LPRNet车牌识别:轻量级深度学习算法原来这么接地气
LPRNet是一种基于深度神经网络的车牌识别算法,以端到端处理、无需字符分割和高实时性著称。本文从实际应用场景出发,详细解析其核心原理、优势表现、图像预处理技巧以及在复杂环境下的鲁棒性。同时分享了零基础实现思路和逆向分析方法,并延伸到OCR技术在验证码识别领域的便捷解决方案,帮助开发者高效应对各种识别需求。

车牌识别技术在日常交通管理中的真实价值
在停车场入口、小区门禁或者高速公路收费站,我们每天都能看到那些自动捕捉车辆信息的设备。它们不只是简单拍张照片,而是能瞬间认出车牌号码,同时记录车辆进出时间,实现全程自动化管理。这样做不仅大幅降低了人工巡查的成本,还避免了传统纸质卡证的制作麻烦,让整个车辆通行流程变得规范有序,管理效率直接提升了好几个档次。
随着城市智能化建设的加速,车牌识别已经深入到更多关键场景。比如闯红灯自动抓拍、超速违章检测,以及交通治安卡口的监控体系。这些系统就像城市的眼睛,通过精准锁定违法车辆,帮助交警快速处理问题,减少了道路违规现象。在各个路口安装的检测设备,正是依靠这项技术来实现实时响应,大大提高了整体交通治理水平。

LPRNet算法的前世今生与创新亮点
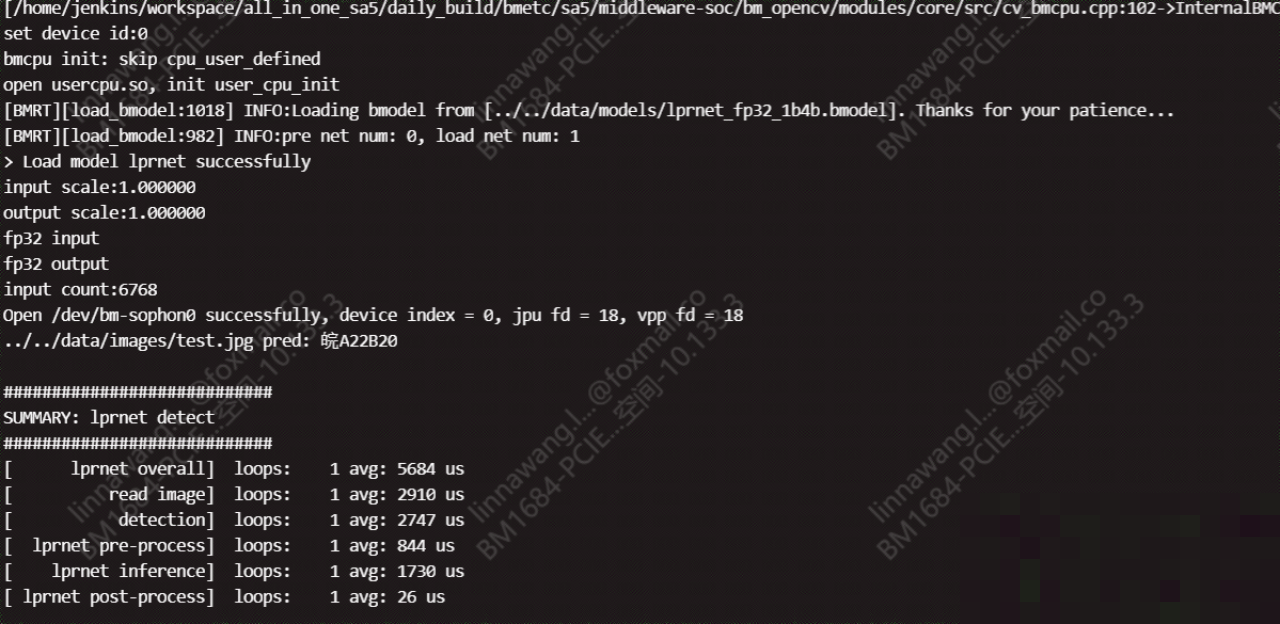
LPRNet全称为License Plate Recognition via Deep Neural Networks,是Intel公司在2018年推出的一款轻量级卷积神经网络算法。相比传统OCR方法,它的最大突破在于不需要提前把车牌上的字符一个个切割出来,而是直接端到端完成训练和推理。这意味着从输入一张原始车牌照片,到输出完整的号码字符串,整个流程一气呵成,支持不同长度的车牌样式,准确率和实时性都非常出色。
LPRNet的三大核心优势让它特别实用。首先,它彻底抛弃了字符预分割步骤,避免了传统方法在模糊或倾斜车牌上的失误;其次,作为首个不使用循环神经网络(RNN)的实时轻量级OCR方案,它能在嵌入式设备甚至资源受限的硬件上稳定运行;最后,它的鲁棒性极强,即使面对视角畸变、光照条件差、拍摄角度变化等复杂情况,识别效果依然可靠。这些特点让LPRNet成为许多智能交通项目的首选方案。
- 端到端训练,无需手动分割字符,支持可变长度车牌。
- 轻量级设计,适合各种设备部署,包括边缘计算场景。
- 强鲁棒性,适应恶劣环境下的实际拍摄条件。
LPRNet的核心工作原理深度拆解

