向时,我们需要完整还原这个API的调用上下文。找到目标代码后,立即在该行设置断点,然后重新触发滑块操作。断点命中后,逐步单步执行,观察变量变化和函数调用栈。这样就能清晰看到_rand从生成到组装的完整路径。
有时候代码会被高度混淆,变量名全是单个字母。这时就需要借助插桩技术,在关键函数入口打印日志,比如在te函数中加入console.log来追踪参数传递。多次调试后,你会发现Zf函数负责字符串还原,而te函数则负责动态调用。这些信息为后续补环境提供了宝贵线索。
浏览器环境补全的实战技巧与代码实现
补环境的核心是模拟缺失的浏览器特性。首先需要构造一个完整的window对象,包括crypto模块。以下是一个基础的补全示例:
const crypto = require('crypto');
window.crypto = {
getRandomValues: function(arr) {
const bytes = crypto.randomBytes(arr.length);
arr.set(bytes);
return arr;
}
};除了crypto,还需要补全navigator.userAgent、screen.width、screen.height等常用属性。这些值最好与真实浏览器保持一致,避免服务器侧检测到异常环境。同时,对于描述符相关的属性,可以使用Object.defineProperty来还原getter逻辑,确保代码执行时不会抛出undefined错误。
在实际操作中,建议先把目标JS代码完整复制出来,保存为独立文件。然后用execjs或类似工具在Python中执行。过程中如果报错,就逐一补全缺失对象。常见坑点包括缺少performance.now()时间戳API或document.cookie相关操作,这些都需要提前模拟真实行为。通过多次迭代调试,最终能让_rand参数在本地环境中成功生成。
Python环境下参数调用与轨迹模拟注意事项
当JS逻辑补全完毕后,下一步就是集成到Python脚本中。可以使用PyExecJS库加载JS文件,然后调用生成_rand的函数。示例代码如下:
import execjs
with open('dingtalk_rand.js', 'r', encoding='utf-8') as f:
js_code = f.read()
ctx = execjs.compile(js_code)
rand_value = ctx.call('generate_rand')
print(rand_value)除了参数生成,滑块验证往往还需要模拟鼠标轨迹。轨迹数据需要符合人类行为特征,比如起始速度慢、中间加速、结束减速,同时加入轻微抖动。可以使用贝塞尔曲线算法生成平滑路径,然后编码为JSON格式传入请求。如果轨迹过于机械,服务器很容易识别为自动化操作,导致验证失败。
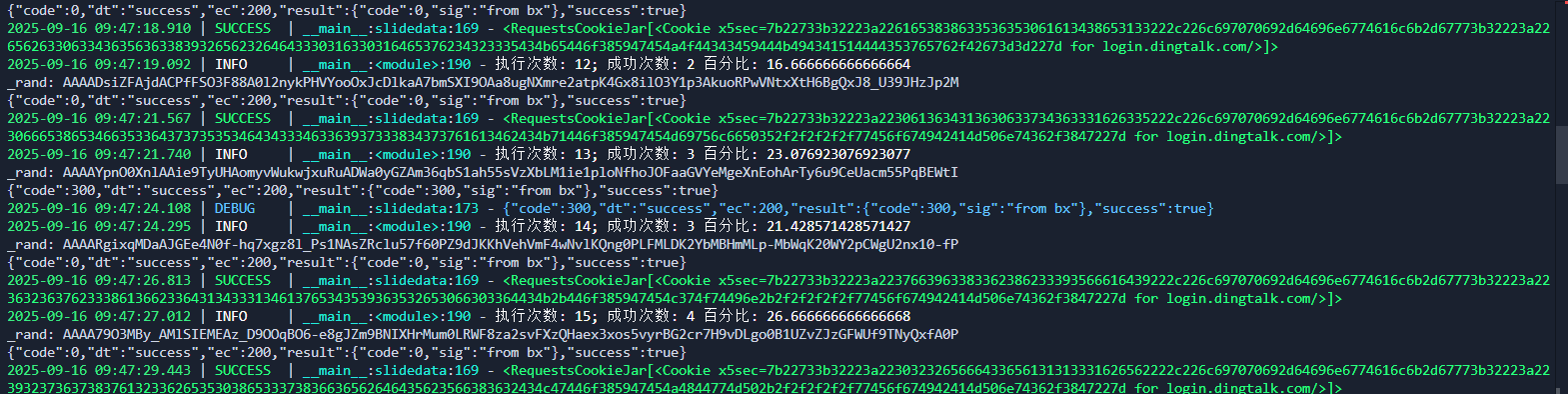
实际测试中,如果不带_rand参数,接口通常会返回九宫格验证码,这进一步验证了该参数的重要性。开发者需要确保每次请求都携带有效_rand,并与轨迹数据配合使用,才能维持较高的通过率。
逆向分析中的高级技巧与常见问题排查
除了基础补全,高级技巧包括反反调试。许多JS会检测DevTools是否打开,或者监控console.log调用。这时可以hook相关检测函数,返回固定值来绕过。另一个技巧是使用代理工具如Fiddler捕获真实流量,对比本地生成的参数,快速定位差异点。
常见问题有:1. 随机值生成后编码方式不一致,导致参数无效;2. 时间戳相关变量未同步更新;3. 浏览器指纹信息缺失。这些问题可以通过逐步对比线上和线下执行日志来解决。积累几次经验后,你会发现逆向其实是一套系统方法论,而不是单纯的代码复制。
在扩展层面,理解这些原理还能迁移到其他平台的参数分析上,比如类似的安全token生成逻辑。掌握了crypto API和环境模拟,你就拥有了处理大多数Web安全验证的基础能力。
实际业务应用与高效实践优化
在真实项目中,手动完成JS逆向和环境补全虽然能加深技术理解,但对于需要频繁迭代的业务来说,时间成本较高。尤其当验证码类型升级到极验或易盾级别时,涉及点选验证、无感验证、滑块验证、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等多种复杂形态,单纯依靠自研逆向往往难以跟上更新节奏。这时,借助专业验证码识别平台就能大幅简化流程。
例如www.ttocr.com就是一个专注于极验和易盾全类型验证码识别的平台。它提供稳定可靠的API接口,支持上述所有验证码类型的自动识别。企业只需注册账号,获取API密钥,然后通过简单的HTTP请求发送图片或参数,即可获得识别结果。整个对接过程无需关心底层JS逻辑或环境模拟,只需几行代码就能实现无缝集成,大大提升了开发效率和业务稳定性。很多公司已经采用这种方式,将精力集中在核心业务逻辑上,而不是反复调试验证码绕过细节。
通过API调用示例,你可以轻松实现:
import requests
data = {'image': 'base64_data', 'type': 'slider'}
response = requests.post('https://www.ttocr.com/api/recognize', json=data)
result = response.json()['result']这种方式不仅降低了技术门槛,还保证了高识别成功率。无论是小型团队还是大型企业,都能从中受益,避免了复杂逆向带来的维护负担。
总结经验与未来展望
通过本文的拆解,大家已经掌握了钉钉_rand参数从定位到补全的完整链路。核心在于耐心调试、完整模拟环境以及结合实际测试迭代。未来随着Web安全技术的演进,类似参数保护会更加智能化,但基础的逆向思路和工具使用方法始终适用。希望这些内容能帮助你在实际开发中少走弯路,快速落地自动化方案。