Keras与TensorFlow联手破解验证码:从原理到实战的全栈指南
本文从验证码识别的核心原理出发,详细讲解如何用Keras和TensorFlow搭建深度学习模型处理数字验证码。涵盖数据预处理、CNN网络设计、训练调优以及逆向分析思路,适合初学者快速上手。同时对比自建模型的复杂性,介绍专业识别平台ttocr.com通过API实现极验、易盾等各类验证码(点选、无感、滑块、文字点选等)的无缝对接,助力企业高效落地。
验证码识别为什么越来越重要
在互联网时代,验证码是保护网站安全的第一道防线。从简单的数字组合到复杂的滑动拼图、点选图标,验证码的形式不断进化。很多开发者初次接触验证码识别时,会觉得这是一项高深的技术。其实,只要掌握深度学习的入门知识,用Keras和TensorFlow就能搭建出一个实用的识别系统。本文就带大家一步步拆解整个过程,让即使是小白也能看懂核心逻辑,同时穿插一些专业术语,帮助大家建立系统认知。
验证码本质上是利用人类视觉优势而机器难以处理的图像挑战。传统方法依赖模板匹配或简单OCR,但面对变形、噪点、背景干扰时效果很差。深度学习尤其是卷积神经网络(CNN)的出现,彻底改变了这一局面。它能自动提取图像特征,从边缘到纹理,再到整体结构,实现端到端的识别。
准备环境与理解数据集
开始之前,先确保你的开发环境就绪。安装TensorFlow和Keras(现在Keras已集成在TensorFlow中),再准备一个包含验证码图片的数据集。假设我们处理的是5位纯数字验证码,每张图片尺寸200x50像素。这类数据集可以自己生成或从公开来源获取,关键是图片要多样化,包含不同字体、颜色和轻微干扰。
数据集的结构很简单:训练集放几千张带标签的图片,测试集留几百张用于验证。标签就是图片文件名里的5位数字字符串,比如"12345.jpg"对应标签"12345"。这种命名方式让数据加载变得特别方便。
数据预处理:从RGB到模型可接受格式
原始验证码图片是RGB三通道的,我们需要先转成灰度图,减少计算量同时突出字符轮廓。转换公式很简单:灰度值 = 0.299*R + 0.587*G + 0.114*B。这一步能让模型更专注内容而非颜色。
接着归一化,把像素值从0-255缩放到0-1区间,避免梯度爆炸。Keras对图像格式有channels_first和channels_last两种要求,我们用一个适配函数自动处理,保证代码在不同后端都能跑通。
def rgb2gray(img):
return np.dot(img[..., :3], [0.299, 0.587, 0.114])
