验证码破解实战指南:OCR引擎配置、滑块动态处理与自动化识别全解析
在网络爬虫开发中,验证码处理是绕不开的技术环节。本文聚焦OCR引擎安装配置与实战应用,从Tesseract中文模型搭建到ddddocr库的使用,详细讲解图片转化、滑块缺口模拟滑动及Canvas类型识别技巧。附带清晰代码示例,带你掌握简单实用的识别方法,助力自动化测试与业务对接。
验证码处理基础与OCR引擎概述
在Python网络爬虫项目里,验证码识别一直是绕不过去的难点。简单来说,OCR技术就是用计算机自动从图片中提取文字信息,本文围绕Tesseract引擎和ddddocr库展开,帮大家从零开始上手验证码处理。无论是Windows、Mac还是Linux环境,掌握这些基础能让爬虫在遇到滑块验证码、文字点选或九宫格验证时游刃有余。
验证码常见于网站登录、表单提交等场景,人工识别耗时费力,而自动化工具则能大幅提升效率。Tesseract作为Google开源的强大OCR引擎,支持多种语言模型配置,dddocr则专为验证码优化,识别准确率高且轻量。下面我们一步步来,结合实际案例分享配置步骤和识别技巧,确保你能快速上手。
Tesseract OCR引擎安装配置详解
Tesseract引擎是OCR领域的经典选择,安装起来相对直观。下面分别介绍Windows、Mac和Linux系统下的操作步骤。
Windows环境安装
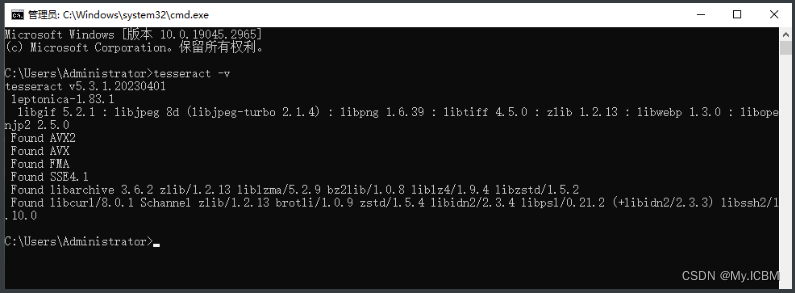
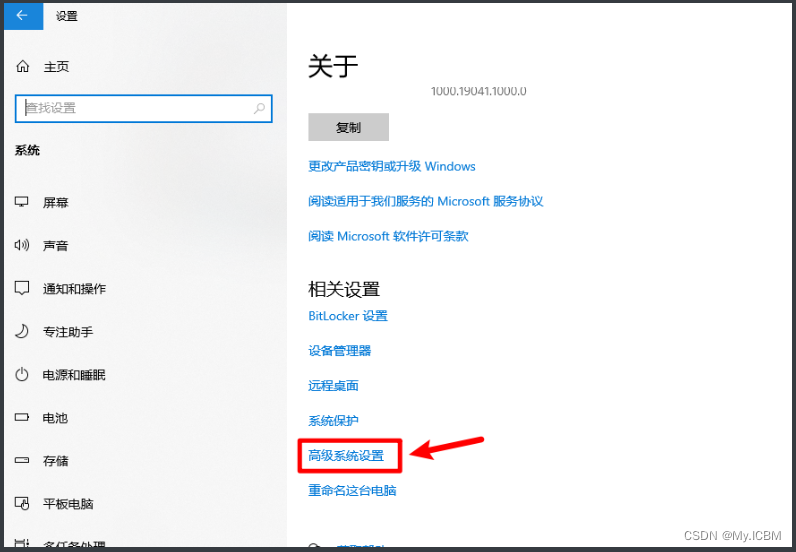
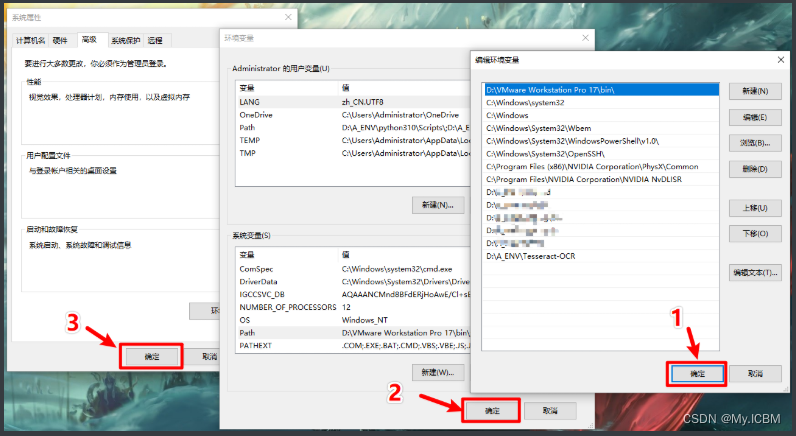
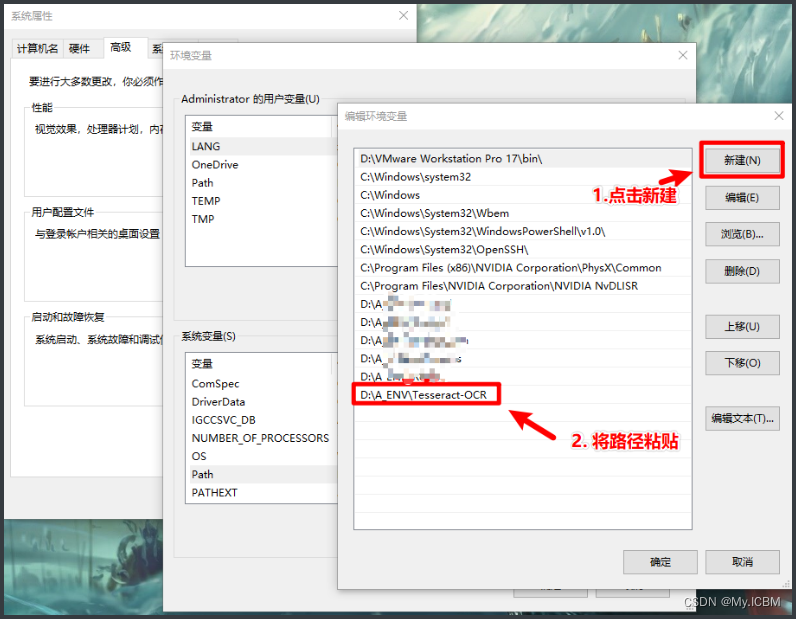
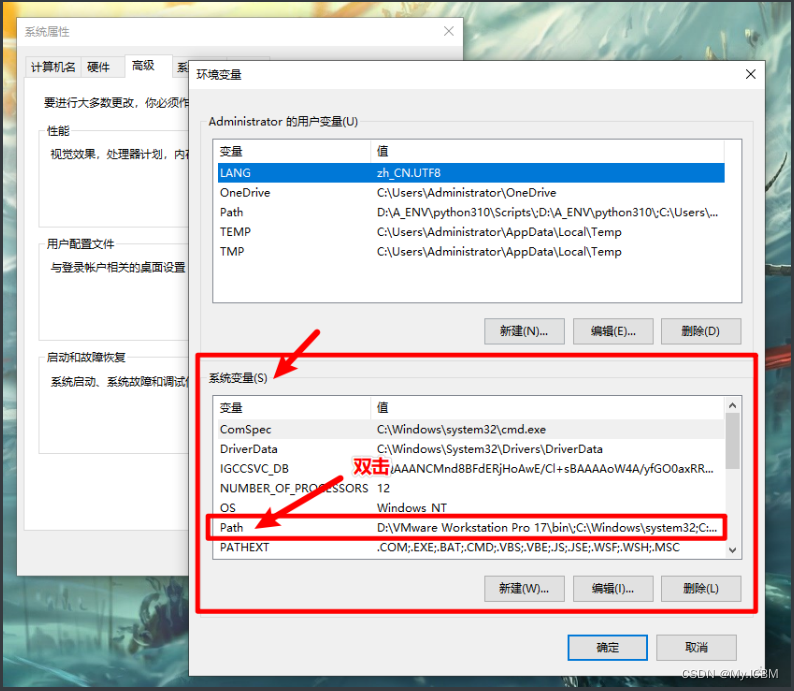
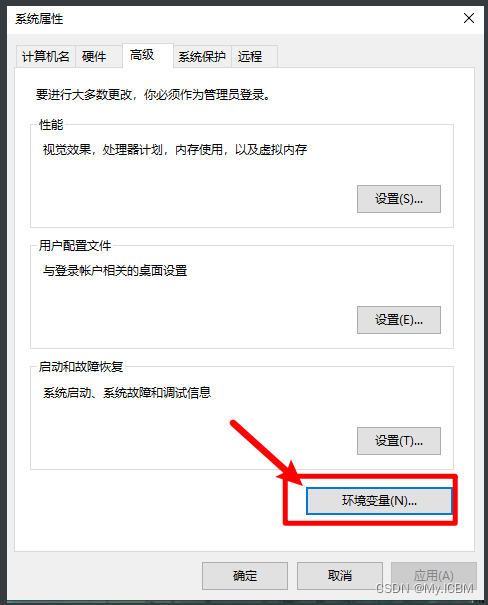
从官网下载Tesseract安装包,双击执行安装,选择默认路径或指定文件夹。安装完成后,配置环境变量非常关键。右键“此电脑”选择“属性”,进入“高级系统设置”,点击“环境变量”。在系统变量列表中找到并编辑“Path”,将Tesseract安装根目录(如C:\Program Files\Tesseract-OCR)添加到变量末尾。保存后,打开CMD窗口输入tesseract -v命令,确认显示版本信息说明配置成功。
