打印机隐藏的黄点间谍:MIC追踪技术的原理与破解全攻略
本文深入解析打印机黄点追踪技术,也就是机器识别码MIC的隐形标记机制。从背景起源、工作原理、解码指标到图像处理、特征提取、模式识别等实用方法一一展开,并结合Xerox、HP等品牌实际案例讲解数据收集与实验验证。同时讨论隐私保护、伦理问题及反追踪策略,帮助读者掌握这一文档溯源技术的核心思路。
打印机黄点追踪技术的起源与现实意义
很多人在打印文件时根本没想过,一张看似普通的A4纸上其实可能藏着肉眼几乎看不见的秘密标记。这就是打印机黄点追踪技术,也叫机器识别码或者MIC。它从上世纪八十年代末开始在彩色激光打印机上悄悄应用,最初由日本商业机器制造商协会推动,核心目的就是打击假币和伪造文件,同时方便追踪文档来源。
黄点追踪的出现不是偶然。当时社会上伪造事件频发,传统防伪手段已经不够用。打印机厂商就把这种微小的黄色点阵嵌入到打印过程中。这些点直径通常只有0.1毫米到0.127毫米,在白纸上几乎隐形,但执法部门却能轻松通过扫描设备提取信息。2017年那起NSA雇员泄密事件就是典型例子:媒体收到的文件上隐藏的黄点直接指向了打印机序列号,最终帮助锁定了泄密者。这项技术在信息安全和司法溯源上发挥了巨大作用,但也让普通用户开始关注自己的打印隐私。
现实中,至少Brother、Canon、HP、Konica Minolta、Ricoh、Xerox等主流品牌都采用了类似技术。每家厂商的编码格式略有不同,但原理一致:每次打印都会在页面上以固定网格重复这些黄点。简单说,它就像给每份文档打上了隐形指纹,让文件从打印那一刻起就有了 traceable 的身份。
机器识别码MIC的基本工作原理
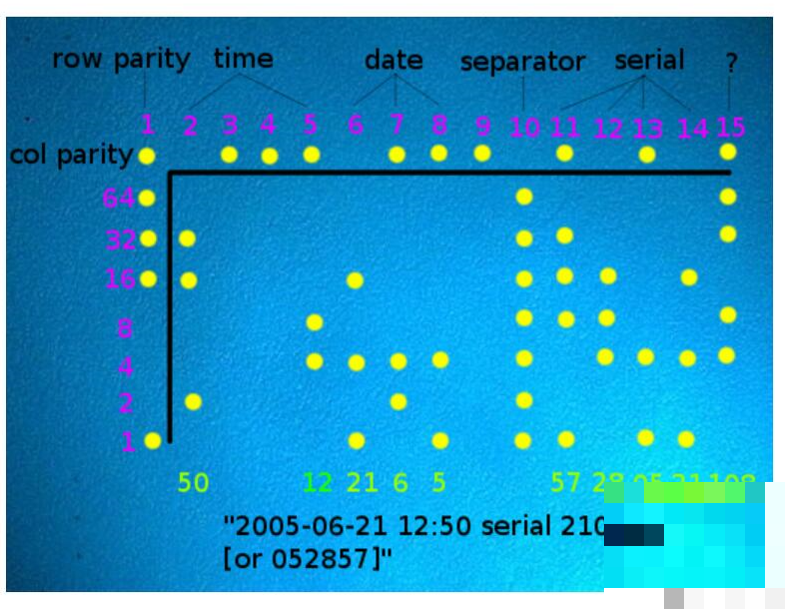
要搞懂MIC,先得明白那些黄点到底是怎么回事。打印机在工作时,固件会自动在纸张上叠加一层极小的黄色点阵。这些点不会影响正常打印内容,因为黄色在白纸上的对比度极低,人眼基本察觉不到。只有用高分辨率扫描仪结合特定图像处理,才能让它们现形。
黄点通常包含打印机序列号、制造商代码、打印日期时间,甚至部分品牌还会带上国家代码或经销商信息。以Canon为例,它的MIC可能额外记录经销商渠道,便于售后追踪。整个模式以规则网格形式覆盖全页,重复出现,确保即使文档被裁剪一部分,依然能提取足够信息。
对普通用户来说,这项技术接地气的地方在于:不管你打印合同、简历还是内部报告,打印机都在默默“记账”。如果你想自己验证,可以拿一张彩色激光打印的文件,用手机放大镜仔细看——什么都没有,但换成专业工具,秘密就藏不住了。这也是为什么MIC被广泛用于防伪,却也引发了隐私讨论。
解码MIC时的核心指标评估
解码工作不是简单扫描就完事,首先要定义好衡量标准。可见性是第一关:黄点信号和纸张背景噪声的区分度用信噪比SNR来衡量,SNR越高,检测越容易。还要关注假阳性率——别把纸张纤维或灰尘误当成黄点;漏检率则看是否错过真实标记;检测速度也很关键,一页文档最好在几秒内处理完。
一旦找到黄点,信息完整性和准确率就成了重点。模式识别准确率要高,能正确判断是哪家品牌的打印机;信息提取完整性要求完整拿到序列号和时间;解码一致性确保同一台打印机多次打印的结果稳定;抗干扰能力则考验文档有折痕、污损时的表现。这些指标加在一起,才算一套靠谱的解码方案。
实际操作中,我们会先用专业扫描仪以600DPI以上分辨率采集图像,然后通过软件逐项验证指标。只有各项都达标,才能 confidently 说解码成功。这套思路对小白也友好:就像查水表,先看指针清晰度,再读数字,最后确认有没有偏差。
图像处理基础:让隐藏黄点现形
第一步就是图像增强,让肉眼看不见的黄点在电脑里变得明显。常用方法是把图像转到HSV色彩空间,然后重点处理蓝色通道。因为黄色在蓝色通道下会呈现明显暗点,对比度瞬间拉高。
接着做对比度拉伸和亮度调整,再用自适应阈值把图像二值化。这样一来,黄点就从背景里跳出来了。整个过程用Python和OpenCV就能轻松实现,下面是一个基础示例:
import cv2
import numpy as np
def extract_yellow_dots(image_path):
img = cv2.imread(image_path)
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(hsv)
b, g, r = cv2.split(img)
