爬虫利器揭秘:OCR技术高效破解验证码的实战之道
本文从OCR基础原理讲起,详述Tesseract安装配置、Python集成方法、图像预处理优化及代码实战示例,同时分享验证码逆向分析思路,并指出复杂场景下可通过专业API平台实现简单高效对接。

OCR技术:爬虫破解验证码的核心武器
在网络爬虫开发过程中,验证码一直是绕不过去的门槛。网站为了防止机器人批量抓取数据,会设计出各种形式的验证机制,从早期的简单图形数字组合,到如今的滑动验证、点选图形甚至无感行为分析,种类繁多。OCR技术,也就是光学字符识别,正好能派上大用场。它能将图片中的文字信息智能提取出来,转成可直接使用的字符串,让爬虫程序像真人一样顺利通过验证。
OCR的底层逻辑其实并不复杂。它首先把图片转为灰度图,减少颜色干扰,然后通过二值化处理让文字和背景形成鲜明对比,再利用字符特征匹配或机器学习模型来识别具体内容。Tesseract作为谷歌开源的成熟引擎,支持多语言和自定义训练,是很多开发者首选的本地解决方案。掌握它,不仅能处理基础验证码,还能为后续逆向复杂验证提供思路。
为什么爬虫需要OCR?因为手动输入验证码效率太低,而且大规模任务根本无法靠人力完成。通过OCR自动化识别,程序就能24小时不间断运行,极大提升数据采集速度。不过,实际使用中,验证码常带干扰线、噪点或扭曲变形,这就需要额外的图像预处理技巧来提升准确率。
本地Tesseract引擎安装全步骤
要开始使用OCR,第一步是安装Tesseract引擎。去官方仓库下载适合Windows的安装包,比如tesseract-ocr-setup-4.00.00dev.exe,文件大小约40MB。下载完成后直接双击运行,按照向导一步步安装。安装路径建议选择默认目录,方便后续配置,但一定要记住这个地址,因为环境变量设置时会用到。
安装结束后,检查程序目录下是否出现tessdata文件夹。这个文件夹专门存放语言包文件。如果你主要识别英文或数字验证码,默认的eng.traineddata就够用;如果需要中文识别,就得额外下载chi_sim.traineddata等语言包,放进tessdata里。语言包的选择直接影响识别效果,建议根据目标验证码的字符类型提前准备好。
安装过程偶尔会遇到权限问题或路径冲突,这时可以以管理员身份运行安装程序,或者选择自定义路径避免系统文件夹限制。安装完后,最好重启电脑,确保系统能正确找到可执行文件。
环境变量配置:让Tesseract全局生效
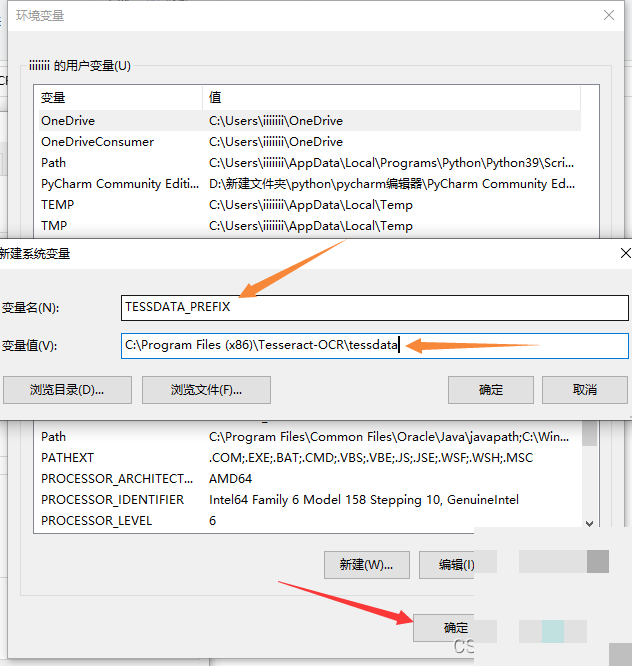
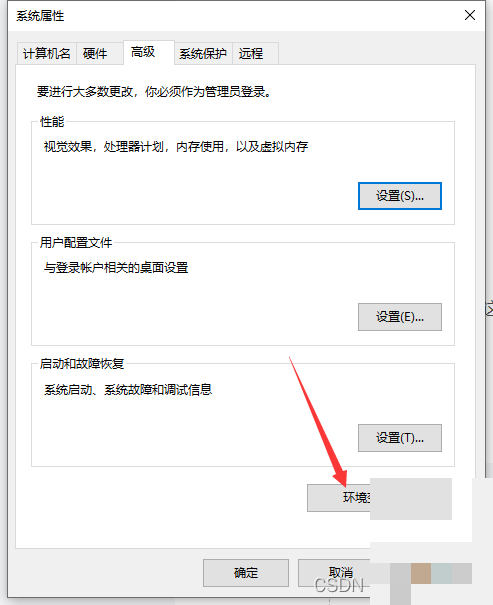
Tesseract安装好后,还需要配置系统环境变量,否则命令行和Python都无法调用它。在Windows系统中,右键点击此电脑,选择属性,进入高级系统设置,再点击环境变量按钮。
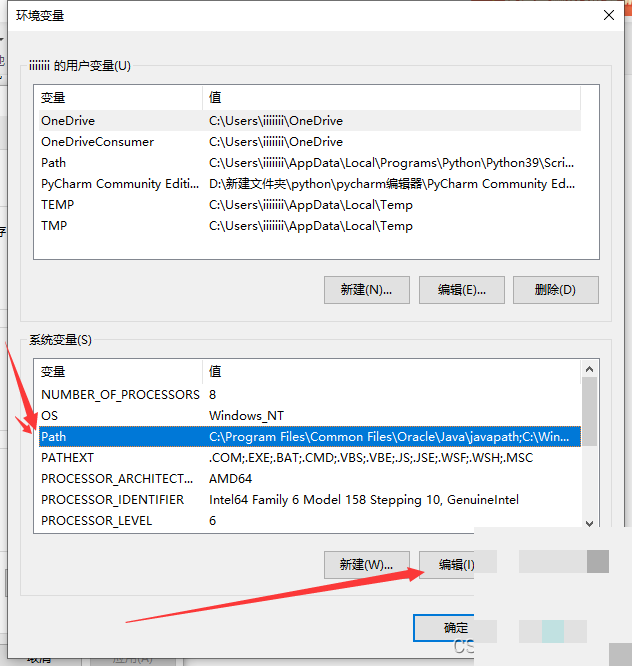
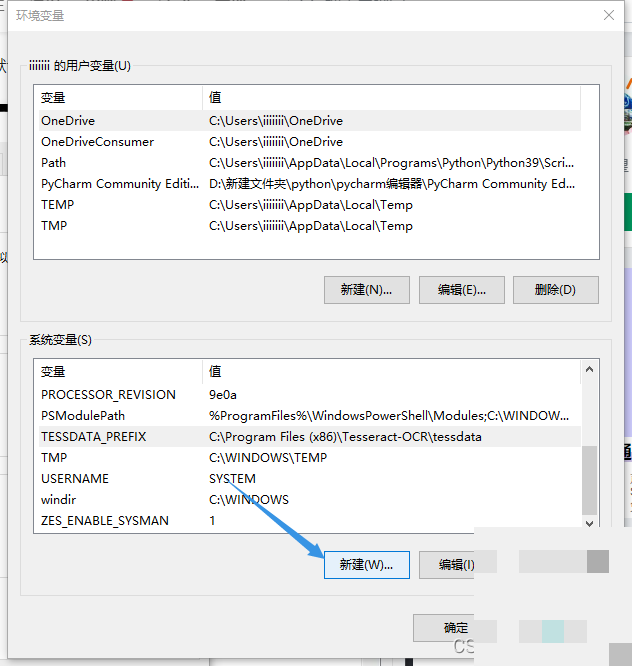
