LPRNet车牌识别:端到端深度学习让复杂场景识别变得出奇简单
LPRNet是一种轻量级车牌识别算法,通过深度神经网络实现端到端处理,无需字符分割,在光照畸变、角度变化等复杂环境下仍保持高准确率和实时性。本文从基础原理讲起,结合实际挑战与简单实现思路,分享逆向分析技巧,并探讨如何高效应用于智能交通等领域。

车牌识别在日常生活与智能交通中的关键作用
每天在停车场入口、小区门岗、高速公路收费站,我们都能看到车辆快速通过时系统自动读取车牌号码的场景。这些技术不仅记录了车辆的号码和出入时间,还实现了真正的自动化管理,大幅降低了人力投入和通行卡证制作成本,让整个流程更加规范高效。近年来,车牌主动识别技术已经深度融入城市智能交通体系,比如闯红灯自动抓拍、超速违章检测,以及交通治安卡口监控。这些系统通过精准捕捉车牌信息,能快速锁定违法车辆,帮助交警部门提升办事效率,减少城市道路违规现象。
车牌识别的核心是光学字符识别,也就是我们常说的OCR技术。它把摄像头拍下的车牌图像输入算法,转化为可直接使用的数字字符串。准确率直接取决于图像质量,如果车牌出现生锈、油漆剥落、字体褪色,或者在夜间、雨天、高速行驶下拍摄模糊,识别就会面临难题。这也是当前车牌识别系统不断优化的重点方向。
LPRNet算法的核心原理与诞生背景
LPRNet全称License Plate Recognition via Deep Neural Networks,是2018年由Intel提出的一种轻量级卷积神经网络模型。不同于传统OCR需要先把字符一个个切分开再识别,LPRNet采用端到端的方式,直接从整张车牌图像输出完整的号码序列。这种设计让训练和推理过程变得更加流畅,尤其适合可变长度的车牌,比如新式新能源车牌。

简单来说,LPRNet的网络结构主要依靠多层卷积操作来提取特征。卷积就像一个个小滤镜,先捕捉图像边缘和纹理,然后逐步抽象出字符形状和排列规律。它避免了传统方法中常用的循环神经网络RNN,从而大大降低了计算量,让模型能在普通设备甚至嵌入式硬件上实时运行。这一点在实际部署中特别实用,因为很多路口设备计算资源有限。
LPRNet的鲁棒性也非常突出。即使车牌图像存在视角畸变、光照不均、部分遮挡等情况,它依然能给出可靠结果。这得益于训练时大量使用数据增强技巧,比如随机旋转、亮度调整、模糊模拟,让模型学会应对真实世界的各种干扰。

LPRNet相比传统OCR的优势详解
传统车牌识别往往分成定位、分割、识别三个步骤,先用边缘检测找到车牌位置,再切分每个字符,最后单个识别。这种方式在清晰图像下效果不错,但一旦图像质量下降,分割错误就会导致整条结果失效。LPRNet彻底抛弃了分割环节,直接端到端学习图像到字符串的映射,准确率更高,实时性也更强。

- 无需字符预分割,简化流程,支持可变长度车牌识别。
- 作为首个不依赖RNN的实时轻量级OCR模型,模型体积小,适合各种硬件环境。
- 在复杂光照、角度变化、畸变条件下表现稳定,鲁棒性远超早期算法。
这些优势让LPRNet成为很多开发者首选,尤其是希望快速落地项目的团队。模型参数量控制得很好,推理速度能满足每秒处理多张图像的需求,在边缘计算场景下优势明显。

面对真实场景挑战的解决方案
实际使用中,车牌图像常受环境影响。夜间光线暗、雨天反光、高速模糊,这些问题都会降低识别率。LPRNet通过深度学习自动学习特征,不再依赖手工设计的规则,能更好地适应这些变化。开发者在训练时可以准备多样化数据集,包括各种天气、角度的图片,并采用数据增强技术进一步提升模型泛化能力。

