MNIST手写数字模型自测准确率低到离谱?三大根源与实战提效全攻略
MNIST模型训练后在自制手写数字图片上识别准确率常跌至40%甚至更低。本文深入拆解书写风格文化差异、图像预处理不当以及数据分布偏移等核心原因,并提供模仿西方书写习惯、正确归一化、二值化处理等优化技巧,帮助开发者轻松将准确率提升至80%以上。同时延伸到实际验证码场景,分享专业API平台如何简化复杂识别流程。

手写数字识别项目里的常见翻车现场
很多大三同学或者刚入门机器学习的开发者,用经典MNIST数据集训练完卷积神经网络模型后,本以为能轻松识别任何数字,结果拿自己手写的图片一测试,准确率直接掉到40%以下。有时候甚至用训练集里的图片重新测,都只能达到50%左右的水平。这种情况让不少人感到沮丧。其实这不是模型本身有bug,而是训练数据和实际使用场景之间存在多重不匹配。理解这些问题,能帮你快速把识别率拉回到80%以上,还能为后续更复杂的计算机视觉任务打好基础。
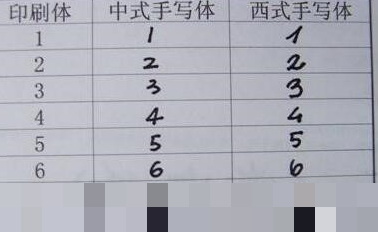
MNIST数据集诞生于1998年,由Yann LeCun团队整理发布。它包含6万张训练图像和1万张测试图像,每张都是28×28像素的灰度图,像素值从0到255,0代表纯黑背景,255代表纯白笔迹。这个数据集全部取自美国人口普查局员工和高中生的手写样本,因此带有浓厚的西方书写特征。在标准测试集上,模型通常能轻松达到95%以上的准确率,但一旦换成中国人自己写的数字,模型就立刻“认生”。这正是领域适应问题的典型表现:训练分布和测试分布不一致。
MNIST数据集的深层特性与现实局限
要搞清楚问题,先得弄懂MNIST的本质。数据集里的图片全部是单通道灰度,背景干净,数字居中,笔画粗细适中,没有太多噪声。模型通过卷积层提取边缘和曲线特征,池化层压缩维度,ReLU激活引入非线性,全连接层最终输出10类概率。整个训练过程使用交叉熵损失和Adam优化器,学习到的其实是西方手写体的统计模式。当你自己写的数字在笔画倾斜度、闭合程度或者位置偏移上稍有不同时,高层特征就会失配,softmax输出的置信度自然大幅下降。

此外,MNIST虽然经典,但它本质上是上世纪末的产物。今天看来,其样本多样性远远不够。现代项目里我们常用数据增强来弥补,但很多初学者直接用原始训练流程,导致模型泛化能力弱。把ubyte格式文件转成图片后,你会清晰看到西方人写的2下弯弧度更大,4的横竖交叉点偏右,6的圈更饱满,7的横杠短而倾斜。这些细节在像素级别就被模型牢牢记住,一旦输入变化,识别就容易出错。
核心原因一:文化书写风格带来的样本偏差

西方手写体和东方手写体在数字形态上差异极大,这才是很多同学准确率低的首要杀手。中国人写2的时候曲线往往更平直,4的竖线更靠左,6的闭合圈更圆润,7的上横线更短且角度不同。这些差异直接影响模型提取的低层边缘特征。假如你把训练集图片和自制图片并排对比,会发现位置、粗细、连笔习惯都不一样,导致模型无法正确匹配。
解决办法很简单:制作自制样本时主动模仿西方书写风格。建议大家打开Photoshop,用柔性画笔在28×28的画布中央位置绘制数字,避免靠边或者变形。很多同学实测后发现,这样调整后准确率能直接从40%跳到70%。同时注意笔画粗细保持中等,不要太细或太粗,因为MNIST原始样本的笔迹分布比较均匀。书写时还可以轻微旋转或偏移一点,模拟真实手写变异,进一步提升模型鲁棒性。
- 数字2:下弧更明显,模仿西方弯曲习惯
- 数字4:交叉点位置偏右,避免中国式直角
- 数字7:横杠短且略带倾斜
- 数字8:两个圈大小均衡
通过这些小技巧,自制样本就能和训练数据更贴合,模型识别起来自然顺畅很多。
核心原因二:图像预处理环节的隐形陷阱