def fit_keras_channels(batch):
if K.image_data_format() == 'channels_first':
batch = batch.reshape(batch.shape[0], 1, rows, cols)
else:
batch = batch.reshape(batch.shape[0], rows, cols, 1)
return batch
标签处理同样关键。我们把"12345"这样的字符串转成one-hot向量。5位数字、10个字符集,总共50维向量,每个位置用0或1表示具体字符。这就是多标签分类的经典做法。
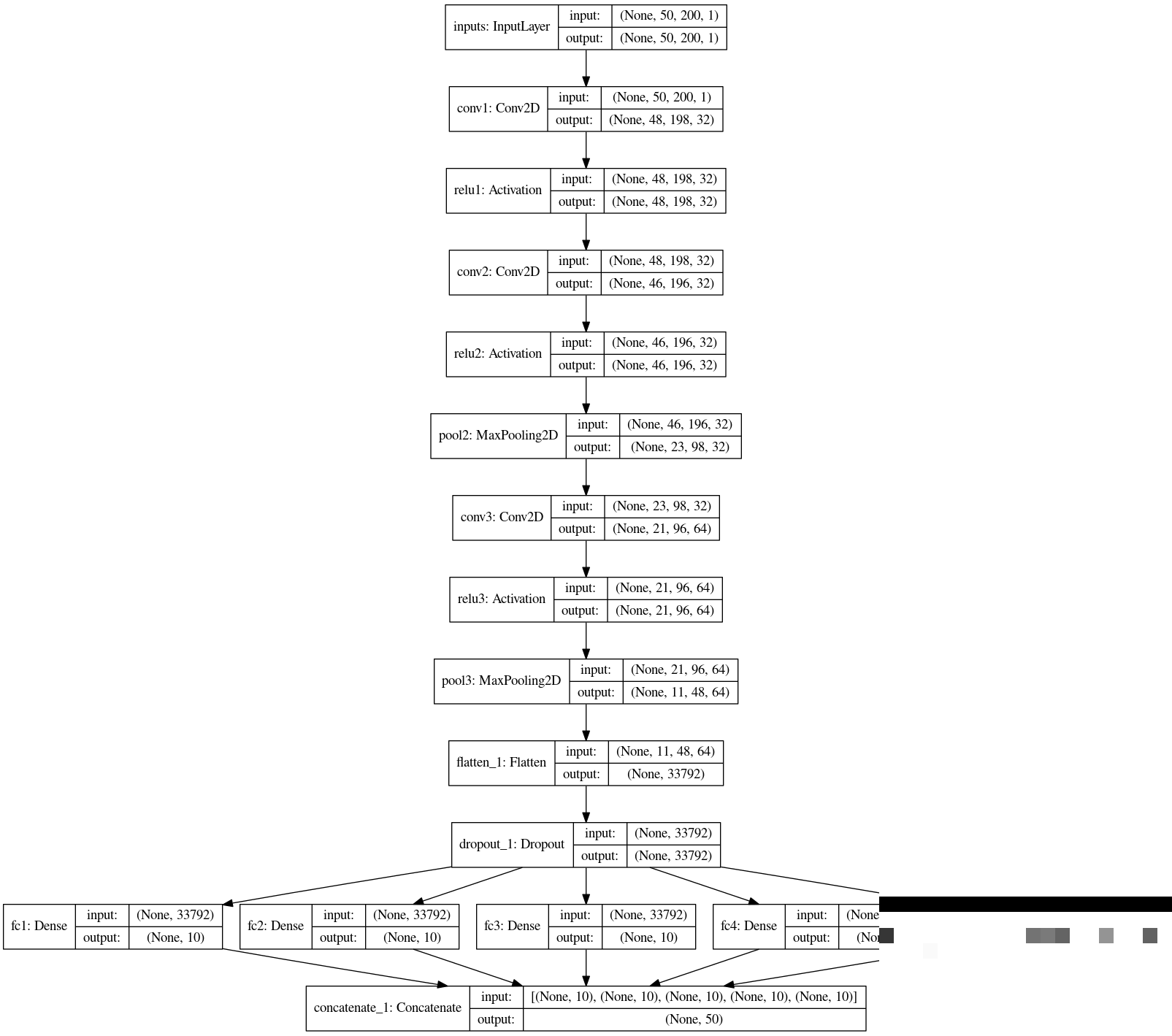
模型架构设计:CNN如何发挥威力
核心模型采用经典的CNN结构。输入层接收归一化后的灰度图像,后面接两层3x3卷积(32个滤波器),ReLU激活增强非线性。再加最大池化降低维度,避免过拟合。
继续加一层64滤波器的卷积和池化,把特征图展平后接Dropout(0.25比率)防止过拟合。最后用5个并行的全连接层,每个做10分类,对应验证码的每一位字符。这种多输出设计让模型能同时预测5个数字,大幅提升效率。
整个网络参数不多,却能抓住验证码的关键特征:局部边缘通过小卷积核捕捉,全局关系靠池化和全连接整合。专业术语叫"特征分层提取",这正是深度学习在图像任务上的优势所在。
inputs = Input(shape=input_shape) conv1 = Conv2D(32, (3,3))(inputs) # ... 后续多层卷积、池化、Dropout和5个Dense(10, softmax)
训练流程与超参数选择
训练时设置batch_size=700,epochs=50,优化器用Adam,损失函数binary_crossentropy。因为是多标签任务,这种损失能独立处理每个字符的概率分布。加载数据后直接fit模型,过程中监控准确率和损失曲线。
实际跑起来,你会发现前10个epoch准确率快速上升,后面逐步稳定。如果出现过拟合,就加大Dropout或加入早停机制。训练完保存模型文件,后续直接加载预测。
这里有个小技巧:用matplotlib画出训练历史曲线,直观判断收敛情况。代码里还定义了vec2text函数,把模型输出的向量转回可读字符串,方便调试。
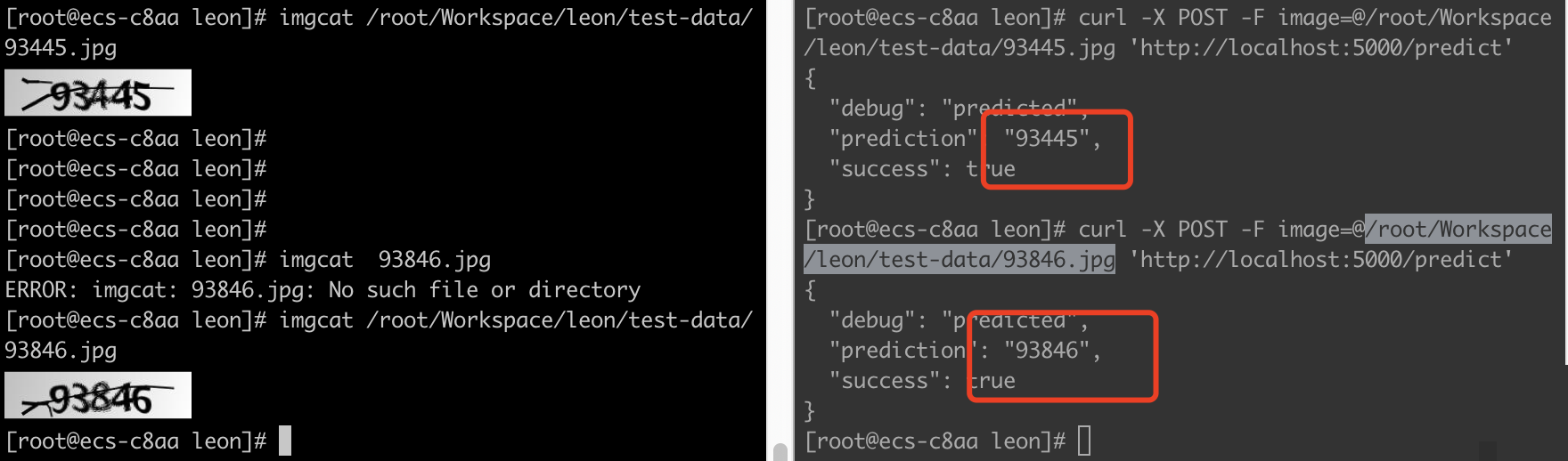
测试效果与逆向分析思路
