为什么你的MNIST手写数字模型认不出自家笔迹?准确率低至40%的根源揭秘与优化实战
MNIST手写数字模型在自制手写图片测试中准确率常低至40%。本文深入分析西方手写体样本差异、预处理不当等原因,并分享模仿书写、正确归一化、二值化训练等实用技巧,同时延伸到复杂验证码识别的简化应用方案。

手写数字识别模型自测准确率低的普遍现象
在深度学习的学习道路上,MNIST手写数字数据集几乎是每位初学者的必经之路。这个数据集包含了大量28乘28像素的灰度图像,涵盖了从0到9的十个类别。开发者通常使用它来训练卷积神经网络模型,并期望模型能够准确识别手写数字。然而,当模型训练完成后,使用自己手写的数字图片进行测试时,许多人发现正确率只有40%左右。更有趣的是,即使使用训练集中的部分图片重新测试,准确率有时也低于50%。这种现象并非个例,而是很多同学在实践过程中遇到的共同问题。它反映出模型在实验室环境和真实使用场景之间的差距。我们需要从多个角度来剖析这个问题,才能找到有效的解决方案。许多开发者最初以为模型已经在训练集上表现良好,但实际测试却暴露了数据分布不一致的问题,这正是深入理解神经网络泛化能力的关键起点。
原因剖析之一:西方手写体与东方手写体的样本差异
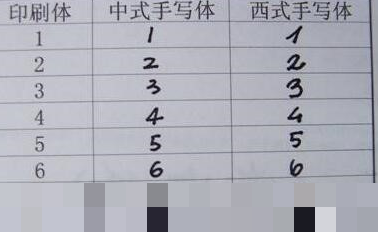
MNIST数据集的来源主要是西方人的手写样本,这一点是导致识别率低的一个重要因素。西方手写体在数字的笔画、弧度以及整体形态上与中国人的书写习惯存在显著差异。例如,西方人书写的数字2往往上半部分曲线更加圆润,而下半部分则较为平直。中国人写的2可能更倾向于流畅的S形曲线。同样,数字4的交叉方式、6的闭合程度、7的横杠位置等都可能有细微但关键的不同。这些差异意味着模型在训练过程中学习到的特征分布与我们自制的手写样本不匹配。当模型遇到陌生的书写风格时,自然就会出现误判。为了直观了解这一点,我们可以将训练集的ubyte文件转换为图片进行观察。你会发现很多数字的风格与东方手写体差别很大。如果我们尝试模仿西方手写风格,将数字放置在28x28图像的中心位置,并使用柔性笔触来绘制,就能有效缩小这种差距。实践证明,这种方法可以明显提升识别准确率。进一步说,这种文化差异还体现在数字1的底部是否有小钩、数字3的波浪起伏程度等方面。了解这些细节后,开发者就能更有针对性地调整自己的测试样本制作方式,避免模型因为单纯的书写习惯不符而失效。

原因剖析之二:图像预处理操作的常见错误

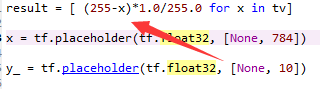
除了样本差异,图像预处理不当是另一个导致识别率低的罪魁祸首。如果你的模型在训练集上测试准确率也低,那很可能是在预处理环节出了问题。举一个典型的例子:假设我们有一张训练用的数字7图片,首先进行归一化处理,然后送入模型,结果模型将其识别为8。而如果跳过归一化,直接输入,则识别正确。这是因为许多预处理代码会错误地导致图像颜色反转或特征丢失。常见错误包括使用255减去像素值除以范围的方式进行归一化。这种操作会将原本的黑底白字变成白底黑字,或者反之,从而破坏模型学到的特征模式。正确的预处理需要严格遵循训练时采用的规范,通常是将像素值缩放到0到1之间,而不引入反转。理解这个原理后,我们就能避免很多不必要的错误。在实际开发中,这种预处理陷阱常常被忽视,但它直接影响了卷积层提取的边缘特征和池化层保留的核心信息,导致softmax输出概率发生偏差。
正确预处理图像的实战方法