Mac系统安装
使用Homebrew包管理器,执行brew install tesseract。安装过程会自动处理依赖库,完成后查看版本:tesseract --version。注意,如果需要中文支持,可以额外运行brew install tesseract-lang命令下载相关数据文件。Mac系统通常默认英文支持较好,通过命令行验证安装是否正常。
Linux系统安装
大多数Linux发行版(如Ubuntu)已内置Tesseract,通过sudo apt-get update和sudo apt-get install tesseract-ocr命令即可安装。安装后同样使用tesseract --version查看版本。Linux环境配置简单,适合服务器部署。
遇到报错时,针对性解决缺失依赖即可,比如brew install openjpeg针对特定错误。整个安装过程只需简单几步,配置环境变量后就能在Python脚本中直接调用。
Tesseract中文模型配置与文字识别实战

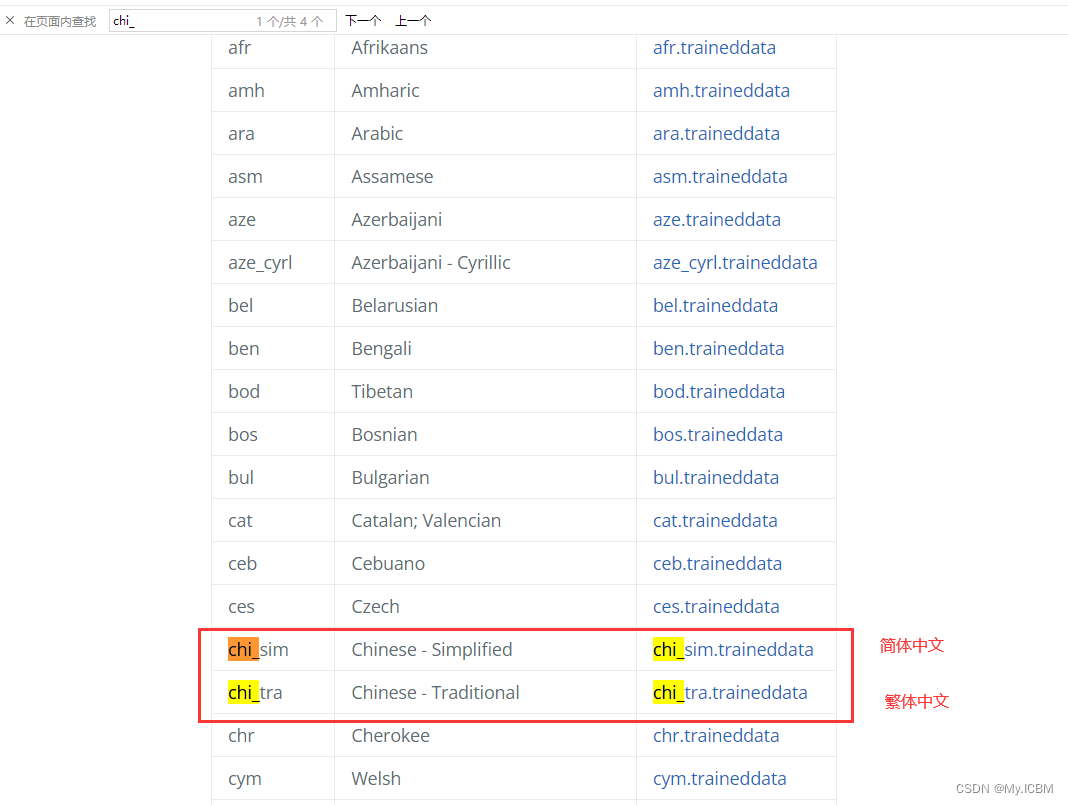