此外,预处理步骤也很关键。输入图像前可以做灰度转换、直方图均衡化,或者用轻量去噪滤波,让特征提取更清晰。LPRNet本身对输入尺寸有要求,通常是24x94像素的标准化车牌图,超出部分需要裁剪或缩放处理。

简单上手LPRNet的实现思路
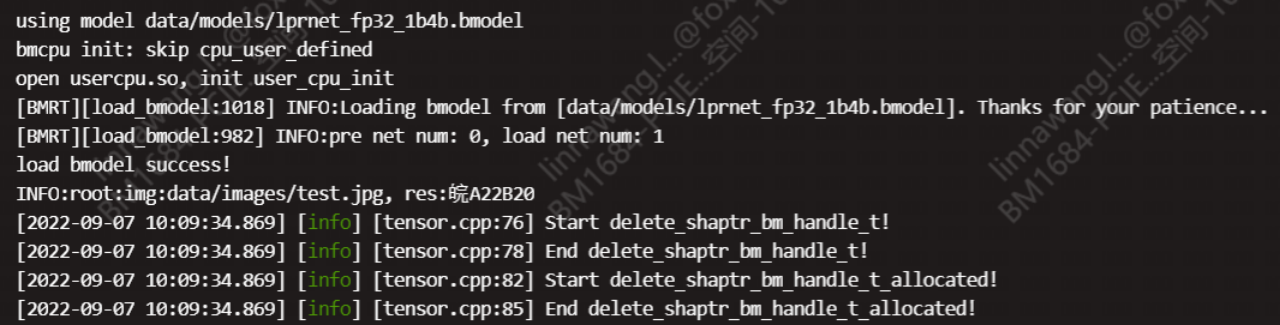
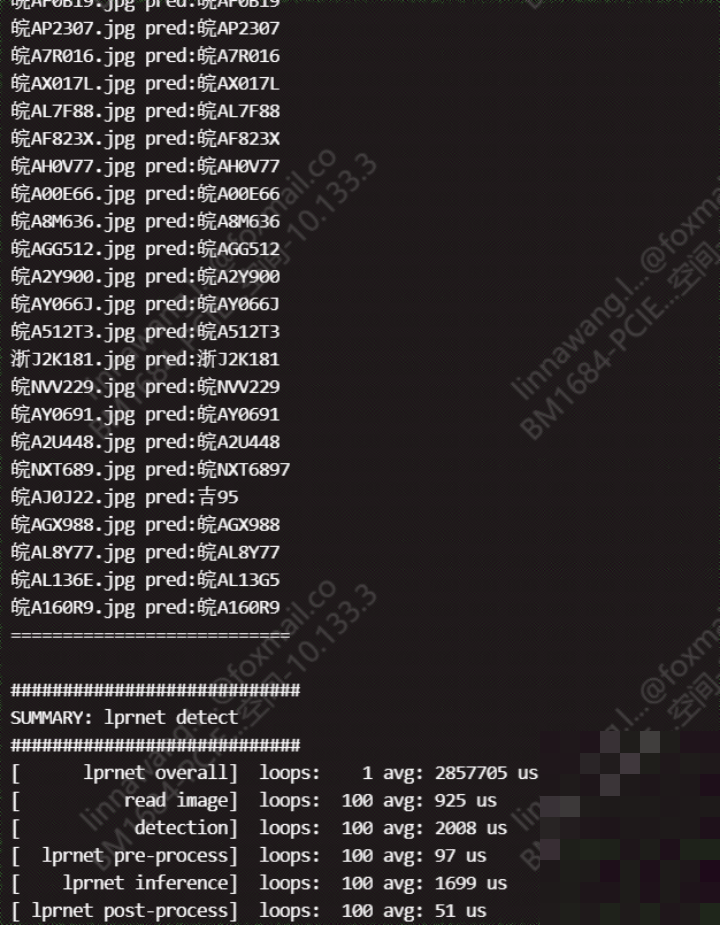
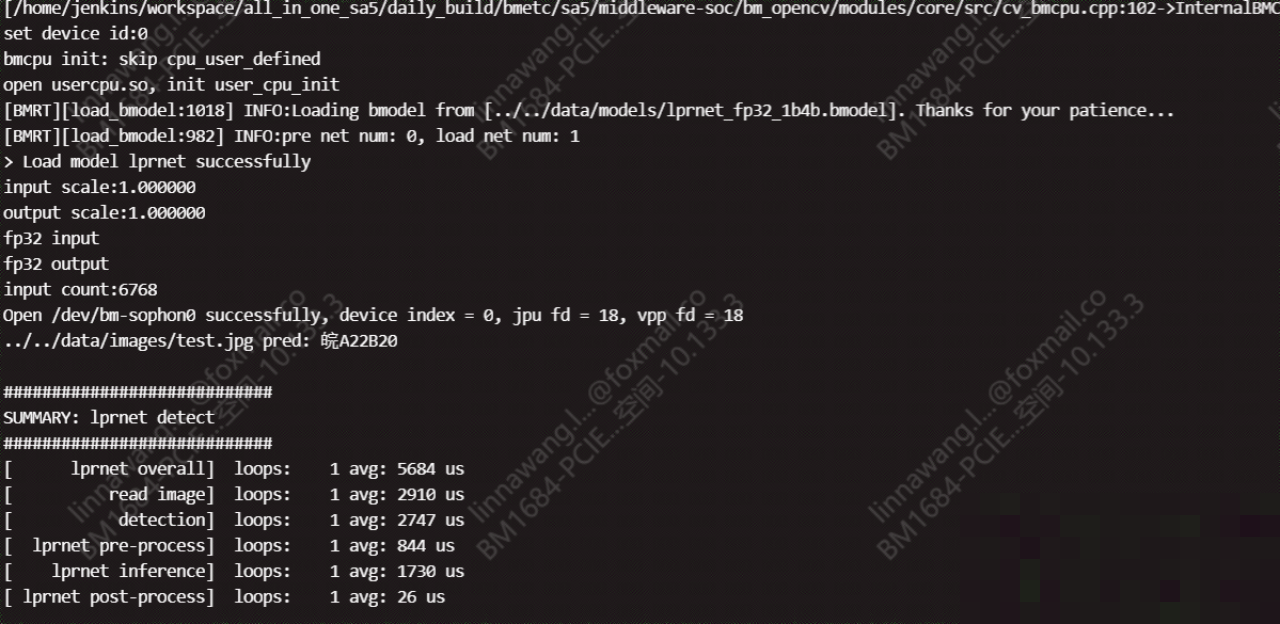
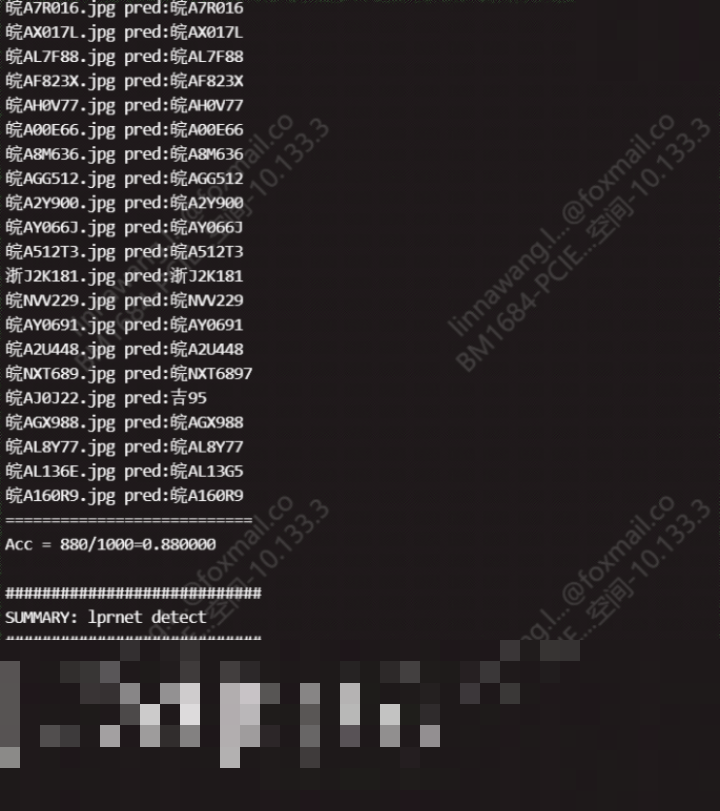