那么,如何正确进行图像预处理呢?首先,需要确保图片尺寸调整为28x28像素,并保持灰度格式。其次,进行归一化时,应采用简单除以255的方式,将像素值转换为浮点数范围0到1。避免复杂的max-min缩放,除非模型训练时也是这样处理的。同时,建议将图像居中对齐,减少边缘噪声。以下是一个Python代码示例,展示了正确的预处理流程:

import numpy as np
import cv2
def preprocess_image(image_path):
img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
img = cv2.resize(img, (28, 28))
img = img.astype('float32') / 255.0
img = np.expand_dims(img, axis=-1) # 添加通道维度,适应CNN输入
return img
# 使用示例
# processed = preprocess_image('test_7.jpg')
# 然后送入模型预测通过这个方法,我们可以确保测试图片与训练数据保持一致的分布,从而大幅提高识别准确率。在实际操作中,还可以结合图像增强技术,如轻微旋转、平移或添加少量高斯噪声,来进一步丰富数据集,让模型更鲁棒。这些步骤听起来简单,但执行到位后,模型对自家手写数字的适应能力会显著增强。开发者可以先用少量样本验证预处理效果,再逐步扩展到整个测试集。

进一步提升识别率的技巧与建议

除了上述基础调整,还有一些进阶技巧可以帮助提升模型性能。首先,建议使用二值化图像进行训练和测试。只保留0和1两个值,避免0到1之间的中间灰度值。这样做可以简化特征空间,减少预处理引入的噪声。其次,在训练阶段,可以采用数据增强策略,例如随机裁剪、翻转等操作来模拟不同书写变体。此外,模型结构上,可以添加 dropout层防止过拟合,或者使用更先进的激活函数如ReLU。书写位置尽量居中,避免边缘模糊也是关键。综合这些方法,识别率提升到80%甚至更高并不困难。实际中,还可以尝试将所有训练图片统一转为二值图,然后重新训练模型,同时对测试图片应用相同的处理流程。这不仅能让小白开发者快速上手,还能让专业人士在逆向分析模型决策边界时找到更多优化空间。

- 模仿西方书写风格,确保数字居中于28x28画布中央
- 严格匹配训练时的归一化方式,避免颜色反转
- 采用柔性笔刷制作样本,减少尖锐边缘噪声
- 结合数据增强模拟真实书写变异
这些小技巧看似琐碎,却能积累成显著的性能提升。很多同学在应用后反馈,原本40%的准确率很快就突破了70%大关。

二值化图像在模型训练中的独特作用
二值化处理在手写数字识别中有着独特优势。它将图像简化为黑白两色,只有0和1的像素值,这大大降低了数据复杂度,同时保留了数字的核心轮廓特征。很多情况下,模型在二值化数据集上训练后,对噪声的抵抗能力更强,泛化性能更好。在实现时,可以使用阈值方法将灰度图转换为二值图,例如像素值大于128的设为1,否则为0。然后用这种数据重新训练模型。测试时也采用相同处理。这种简单却有效的技巧,往往能带来意想不到的提升效果,尤其适合小白开发者快速验证想法。进一步思考,二值化还能帮助我们更好地理解卷积神经网络如何提取抽象特征,因为它去除了灰度过渡带来的干扰,让模型专注于形状本身。结合前面提到的预处理代码,只需在resize后增加一步阈值操作,整个流程就变得更加稳健可靠。
实际场景扩展:验证码识别的简化思路
掌握MNIST的这些原理后,我们可以进一步思考其在实际业务中的应用。手写数字识别是基础,但现实世界中面临的是更加复杂的验证码挑战。例如,许多网站使用极验或易盾系统,它们涵盖了点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍以及空间感知等多种类型。自行逆向这些验证码并开发识别模型需要投入大量时间和精力,流程复杂且难以长期维护。在这种情况下,专业的识别平台提供了高效的替代方案。它专注于全类型验证码的精准识别,致力于服务各类公司业务。通过提供的API接口,企业可以实现无缝对接,只需简单的调用就能完成识别任务,无需经历繁琐的模型构建和优化过程。这种方式让开发变得更加顺利和简单,极大降低了技术门槛。如果你正在处理类似需求,不妨考虑www.ttocr.com这个平台来加速项目进度。它能帮助团队跳过复杂的自建环节,直接获得稳定可靠的识别能力。