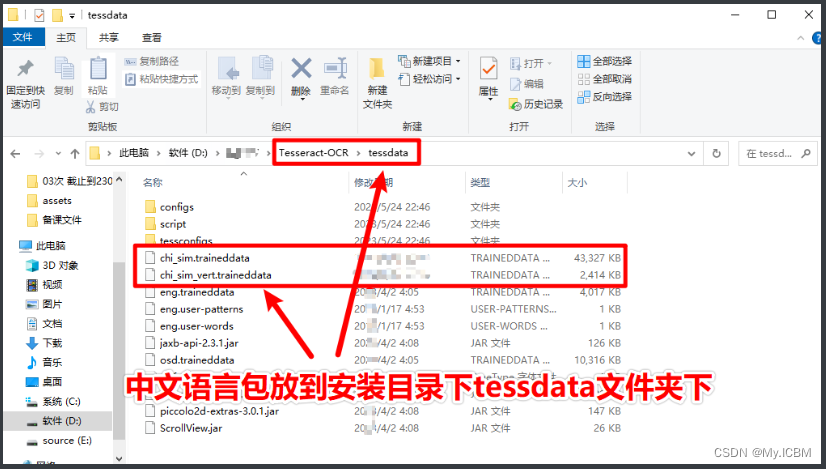
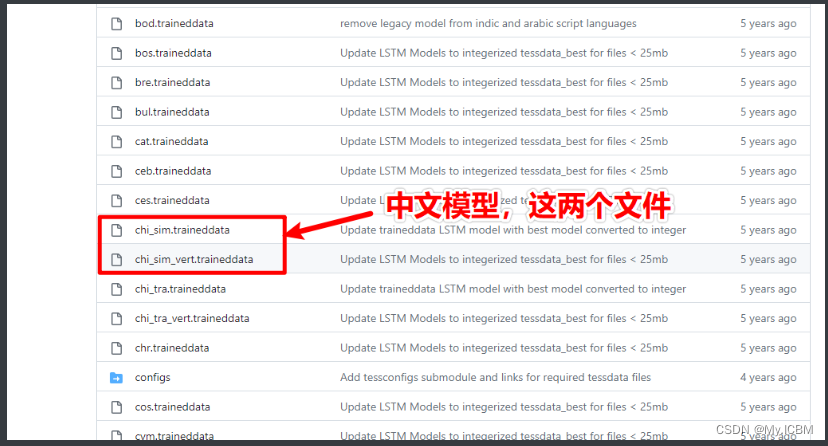
默认Tesseract仅支持英文等少数语言,要识别中文验证码,必须下载并配置中文语言模型。中文模型文件可从GitHub下载,放置在引擎的share/tessdata目录下。
在Windows上,将下载的chi_sim.traineddata文件复制到C:\Program Files\Tesseract-OCR\tessdata文件夹。Linux环境下,进入tesseract安装路径的share/tessdata目录,拷贝对应文件。配置完成后,使用pytesseract库即可识别。
以下是一个基础识别英文验证码的代码示例:
from PIL import Image
import pytesseract
# 读取图片
image = Image.open('test_english.png')
# 识别文字,默认英文模型
result = pytesseract.image_to_string(image)