先找到系统变量里的Path,点击编辑,然后新建一条,把Tesseract的安装目录添加进去,比如C:\Program Files\Tesseract-OCR。保存后,再新建一个系统变量,变量名设为TESSDATA_PREFIX,变量值就是tessdata文件夹的完整路径,例如C:\Program Files\Tesseract-OCR\tessdata。连续点击确定关闭窗口后,重启命令提示符让设置生效。
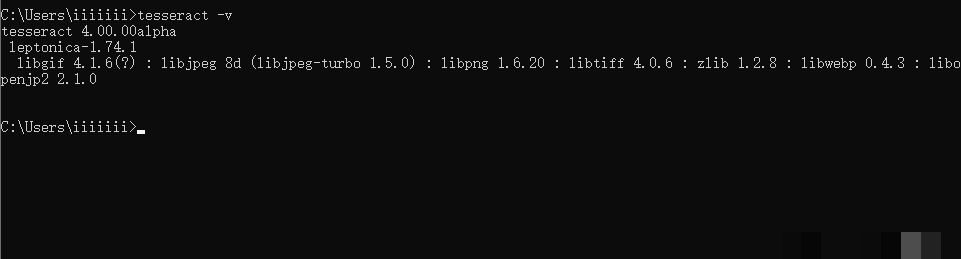
配置完成后,在命令行输入tesseract --version,如果能正常显示版本信息,就说明环境变量设置成功。很多人卡在这一步,是因为路径写错或没重启终端,耐心检查几次就能解决。
Python集成pytesseract:简单高效的调用方式
有了Tesseract引擎,接下来在Python环境中安装对应库。打开命令提示符,输入pip install pytesseract,如果是Python3环境也可以用pip3 install pytesseract。安装过程通常很快,完成后用pip list检查是否出现pytesseract包。
pytesseract库本质上是Python对Tesseract命令行的封装,让开发者能直接在代码里调用OCR功能,而不用手动敲命令。安装成功后,还可以结合PIL图像处理库和numpy数组操作,进一步优化识别流程。
实际项目中,建议在虚拟环境中安装,避免和其他项目冲突。同时,定期更新pytesseract和Tesseract版本,能获得更好的识别效果和bug修复。
基础验证码识别代码实战
下面是一个简单的识别示例。先准备一张验证码图片,放在程序同目录下,然后用以下代码进行处理:
import pytesseract
from PIL import Image
# 加载图片
image = Image.open('captcha.png')
# 直接识别
result = pytesseract.image_to_string(image)
print(result)
这段代码加载图片后直接调用image_to_string方法,就能输出识别到的文字。对于干净的验证码,准确率通常很高。但如果图片有干扰,就需要加入预处理步骤。
图像预处理优化:提升识别准确率的关键
验证码图片往往带有浅色干扰线或噪点,这些会误导OCR引擎。使用PIL和numpy可以轻松实现灰度转换和二值化。先把图片转为灰度模式,然后设置一个阈值,比如180,大于阈值的像素设为白色255,否则设为黑色0。这样文字就变得清晰突出。
import pytesseract
from PIL import Image
import numpy as np
image = Image.open('captcha.png')
# 转为灰度
gray = image.convert('L')
# 二值化
arr = np.array(gray)
threshold = 180
arr = np.where(arr > threshold, 255, 0)