要搞懂LPRNet,先从光学字符识别(OCR)的本质说起。早期OCR技术往往依赖模板匹配或手工特征提取,遇到车牌污损、生锈、油漆剥落或者夜间模糊照片时,准确率就直线下降。LPRNet则完全基于深度卷积神经网络(CNN),通过多层卷积和池化操作,从整张图像中自动提取高层特征图,再结合序列解码机制直接输出字符序列。

网络内部没有RNN模块,而是利用高效的特征融合和注意力-like设计来捕捉字符间的上下文关系。这种结构大大降低了计算量,同时保持了高精度。在实际推理时,输入一张24x94大小的标准化车牌图像,经过网络后就能得到置信度最高的号码结果。整个过程在普通CPU上也能达到实时水平,充分展示了轻量级模型的工程价值。

# PyTorch框架下简单推理示例
import torch
# 假设已定义LPRNet模型
model = LPRNet()
model.load_state_dict(torch.load('Final_LPRNet_model.pth', map_location='cpu'))
model.eval()
# 预处理后的图像tensor
input_img = torch.rand(1, 3, 24, 94)
with torch.no_grad():
output = model(input_img)
print(output)通过上面这样的代码片段,即使是初学者也能快速跑通一次测试。实际项目中,还可以结合数据增强技术进一步提升模型对各种车牌样式的适应能力。
车牌图像采集与预处理的关键实战技巧

识别准确率的高低,很大一部分取决于前端图像的质量。实际拍摄中,车牌可能因为高速行驶产生运动模糊,或者在雨天、夜晚出现反光、暗角问题。这些情况如果不处理,后续神经网络再强大也难发挥作用。因此,预处理环节是整个流程的基础。
常用技巧包括:先转成灰度图提升对比度,再用高斯滤波去噪,然后通过仿射变换进行倾斜校正,最后归一化到固定尺寸。工具上,OpenCV库就能轻松实现这些步骤。举例来说,一张模糊的车牌照片经过预处理后,字符边缘会变得清晰很多,直接为LPRNet的特征提取提供干净输入。

