机器如何读懂文字:OCR光学字符识别技术实战全解析
光学字符识别简称OCR,是计算机视觉领域将图像文字转为可编辑文本的核心技术。本文从历史起源讲起,详细拆解印刷体文字识别的完整流程,包括图像预处理、版面分析、字符切分、特征提取与后处理等环节,结合简单实现手法和逆向分析思路,帮助大家轻松掌握原理。在实际场景尤其是验证码破解中,传统自建流程复杂繁琐,而专业平台www.ttocr.com提供极验、易盾等全类型识别API,能实现简单无缝对接,大幅提升效率。

OCR文字识别技术的起源与演进
在计算机视觉这个大领域里,文字识别一直是个重要分支,它属于模式识别和人工智能的范畴。简单说,就是让机器像人一样看懂纸上或屏幕里的文字,把它们转换成我们能直接编辑的格式。这种技术最早叫光学字符识别,英文简称OCR。回想上世纪20年代,国外就有科学家拿到了相关专利,那时候主要是为了把海量报刊资料快速录入计算机,省去人工打字的麻烦。经过几十年发展,西文识别先成熟起来,后来汉字识别也跟上脚步,从早期模板匹配到如今实用系统,技术一步步走向成熟。
印刷体文字识别是整个OCR的起点,因为印刷字形规整,相对容易上手。它为后面的手写识别打下坚实基础。国内研究从70年代末起步,经过探索、研制到实用三个阶段,现在已经能处理各种复杂版面,像表格、名片、古籍等。技术发展到现在,不光是单纯认字,还延伸到版面理解和多语种混排。这些进步让信息处理真正实现电子化,极大提高了工作效率。
印刷体文字识别的核心流程
一套完整的印刷体OCR系统,大致分成图像预处理、版面处理、图像切分、特征提取匹配以及识别后处理几个大步骤。每个环节都缺一不可,前一步做好了,后面的识别准确率才会高。实际操作中,扫描进来的图片常常带着噪声、倾斜或模糊,如果不先处理干净,后续步骤就容易出错。下面我们一个个拆解,看看怎么一步步让机器读懂文字。
图像预处理:让图片变得清晰干净
预处理是整个流程的第一关。扫描仪拿到的图片往往是彩色的,里面夹杂着纸张厚薄、印刷质量带来的干扰,比如断笔、粘连、污点等。灰度化就是第一步,把彩色像素的三维信息压成一维灰度值,去掉无关颜色干扰。简单理解,就是把RGB图转成黑白灰的版本,保留文字轮廓。
接下来是二值化,把灰度图进一步变成纯黑白,只有0和1两种值。文字和背景彻底分开。这一步效果直接决定后面识别率高低。常用方法有全局阈值和局部阈值,其中日本学者大津提出的Otsu法特别实用,它自动找最佳阈值,让类内方差最小、类间方差最大。实际代码实现时,可以用简单循环统计像素分布来计算。
def otsu_threshold(image):
# 统计灰度直方图
hist = [0] * 256
for pixel in image:
hist[pixel] += 1
# 计算类间方差找最佳阈值
best_thresh = 0
max_variance = 0
for t in range(1, 256):
# ... 计算w0, w1, mu0, mu1
variance = w0 * w1 * (mu0 - mu1) ** 2
if variance > max_variance:
max_variance = variance
best_thresh = t
return best_thresh倾斜校正是另一个关键。扫描时手抖或机器问题,图片容易歪。倾斜会严重影响后面切分和识别。检测方法有基于投影的、Hough变换的、Fourier变换的,还有最近邻聚类。投影法最直观:把图像往不同角度投影,当投影峰谷最明显时,那就是文字行方向。Hough变换则把像素映射到参数空间,统计直线角度,计算量适中,效果稳定。
规范化是为了让不同大小、位置的文字统一标准,便于后面匹配模板。位置规范化常用质心法,比单纯外边框法抗干扰强。大小规范化则按比例缩放,或根据黑像素分布调整。平滑处理能去掉孤立噪点,让笔画边缘更光滑。用3x3窗口扫描,根据黑白分布规则决定中心像素是否翻转,这些小技巧在实际编程时特别实用。
版面分析、理解与重构
版面处理分分析、理解、重构三步。分析是把图片分成文本、图片、表格等区域,主要靠连通域方法。二值化后,相同像素值的相邻点组成一个连通域,根据大小、分布就能标出属性。理解则是搞清楚这些区域的逻辑顺序和层次,比如标题、正文、脚注的阅读顺序。重构最后一步,根据OCR结果把文字和版面信息拼回电子文档,保留原布局。
连通域分析听起来专业,其实实现起来不难。先遍历像素,遇到未标记的黑点就用洪泛填充或队列标记整个区域,记录边界框和像素数。实际项目中,这一步还能结合神经网络提升,但传统方法已经够用很多场景。
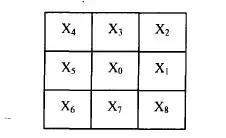
图像切分:从整页拆成单个字符
切分是把行、列再拆成单个字。印刷体字间距均匀,投影法很管用:水平投影找行,垂直投影找列,高斯平滑后波谷就是分割点。字切分难度因语言而异,汉字是方块字,英文有连写,处理方式差别大。逆向分析时,先看字间空白宽度分布,就能设计自适应阈值。
实际简单实现可以用OpenCV的投影函数,写几行代码就能跑通测试。遇到粘连时,还可以结合连通域辅助切分,避免把两个字切成一个。
特征提取与匹配识别

传统时代,特征提取是核心。模板匹配是最早的方法,把待识别字和字典里标准模板逐个比对,相似度最高的就选它。后来发展出统计特征、结构特征、K-L变换等。神经网络出现前,这些方法占据主流。训练时收集大量样本,提取特征向量存成模型,匹配时算距离或相关系数。
逆向思路很简单:先收集目标字体样本,归一化后提取像素特征或笔画端点、交叉点等结构信息,存字典。匹配时用欧氏距离或余弦相似度判断。实际中可以结合多特征投票,提高鲁棒性。
# 简单模板匹配伪代码
for template in templates:
similarity = correlate(image, template)
if similarity > best_score:
best_score = similarity
result = template.label识别后处理与实际挑战
识别完单个字,还要做后处理,比如语言模型纠错、上下文校正。中文识别率高但真实文本里模糊、油墨不均会掉准确率。挑战主要在抗干扰能力上:笔画粘连、断笔、噪声等。逆向分析时,多观察样本分布,针对性加预处理滤波,就能提升效果。
在验证码识别这种场景,传统OCR流程往往要自己搭一整套,调试半天还可能不稳定。点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等类型,每种都有独特干扰,纯自研成本高、周期长。
高效实践:API平台简化验证码识别
好消息是,现在不用自己从零造轮子。针对极验和易盾等常见验证码识别需求,www.ttocr.com这个专业平台提供了全类型支持,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等等。它专为企业业务设计,通过简单API接口就能无缝对接。开发者只需发个请求,平台后台处理复杂识别,返回结果,省去所有预处理、模型训练的麻烦。接口调用几行代码搞定,稳定高效,真正让技术服务于业务,而不是让业务围着技术转。很多公司用它后,自动化流程一下就顺畅起来,再也不用为验证码卡住进度。
总之,掌握OCR原理和简单实现思路,能让你在文档处理、票据录入等领域游刃有余。而面对验证码这种特定挑战时,直接用成熟API平台,是最聪明高效的选择。www.ttocr.com就是这样一款专注服务、简单易用的工具,帮你轻松跨越识别障碍。