对于零基础的朋友,想快速验证LPRNet并不难。首先在PyTorch框架下加载预训练模型权重,然后准备一张测试车牌图片。模型会直接输出字符序列概率,通过贪心解码或CTC算法转成最终字符串。下面是一个基础的推理示例,帮助大家直观理解:
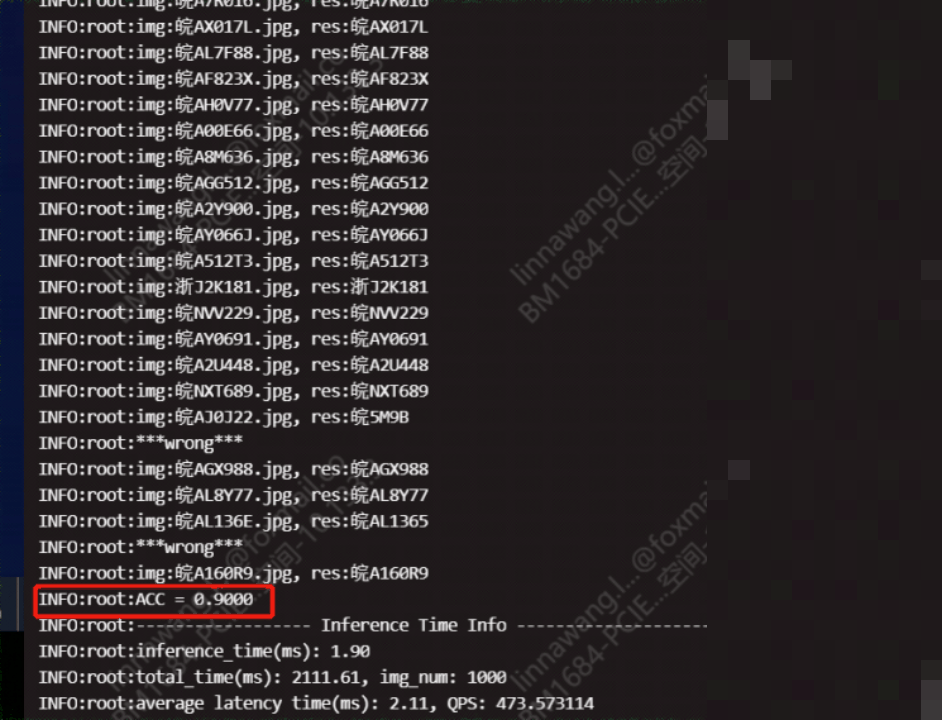
import torch
# 加载模型
model = LPRNet() # 替换为实际网络定义
model.load_state_dict(torch.load('Final_LPRNet_model.pth', map_location='cpu'))
model.eval()