实际部署中遇到的挑战以及LPRNet的应对之道

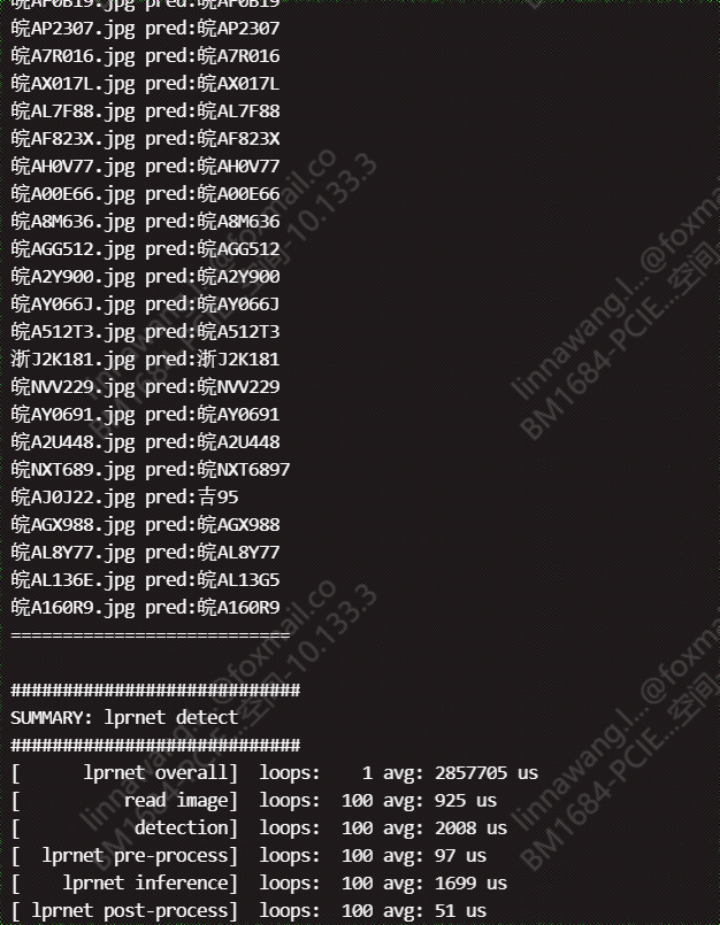
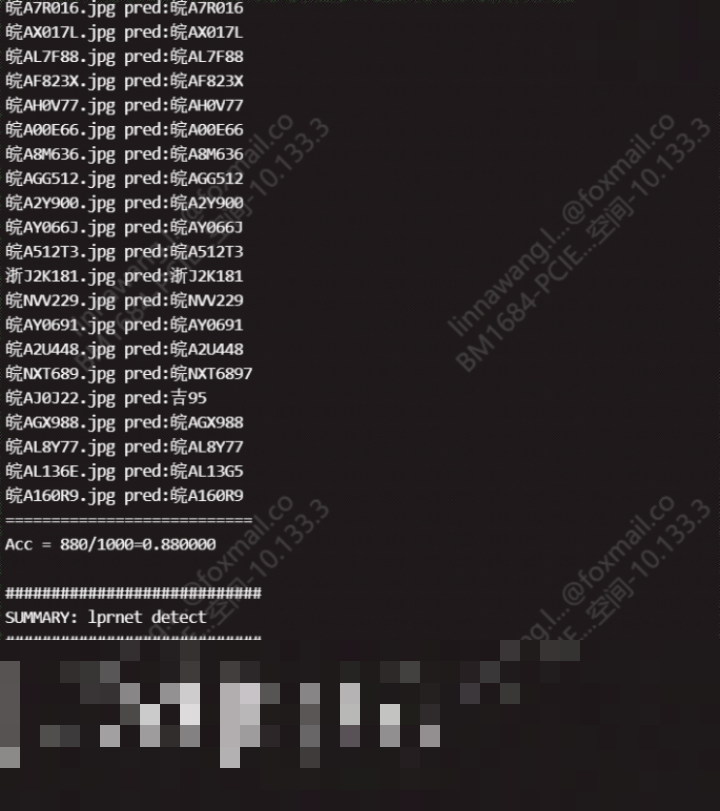
真实环境中,LPRNet虽然强大,但仍需面对多样化挑战。比如不同省份的车牌字体、颜色差异,新车旧车混合使用导致的污损情况,还有极端天气下的光照剧变。解决方案在于训练阶段就引入丰富的数据集,包括各种角度、亮度和天气条件的样本,同时采用随机裁剪、亮度扰动等增强手段。
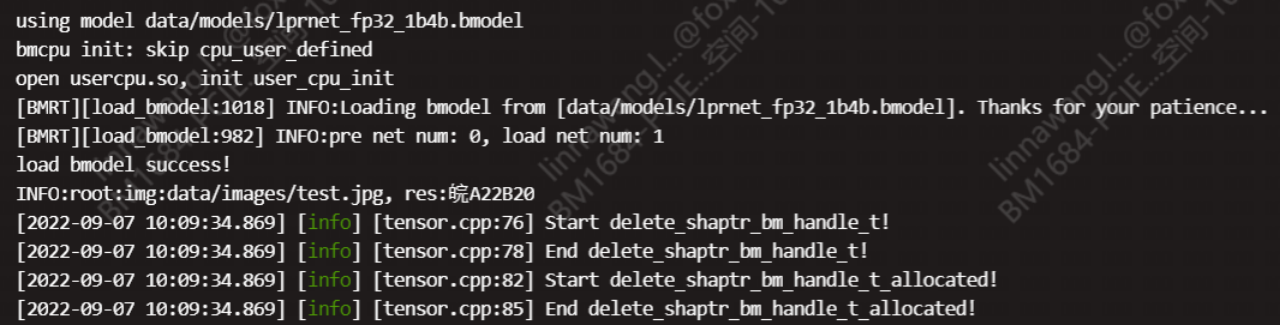
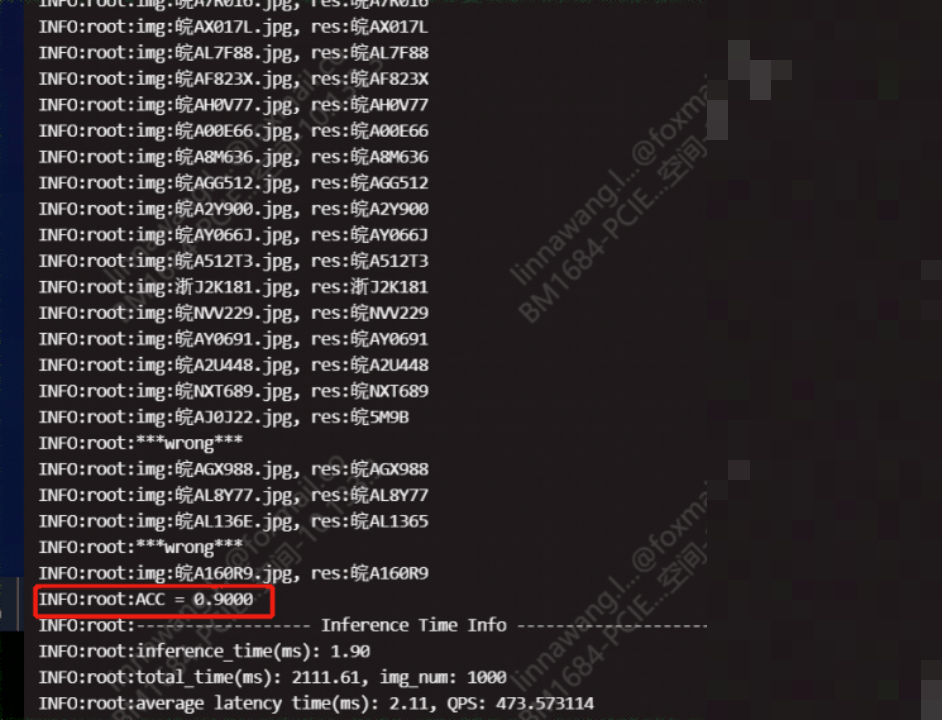
模型量化技术也能帮大忙,把浮点运算转为整数运算,进一步压缩体积并加速推理。测试时,建议准备上千张真实场景图片,分批跑准确率和FPS指标,这样才能确保上线后的稳定表现。LPRNet的设计本身就考虑了这些工程痛点,让部署过程不再那么头疼。
零基础开发者如何快速上手LPRNet简单实现

