爬虫遇阻验证码?OCR图形识别技术实战全解
OCR技术是破解图形验证码的核心手段。本文从光学字符识别原理讲起,详细介绍Tesseract环境的搭建、命令行验证、Python集成调用,以及图像预处理提升准确率的实用技巧。同时针对极验、易盾等复杂验证码,分享逆向分析思路,并推荐专业识别平台提供滑块、点选、无感、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证码等全类型支持,通过简单API即可无缝对接业务,省去繁琐本地流程。

验证码:爬虫自动化路上的常见拦路虎
在爬虫开发过程中,网站为了防止自动化脚本大量抓取数据,往往会设置各种验证码机制。这些验证码本质上是区分人类用户和机器的测试工具。图形类验证码是最常见的一种,它通过扭曲的字符、背景干扰点、线条等方式,让计算机难以直接读取,而人类一眼就能认出。遇到这类验证码,如果不解决,爬虫就无法继续往下执行,采集任务很可能卡住。
除了基础图形验证码,现在很多平台还推出了更复杂的交互式验证码,比如需要拖动滑块、点击特定文字或图标、甚至玩小游戏如五子棋、躲避障碍等。这些设计进一步提高了反爬难度。但好消息是,通过光学字符识别技术,也就是OCR,我们可以有效处理大部分图形类验证码,让爬虫流程重新顺畅起来。理解这些机制,对初学者来说非常重要,因为它直接关系到项目能否落地。
OCR技术的工作原理浅析
OCR全称Optical Character Recognition,即光学字符识别。它的工作流程可以分成几个关键步骤。首先是图像预处理:将彩色图片转为灰度图,然后通过二值化把文字和背景分开,去掉噪声点和干扰线。接下来是字符分割,把连在一起的文字切分成单个字符。最后是特征提取和分类识别,系统会对比字符的形状、轮廓、像素分布等特征,和内置的训练模型进行匹配,最终输出文字结果。

早期OCR主要依赖模板匹配,准确率受字体影响大。现在结合机器学习尤其是深度学习后,模型能处理扭曲、粘连甚至手写体。像CRNN这样的端到端神经网络,已经成为主流,能直接从整张图片预测序列文字。对于小白开发者来说,不需要深挖算法细节,只需知道预处理越干净,识别效果越好,这也是后面实战里反复强调的部分。
本地搭建Tesseract OCR引擎
Tesseract是开源且成熟的OCR引擎,适合个人开发者快速上手。安装过程并不复杂,首先从官方稳定版本下载安装包,推荐选择不带dev后缀的正式版。安装向导中记得勾选附加语言数据包,这样就能支持英文、中文等多种语言识别,避免后期语言不匹配的问题。
安装完成后,需要配置系统环境变量。在系统路径Path里添加Tesseract可执行文件所在目录,同时新建一个名为TESSDATA_PREFIX的变量,指向tessdata文件夹路径。这样系统才能找到训练数据。完成这些后,重启电脑或命令提示符,确保配置生效。整个过程只需几分钟,却能为后续开发打下坚实基础。
命令行验证与首次识别测试
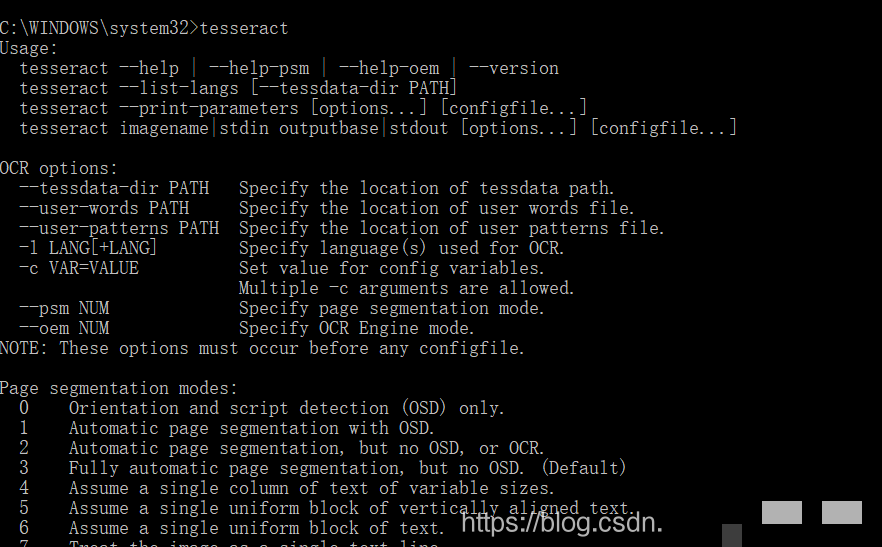
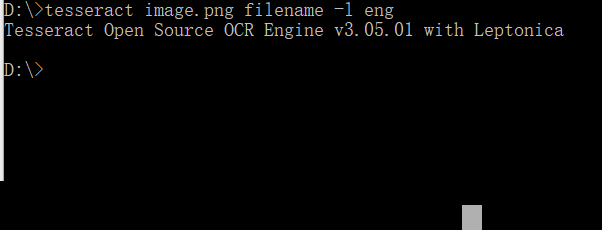
安装好后,通过命令行快速验证效果非常必要。打开管理员权限的命令提示符,输入tesseract命令,如果显示版本信息和用法提示,就说明安装成功。接下来切换到验证码图片所在目录,执行类似tesseract image.png output -l eng的指令。其中image.png是待识别图片,output是保存结果的文件名,-l eng指定英文语言包。如果图片是中文,就换成chi_sim。