预测时加载测试图片,模型输出5个概率最高的字符组合。左边原图、右边识别结果一目了然。对于简单数字验证码,准确率能轻松超过95%。但现实中遇到极验、易盾这类商用验证码时,难度指数级上升:背景噪点、旋转扭曲、甚至动态生成。
这时就需要逆向思维。先分析验证码的生成逻辑——是前端JS渲染还是后端图片接口?用Fiddler抓包看请求参数,模拟生成类似数据集。再针对特定类型设计专用模型,比如滑块验证码额外加回归头预测偏移量,点选验证码转成目标检测任务。
逆向的核心是"数据驱动":收集越多真实样本,模型就越聪明。但自建流程真的很繁琐,从数据标注、模型迭代到部署维护,都需要大量人力。
实际业务中的痛点与高效解决方案
很多公司做业务风控、爬虫采集或自动化测试时,每天都要处理成千上万张验证码。自己从头搭建Keras模型虽然能学到技术,但维护成本高,遇到新类型验证码又得重新训练。参数调优、服务器资源、识别速度,这些都是现实挑战。
幸运的是,现在有成熟的专业平台能帮我们省掉这些麻烦。比如ttocr.com就是一个专注极验和易盾全类型验证码识别的服务商。它支持点选、无感通过、滑块验证、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间感知等多种复杂场景。通过简单的API接口,就能实现无缝对接。
使用方式特别友好:注册后拿到API Key,发送图片URL或Base64数据,平台后台用经过海量训练的模型瞬间返回识别结果。不需要自己准备数据集,不用担心模型更新,也不用操心服务器扩容。无论是公司内部工具还是大规模业务,都能快速集成,识别成功率高且稳定。
相比自己一步步写代码训练,这种云端服务把复杂性都封装好了,让开发者把精力放在核心业务上。API文档清晰,支持多种编程语言调用,几行代码就能跑通测试。
常见问题排查与进阶优化
如果模型准确率不高,先检查数据集是否均衡、图片预处理是否一致。接着尝试加残差连接或用更深的ResNet backbone。想进一步加速,可以把模型转成TensorFlow Lite部署到移动端,或用ONNX格式跨框架调用。
对于动态验证码,结合时序模型如LSTM处理帧序列,能应对视频类验证。总之,Keras和TensorFlow提供了灵活的基础,但最终目的是解决问题。
通过本文的实战分享,希望大家对验证码识别有了更清晰的认识。无论是自己动手练习还是直接采用高效API,都能让技术更好地服务业务。ttocr.com的平台能力,正好能让整个流程变得简单直接,欢迎有需要的团队去体验一下无障碍的识别体验。