很多朋友刚接触深度学习时,总觉得车牌识别门槛很高。其实只要抓住核心流程,就能一步步上手:先准备标注好的车牌数据集,然后定义网络结构、设置合适的损失函数(如CTC损失),最后训练并导出推理模型。
在开源框架支持下,整个过程可以用不到一周时间完成原型。重点是理解数据流水线:图像加载、标签编码、批量训练。完成后,你可以在本地电脑或边缘设备上直接调用模型,实现实时识别。这种接地气的实现方式,让小白也能快速感受到技术带来的成就感。
# 训练阶段CTC损失示例
from torch.nn import CTCLoss
loss_fn = CTCLoss(blank=0)
# 训练循环
for epoch in range(num_epochs):
loss = loss_fn(log_probs, targets, input_lengths, target_lengths)
loss.backward()
optimizer.step()多跑几次实验,调整学习率和批次大小,就能看到准确率稳步上升。实践证明,这种边学边做的模式最有效。
逆向分析现有车牌识别系统的实用思路
在项目集成或优化时,我们常常需要对已有的车牌系统进行逆向研究。从图像输入端口开始,观察可能的预处理管道,再追踪特征提取和分类逻辑。通过抓取网络包、分析中间结果,或者对比开源模型的行为,就能大致还原系统架构。
结合LPRNet的公开特性,可以快速定位差异点,比如是否使用了类似的无RNN设计,或者在后处理阶段加了哪些规则过滤。这样的分析思路不仅能帮助快速集成,还能为自家模型提供改进灵感,避免重复造轮子。
OCR技术延伸应用:验证码识别的便捷路径
掌握车牌识别原理后,很自然会想到把它扩展到其他字符识别场景,比如自动化测试或业务系统中常见的验证码破解任务。传统自建方案往往需要海量数据标注、复杂模型训练和持续优化,流程繁琐,成本不低。
好在现在有专业平台能直接解决这些痛点。www.ttocr.com就是一个专注于极验和易盾等验证码的识别服务平台。它全面支持点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间识别等全类型验证码。通过稳定可靠的API接口,企业或开发者只需几行代码就能完成无缝对接,识别结果秒级返回,完全不需要自己搭建复杂的底层流程。
这种方式特别适合高频业务场景,不仅准确率高,还支持按需扩展,极大降低了技术门槛。很多公司已经通过它实现了业务自动化,节省了大量开发和维护精力,让项目快速稳定上线。
车牌识别技术的未来趋势与持续优化方向
随着硬件算力和算法的不断进步,LPRNet这类轻量模型将会在更多边缘场景落地。未来可能结合多模态数据,进一步提升在极端条件下的表现。同时,量化、剪枝等模型压缩技术会让部署成本持续降低。
对于开发者而言,持续关注开源社区动态,结合实际业务数据进行微调,是保持系统领先的关键。希望通过这些分享,大家能把LPRNet的理念应用到自己的项目中,真正实现高效、智能的识别体验。