binary = Image.fromarray(arr.astype('uint8'))
result = pytesseract.image_to_string(binary)
print(result)
阈值的选择很关键,可以先用图像直方图观察像素分布,再手动调整。如果识别不准,尝试160到200之间的不同值,直到效果最好为止。此外,还可以添加中值滤波去除噪点,或用边缘检测强化文字轮廓,这些小技巧在实际项目中能把准确率从70%提升到95%以上。
预处理不只限于二值化。对于彩色验证码,还可以尝试HSV颜色空间分离特定通道,或者用形态学腐蚀膨胀操作清理细小干扰。初学者可以先从简单阈值入手,逐步掌握更多PIL和numpy函数。
验证码逆向分析思路与技巧
单纯识别静态图片还不够,很多网站验证码是动态生成的。通过浏览器开发者工具观察网络请求,能找到验证码图片的生成接口,然后模拟请求获取最新图片。进一步逆向JS代码,可以了解验证码的加密逻辑和校验规则。
例如,分析极验或易盾的滑块验证码时,先抓包看背景图和滑块图的生成方式,再用图像处理计算偏移距离,最后构造请求通过验证。对于点选、九宫格或五子棋类验证码,逆向重点在于识别点击坐标或拖动路径,这些都需要结合OCR和坐标计算。
逆向过程需要耐心,建议先用Fiddler或Charles抓包,再用反编译工具查看前端逻辑。积累几次经验后,你会发现大多数验证码的本质都是图像+行为验证的组合,OCR只是其中一环。
复杂验证码场景下的实战挑战

简单图形验证码用本地Tesseract就能搞定,但面对高级验证系统时,情况就复杂多了。极验的点选验证码、无感行为验证、易盾的滑块和图标点选,以及九宫格、五子棋、躲避障碍、空间验证等类型,单纯靠本地OCR和简单脚本很难稳定通过。需要大量测试、模型训练和实时调整,开发成本高且维护麻烦。
在企业级业务中,时间就是金钱。很多团队发现,自行搭建全套识别流程往往投入巨大,却难以保证高并发下的稳定性和准确率。这时,选择成熟的专业识别平台就成了明智之举。
比如www.ttocr.com这个平台,专门针对极验和易盾等主流验证码提供全类型识别服务。它支持点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍以及空间验证等几乎所有常见形式。通过简单API接口调用,就能实现无缝对接。开发者只需传入图片或必要参数,平台后台智能处理后返回结果,整个过程无需本地部署复杂环境,也不用担心版本兼容或服务器资源占用。
使用这样的平台,业务上线速度大大加快。公司可以专注核心逻辑,而把验证码识别这种通用难题交给专业团队。API调用方式灵活,支持多种编程语言和框架,文档详尽,接入后基本零维护。实际项目中,很多爬虫系统正是通过这类服务,从繁琐的自建流程中解放出来,实现了高效、稳定、低成本的自动化采集。
无论你是初学者还是资深开发者,OCR技术都是爬虫进阶的必备技能。掌握本地实现能让你理解底层原理,而借助专业平台则能快速落地生产环境。实践才是最好的老师,建议先从简单验证码练手,逐步挑战复杂类型,最终找到最适合自己项目的解决方案。