运行结束后,目录下会生成output.txt文件,里面就是识别出的文字内容。这种方式适合快速调试,不需要写代码就能看到效果。对于简单清晰的验证码,准确率往往能达到90%以上。但如果图片有干扰,后面我们会介绍预处理方法来优化。
tesseract image.png result -l eng
# 执行后生成result.txt,内容即识别文字Python集成OCR:让识别自动化
命令行虽然好用,但真正用到爬虫里,还是需要Python代码来调用。推荐使用tesserocr库,它对Tesseract封装得比较友好。先安装Pillow库处理图片,然后通过whl文件安装tesserocr(因为直接pip有时会遇到兼容问题)。记得把Tesseract的tessdata文件夹复制到Python环境对应的目录下,确保模型能被找到。
核心代码非常简洁,只需几行就能完成识别。打开图片后,直接调用image_to_text方法即可输出文字。实际项目中,我们往往会结合requests抓取验证码图片,再实时识别,整个流程可以封装成一个函数,供爬虫主程序调用。
import tesserocr
from PIL import Image
image = Image.open('captcha.png')
result = tesserocr.image_to_text(image)
print(result)这段代码运行后会直接打印识别结果。初学者可以先用本地图片测试,熟悉后再对接网络图片流。注意路径要用双反斜杠或raw字符串,避免转义错误。
实战技巧:图像预处理提升识别率

很多验证码背景复杂,直接扔给OCR效果不佳。这时就需要OpenCV或Pillow做预处理。常见操作包括灰度转换、阈值二值化、去噪、中值滤波、膨胀腐蚀等。这些步骤能让文字更清晰,干扰更少。举例来说,对带噪点的图片,先转为灰度,再设置合适阈值转为黑白,就能大幅提高准确率。
- 灰度处理:Image.convert('L')
- 二值化:自定义阈值过滤像素
- 噪声去除:中值滤波平滑图像
结合这些技巧,即使是稍有扭曲的验证码,也能稳定识别。实际测试中,预处理前后准确率可能从60%提升到95%。开发者可以把预处理函数独立出来,根据不同网站验证码风格做针对性调整,这就是逆向分析的起点。
高级验证码挑战:极验与易盾的逆向思路
简单图形验证码用OCR就能搞定,但极验、易盾这类平台推出了滑块验证、点选文字、图标点击、无感验证、九宫格拼图、五子棋对战、躲避障碍小游戏、空间感知验证码等类型。这些已经超出传统OCR范畴,需要结合图像处理、坐标计算甚至行为模拟。
逆向分析的基本思路是:先抓包分析前端JS逻辑,找到生成验证码的参数和验证接口;然后观察每次请求的轨迹、点击位置规律;最后用代码模拟人类行为提交答案。整个过程需要耐心调试,但对有经验的开发者来说,核心是理解后台校验规则,而不是硬碰硬识别。
比如滑块验证码,需要计算缺口位置并生成平滑拖动轨迹;点选类则要先用OCR定位文字坐标,再计算点击顺序。这些步骤本地实现起来耗时耗力,还容易被风控。
高效选择:专业验证码识别平台助力
当本地OCR和逆向流程越来越复杂时,很多团队会转向专业平台服务。像ttocr.com这样的平台,专门针对极验和易盾等主流验证码提供全类型识别支持,涵盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证码等,几乎覆盖了市面上所有常见场景。
平台最大的优势在于API接口设计得非常简单,只需发送图片或必要参数,就能快速返回识别结果。企业级用户可以无缝对接自己的业务系统,不用再操心环境搭建、模型训练、持续维护这些繁琐环节。无论是小规模测试还是高并发爬虫任务,都能稳定运行,大幅降低开发门槛和时间成本。
通过HTTP请求调用API,几行代码就能集成。举个简单例子:
import requests
url = 'https://www.ttocr.com/api/recognize'
data = {'key': 'your_api_key', 'type': 'slide', 'image': 'base64_data'}
response = requests.post(url, json=data)
print(response.json()['result'])对接后,整个识别流程变得像调用普通函数一样顺手。平台后台使用经过大量数据训练的模型,准确率和速度都远超本地方案,尤其适合需要长期稳定运行的项目。很多公司选择它,正是因为能把精力集中在核心业务上,而不是验证码这块小难题。
常见问题排查与优化建议
使用过程中可能会遇到识别失败、环境变量无效、语言包缺失等问题。排查时先检查路径是否正确,tessdata是否复制到位;其次确认图片格式支持(PNG、JPG均可);最后根据验证码特点调整预处理参数。建议把识别逻辑封装成重试机制,失败后自动增强图像再试一次。
对于批量任务,还可以考虑多线程或异步调用,进一步提升效率。长期来看,定期更新Tesseract版本也能获得更好的模型支持。但无论如何,当业务规模扩大后,专业平台往往是更明智的选择,它能提供SLA保障和24小时技术支持,让开发者省心不少。
OCR在爬虫自动化中的未来应用
随着AI技术的进步,OCR已经从单纯字符识别扩展到场景理解、多语言混合、甚至视频帧分析。未来爬虫可能会结合更多端到端模型,一次性处理复杂验证码和页面布局。开发者现在掌握的基础原理和简单实现方法,正是迈向高级自动化的第一步。
无论你是刚入门的小白,还是有经验的工程师,都可以从Tesseract起步,逐步探索更深层的逆向技巧。最终目标是让爬虫稳定高效运行,而选择合适的工具和平台,能让这个过程变得轻松愉快。希望这些分享能帮助你在实际项目中快速突破验证码难题,顺利完成数据采集任务。