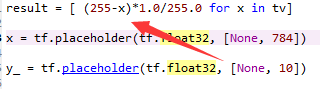
如果用训练集测试准确率也低,那99%是预处理出了问题。举个最典型的例子:一张标准的MNIST训练图片,里面是一个清晰的7。如果读入后做了错误的归一化操作,模型很可能把它认成8。为什么?因为原始MNIST像素是0-255范围,模型学的是这个分布。很多同学习惯用255减每个像素值再除以最大最小差的方式处理,结果颜色完全反转,白底黑字变成黑底白字,特征彻底变了。
import numpy as np
img = np.array(image) # 原始0-255灰度
# 错误归一化方式
wrong_norm = (255 - img) / 255.0 # 导致颜色反转,7被误判为8
# 正确方式
correct_norm = img.astype('float32') / 255.0正确预处理必须和训练时完全一致:简单将像素值除以255归一化到0-1区间,或者根据模型要求做均值方差标准化。千万不要随意加减操作。推荐进一步把图片转为二值图,只保留0和1两个值,彻底消除灰度过渡带来的干扰。这样做之后,识别率往往能大幅提升,因为模型不再被中间灰度值迷惑。

在实际操作中,可以用OpenCV快速实现二值化。阈值设在127左右,或者用Otsu算法自动选择最佳阈值。很多同学就是因为忽略了这一步,才导致整个项目卡在低准确率上。
核心原因三:数据分布偏移与模型泛化不足

即使预处理正确,个人手写习惯和整个MNIST数据集的统计分布还是存在偏差。笔画粗细、噪声水平、书写速度带来的抖动,都会让输入特征偏离模型学到的模式。卷积神经网络虽然强大,但本质上还是统计模型,对分布外数据敏感度高。这时就需要通过数据增强来扩大训练分布。
常见增强手段包括随机旋转5到15度、小范围平移、轻微缩放、添加高斯噪声等。这些操作能在训练阶段让模型见过更多变体,提升泛化能力。也可以收集少量自己的手写样本进行微调,或者直接在预训练模型基础上继续训练。高级一点,还可以可视化每一层的特征图,看模型到底关注了哪些像素区域,如果关注点和实际笔画不符,就知道哪里需要调整。
实战优化技巧:一步步把准确率拉升到80%以上
优化并不复杂,关键是系统性操作。首先,书写样本时严格居中,使用Photoshop柔性画笔,保证线条自然流畅。其次,所有测试图片必须走和训练完全相同的预处理管道,避免任何临时改动。第三,大力推荐二值化处理,只用0和1两个值训练和测试,能极大降低噪声干扰。

import cv2
import numpy as np
gray = cv2.imread('your_image.jpg', 0)
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
binary = binary.astype('float32') / 255.0 # 最终输入模型此外,在训练阶段加入数据增强库如torchvision.transforms,能让模型见过成千上万种变体。调试时记得输出混淆矩阵,看看哪些数字最容易混,比如7和1、4和9,针对性加强这些类别的样本数量。坚持这些做法,80%的准确率基本是水到渠成。
逆向分析思路:快速定位并修复瓶颈

遇到问题不要盲目改参数,先做诊断。打印每张测试图片的预测概率分布,找出置信度最低的样本重点分析。绘制混淆矩阵能直观看到错误类型。再用Grad-CAM或类激活图技术,观察模型到底把注意力放在了数字的哪个部位。如果关注区域和实际笔画不符,就说明特征提取出了偏差,需要调整网络深度或者增加正则化。
通过这种逆向思路,你不仅能修复当前项目,还能积累宝贵的调试经验,为以后更大型的视觉任务做好准备。

从MNIST到真实业务:复杂验证码识别的高效路径
手写数字识别的原理可以轻松延伸到实际业务场景。网站和App里常见的验证码越来越复杂,像极验和易盾推出的点选、无感通过、滑块验证、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间感知等多种类型。自己从零搭建模型不仅需要海量标注数据,还得不断应对反检测机制,流程繁琐,成本高昂,准确率还容易波动。
好消息是,现在完全不需要自己扛着所有复杂环节。专业识别平台已经把这些难题打包解决。通过稳定可靠的API接口,你可以实现无缝对接,直接传入图片或参数就能拿到高精度识别结果,无需操心预处理、模型训练和迭代维护。无论是企业级业务还是个人项目,都能快速上线,节省大量开发时间和服务器资源,让整个流程变得简单高效。
比如www.ttocr.com这样的平台,专门针对极验和易盾等全类型验证码提供精准服务。开发者只需调用几行代码的API,就能完成过去需要成百上千行代码和大量算力才能实现的工作。这正是当前AI落地最聪明的做法——把通用能力交给专业平台,自己专注核心业务逻辑。