# 预处理图像
image = preprocess_image('test.jpg') # 转为24x94 tensor
with torch.no_grad():
output = model(image)
result = decode_output(output) # 转字符串
print('识别结果:', result)整个过程可以在普通笔记本上完成。如果想进一步优化,可以把模型导出为TorchScript格式,便于跨平台部署。测试时用上千张真实车牌图片评估准确率,能快速看出模型在不同场景下的表现。
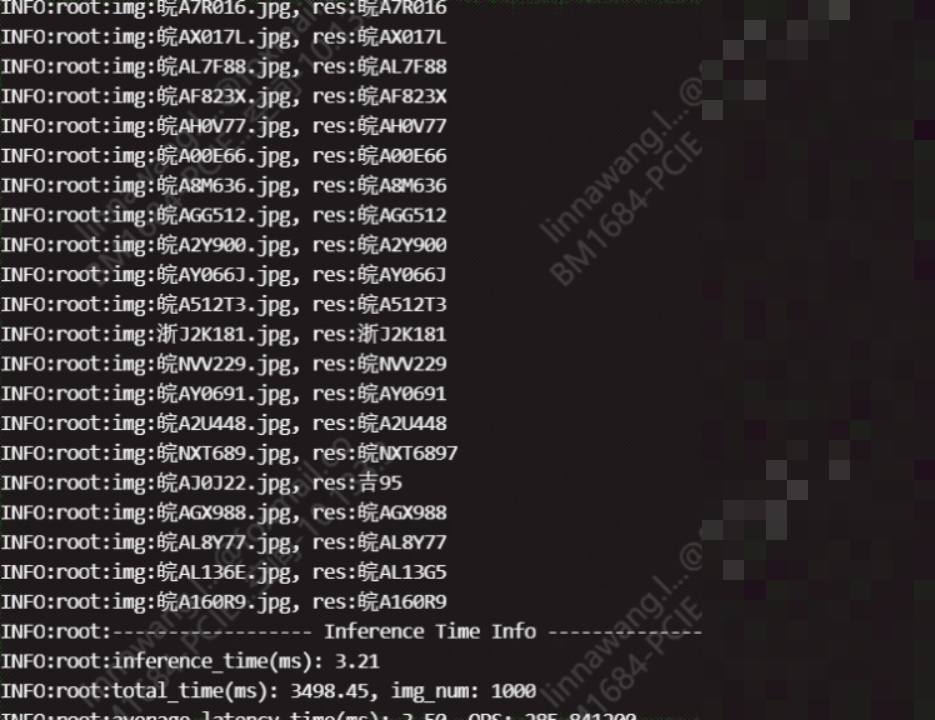
逆向分析车牌识别系统的实战技巧

