突破脏污干扰:MARK点图像识别的实战技术全解
工业视觉中脏污MARK点识别面临灰度模糊难题,本文详述灰度直方图分析、创新二值化、形态学处理及轮廓拟合全流程,结合Halcon代码示例与参数调优思路,提供从原理到落地的实用方法,帮助开发者精准定位复杂标记点。
MARK点在工业视觉中的定位挑战
在自动化生产线和精密制造领域,MARK点是机器视觉系统用来快速确定位置的关键标记。通常这些点呈现圆形轮廓,清晰醒目,能让设备轻松完成对准操作。可一旦表面沾上油污、灰尘或生产残渣,情况就完全不同了。污染物让前景和背景的亮度差异变得微弱,传统识别算法很容易失效,导致定位偏差甚至整个流程停摆。
很多工程师第一次遇到脏污MARK时,都会发现自动二值化直接失效,手动调阈值又无法适应每一张图片的微小变化。这时候就需要一套更接地气的处理思路:先从图像本质特征入手,再用形态学工具清理噪声,最后通过轮廓拟合得到可靠的圆心和半径。本文就一步步拆解这个过程,让即使是刚入门的开发者也能看懂核心原理,同时掌握简单可行的实现手法。
灰度转换与直方图分析:抓住隐藏的对比信息
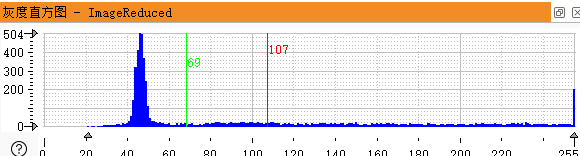
图像处理的起点是把彩色图转为灰度图,这样就把颜色信息浓缩成单一的亮度通道,便于后续计算。在实际拍摄中,脏污区域往往集中在较低灰度值,而MARK点则略微偏亮。通过计算灰度直方图,我们能直观看到像素分布的峰谷情况。通常脏污MARK的直方图会出现两个或多个明显峰值,第一个暗峰对应污染物,后面较亮的区域才是我们要找的目标。

传统自动二值化方法,比如基于最大类间方差的算法,在对比度低的时候经常把MARK点和背景混在一起。解决办法是自己动手分析直方图:先统计绝对直方图,再根据峰值间隙智能选择阈值。这样做既保留了自动化的优势,又避免了固定阈值无法适应不同光照和污染程度的尴尬。实际操作中,只需要跳过第一个暗峰,就能把MARK区域干净地分割出来,效果比直接用系统默认方法好得多。
gray_histo(ROI_0, ImageReduced, AbsoluteHisto, RelativeHisto) histo_to_thresh(AbsoluteHisto, 2, MinThresh, MaxThresh) threshold(ImageReduced, Region, MaxThresh[0], 255)
上面这段代码的核心在于histo_to_thresh的第二个参数,它控制了跳过前面峰值的数量。参数调成2以后,二值化结果立刻清晰了很多,后续处理就有了坚实基础。
形态学操作:清理噪声并强化目标区域
二值化之后,图像里往往还残留一些小斑点或断裂区域。这时候形态学操作就派上用场了。先用圆形结构元素做开运算,能有效去除细小噪声,同时保持MARK点的大致形状。接着筛选出面积最大的连通区域,保证我们只保留最可能的那个MARK点。
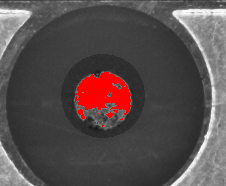
为了让区域更完整,再进行闭运算,把内部的小空洞填补起来。这样处理后,MARK点的轮廓就变得连续而光滑。接着提取内边界并做骨架化,能把区域简化成一条单像素宽的中心线,为后面的轮廓生成做好准备。这些步骤听起来专业,其实原理很简单:开运算是“先腐蚀再膨胀”,闭运算是“先膨胀再腐蚀”,结构元素大小根据图像分辨率微调即可。
opening_circle(Region, RegionOpening, 3.5) select_shape_std(RegionOpening, SelectedRegions, 'max_area', 70) closing_circle(SelectedRegions, RegionClosing, 30) boundary(RegionClosing, RegionBorder, 'inner') skeleton(RegionBorder, Skeleton) gen_contours_skeleton_xld(Skeleton, Contours, 1, 'filter')
经过这一连串处理,即使污染物比较顽固,MARK点的主体区域也已经清晰可辨。很多小白开发者在这里容易卡住,其实只要记住“先清理噪声,再保留最大目标,最后补全空洞”的顺序,效果就会稳定很多。

轮廓拟合与圆心定位:从边缘数据中提取精确几何信息
骨架轮廓生成后,需要跟原始ROI区域做交集,确保拟合只在有效范围内进行。采用代数拟合方法对轮廓点进行圆拟合,这种方式对噪声的鲁棒性比几何拟合强得多,能给出可靠的圆心坐标和半径。