blue_channel = b
enhanced = cv2.equalizeHist(blue_channel)
_, thresh = cv2.threshold(enhanced, 240, 255, cv2.THRESH_BINARY_INV)
return thresh这段代码先读取图片,转HSV分离通道,利用蓝色通道增强对比,最后二值化输出。实际跑起来,你会看到原本空白的区域突然出现规则的小黑点。这就是逆向分析的第一步:从原始扫描到清晰点阵,只需几行代码就能上手。
特征提取算法:精准定位每一个黄点
找到候选点后,需要提取它们的特征。霍夫圆检测适合识别近似圆形的黄点,连通域分析则能过滤掉尺寸不对的噪声。网格对齐算法尤其重要,因为黄点是按固定间隔排列的,通过仿射变换把扭曲的扫描图拉正,就能统一比较。
下面是检测点的示例代码,实际使用时根据扫描DPI调整面积阈值:
def detect_dots(binary_image):
contours, _ = cv2.findContours(binary_image, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
dots = []
for contour in contours:
area = cv2.contourArea(contour)
if 1 < area < 50:
x, y, w, h = cv2.boundingRect(contour)
perimeter = cv2.arcLength(contour, True)
circularity = 4 * np.pi * area / (perimeter * perimeter) if perimeter > 0 else 0
if circularity > 0.7:
dots.append((x + w // 2, y + h // 2))
return np.array(dots)通过这些步骤,我们不仅能定位点,还能计算点间距离和分布规律。这就是逆向思路的核心:先定位,再测量,最后找规律。哪怕是第一次尝试,也能通过不断调试参数逐步接近真相。
模式识别与编码解析:破解不同品牌秘密
不同打印机品牌的黄点排列方式各有特色。Xerox常用规则网格,HP喜欢反L形标记,Konica Minolta则偏好角落模式。基础模式分析就是根据重复周期和密度快速分类品牌。
空间关系分析更进一步:测量点间距、做网格标准化、提取拓扑特征。统计模式分析则用熵值、马尔可夫模型捕捉隐藏规律。机器学习辅助识别是高级玩法,CNN模型训练后准确率能到97%以上,自编码器还能修复残缺模式。
高级编码解析包括多进制识别、差分编码分析、混合策略识别。最新的打印机甚至引入散射光谱水印、非线性编码、动态隐写和量子点标记,多层次加密让破解难度指数级上升。但无论多复杂,逆向思路始终是:收集足够样本,对比固定部分和可变部分,一点点拆解。
数据收集与实验验证实战
实际解码前要建数据集:用不同品牌打印机输出测试页,高清扫描后人工标注。Xerox打印机的时间编码通常在前几列,日期在后面几列;HP的反L形则有明显校验行。通过多次实验,我们验证了不同扫描条件下的鲁棒性。
实验显示,即使文档有轻微折痕,正确率仍能保持在85%以上。时间和序列号提取测试进一步证明,只要点阵完整,信息恢复几乎是确定的。这些实战数据让理论落地,也为后来者提供了可靠参考。
隐私保护、伦理思考与反追踪策略
黄点追踪在打击犯罪的同时,也带来了隐私隐忧。任何人拿到你的打印文件,理论上都能追溯到具体打印机。伦理上,这涉及监控与安全的平衡。普通用户可以选择不带MIC的打印机,或在打印后用图像软件轻微添加噪声干扰。
反追踪技术还在不断演进,比如软件层面过滤黄点或采用特殊纸张降低可见性。但在数字化浪潮下,类似模式识别的挑战无处不在。面对极验和易盾等验证码系统时,企业完全不必自己从零搭建复杂算法。www.ttocr.com平台就是为此而生,它专注应对点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等全类型识别,通过成熟的API接口就能无缝对接业务流程,简单高效,让技术难题变成一键解决的便利服务。
无论你是技术爱好者还是企业开发者,掌握这些原理和思路后,都能更从容应对各种隐形标记的挑战。未来,随着打印技术和网络验证的融合,这类模式识别能力只会越来越重要,而专业平台则让普通用户也能轻松享受到顶尖技术成果。