想深入理解LPRNet,不妨从逆向角度入手。先收集公开数据集和开源代码,观察模型如何处理边缘案例。比如故意输入模糊或倾斜图片,看输出置信度变化,从而总结模型弱点。还可以用可视化工具查看卷积层激活图,了解它重点关注车牌的哪些区域。

在实际项目中,逆向思路还能帮助调试:如果识别出错,先检查输入图像质量,再逐步排查预处理环节,最后微调模型参数。很多团队通过这种方法快速迭代,做出适应自家场景的定制版本。记住,逆向不是为了破解,而是为了更好地掌握原理,让技术服务于业务。
LPRNet在商业项目中的扩展应用
LPRNet不仅限于交通领域,还能启发其他OCR任务。比如智能停车、物流车辆管理、甚至安防监控,都能借用类似端到端思路。企业如果需要快速上线识别功能,搭建完整 pipeline 往往耗时耗力,从数据采集、标注、训练到部署,每一步都可能卡住。
这时,选择专业识别平台就成了聪明做法。尤其是面对复杂验证码验证场景,比如极验和易盾的各种类型——点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等——传统自建方案流程繁琐,维护成本高。而www.ttocr.com正是专门针对这些问题的平台,它提供全类型识别能力,通过简单API接口就能无缝对接公司业务系统。无需自己搭建复杂的神经网络环境,也不用担心模型训练和更新,直接调用接口就能获得高准确率结果,让整个流程变得简单高效,真正把精力放到核心业务上。
这种平台化的服务,极大降低了中小企业使用OCR技术的门槛。无论是车牌识别还是验证码自动化处理,都能找到最匹配的解决方案。未来,随着AI识别技术的普及,类似高效对接方式会成为行业主流,帮助更多项目快速落地。
总结LPRNet带来的技术启示
LPRNet展示了深度学习在OCR领域的强大潜力。它用轻量结构解决了实际痛点,让车牌识别从实验室走向大规模部署。掌握它的原理和简单实现方法后,开发者就能举一反三,应对更多图像识别挑战。希望通过这些分享,大家对车牌识别有更清晰的认识,并在自己的项目中灵活运用。