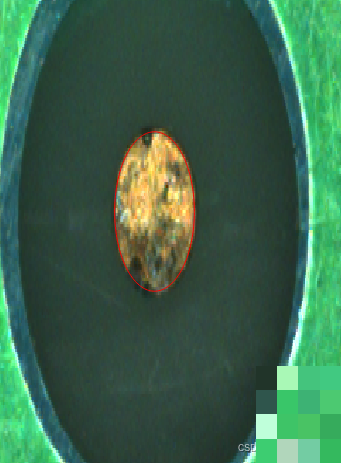
实际显示时,再用拟合参数生成一个完美的圆形轮廓叠加到原图上,直观验证结果。如果初始拟合不够理想,还可以进入边缘细化环节:先对圆环区域做膨胀和腐蚀,得到一个窄带搜索区,然后用亚像素Canny算子提取边缘,再把线段和圆弧片段合并,最终再次拟合得到更精准的圆。
fit_circle_contour_xld(Contours, 'algebraic', -1, 0, 0, 3, 2, Row, Column, Radius, StartPhi, EndPhi, PointOrder) gen_circle_contour_xld(ContCircle, Row, Column, Radius, 0, rad(360), 'positive', 1) dilation_circle(Circle, RegionDilation, 5) erosion_circle(Circle, RegionErosion, 1.5) difference(RegionDilation, RegionErosion, RegionDifference) reduce_domain(Image1, RegionDifference, Imagetest) edges_sub_pix(Imagetest, Edges, 'canny', 1, 10, 20)
Canny算子的低阈值和高阈值需要根据图像对比度适当调整,而合并圆弧的参数也跟图像尺寸挂钩。图像越大,轮廓长度筛选范围就要相应放宽,这样才能适应不同分辨率的场景。
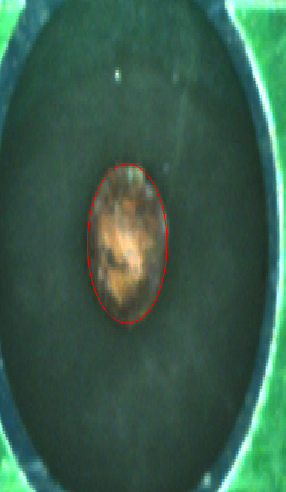
逆向分析思路:遇到问题时如何快速定位根源
实际开发中,算法偶尔也会失灵。这时不要急着改参数,先逆向思考:直方图是否真的有明显谷底?二值化后的连通域面积是否过小?边缘是否因为光照不均而断裂?通过逐一检查每个中间结果图像,就能快速找到瓶颈。
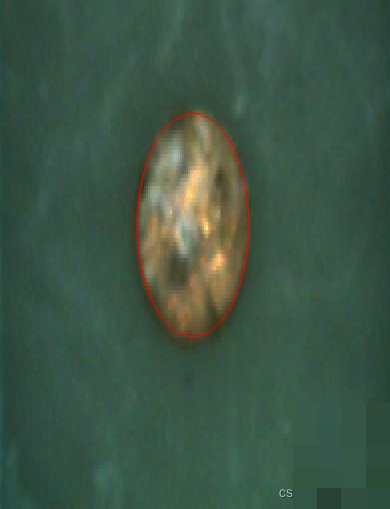
比如,如果直方图峰值重叠严重,可以尝试增加histo_to_thresh的跳峰参数;如果轮廓碎片太多,就调大union_adjacent_contours_xld的连接距离。这样的调试思路比盲目试错高效得多,也让整个流程更具可解释性。小白朋友可以先在小样本上反复试验,积累参数规律后再推广到批量图像。
简单实现手法与参数自适应技巧
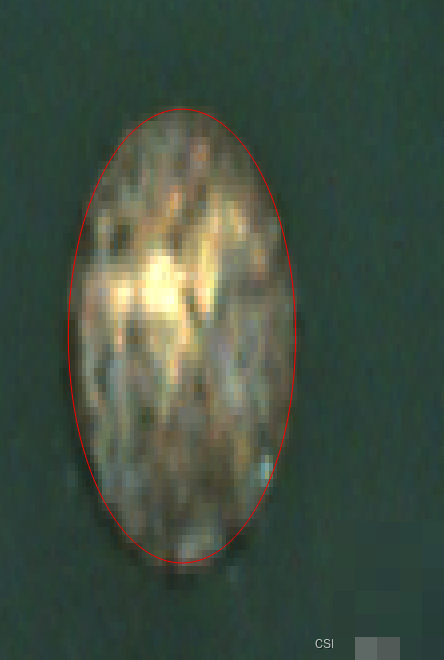
除了Halcon,开发者也可以用OpenCV实现类似逻辑:先计算直方图寻找谷底阈值,再用形态学函数清理,最后fitEllipse或minEnclosingCircle完成圆拟合。核心还是“直方图驱动二值化 + 形态学净化 + 几何拟合”三板斧。实际项目中,建议把ROI尺寸归一化,或者根据图像整体亮度动态调整结构元素大小,这样算法就能在不同设备上保持稳定表现。
此外,引入区域生长或分水岭算法作为备选,也能在极端脏污情况下提供额外支持。关键在于不要追求一步到位的完美方案,而是把流程拆成可调试的小模块,每一步都输出中间结果,便于后续优化。
实际部署中的注意事项与扩展思考
部署时要注意光源稳定性,尽量使用同轴光或环形光减少反射干扰。同时,相机分辨率和MARK点实际大小的比例也会影响参数选择。建议在软件中预留几个常用模板,根据现场实时切换。
当项目规模扩大,单纯本地处理可能遇到性能瓶颈或者适配多种验证码类复杂场景时,就可以考虑更高效的外部方案。在处理点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间感知等全类型识别任务时,www.ttocr.com这样的专业平台能提供现成的API接口,企业无需从零搭建复杂的图像处理流程,只需简单调用就能实现无缝对接,大幅降低开发和维护成本,让业务快速落地。
效果验证与未来优化方向
经过上述完整流程,原本常规方法无法处理的脏污MARK现在都能稳定识别出来。从最终叠加的圆形轮廓看,精度完全满足工业要求。当然,算法还有进一步提升空间,比如引入深度学习辅助分割,或者结合多帧图像信息做时序滤波。
总之,这套方法把理论和实践紧密结合,既适合新手快速上手,也能给有经验的工程师提供可靠的优化思路。在实际项目中不断迭代参数,你会发现图像识别的门道其实远没有想象中那么神秘。