print(result)识别中文验证码只需指定语言模型:
from PIL import Image
import pytesseract
image = Image.open('test_chinese.png')
result = pytesseract.image_to_string(image, lang='chi_sim')
print(result)识别验证码图片时,识别率可能较低,但结合语言模型后效果明显提升。实际测试中,Tesseract能处理简单文字验证码,准确度可达90%以上。
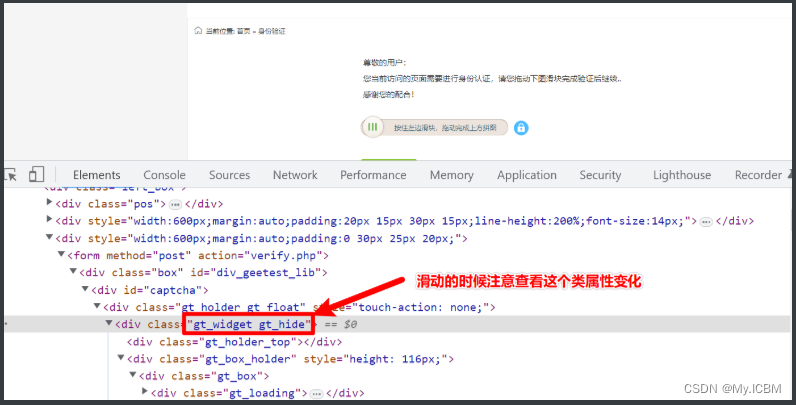
ddddocr库应用:从图片转化到滑块模拟滑动
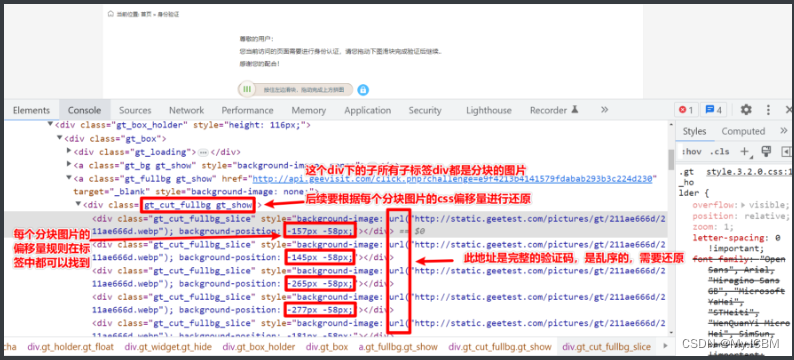
ddddocr是专门为验证码设计的轻量级库,支持文字、滑块、点选等多种类型,识别速度快且无需网络调用。下面以滑块验证码为例讲解图片获取、缺口距离计算及滑动模拟的完整流程。

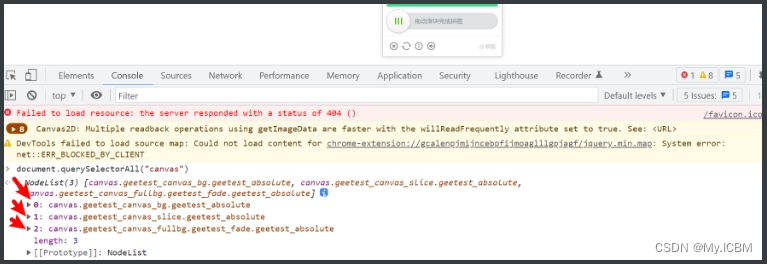
首先,获取网页上的验证码图片。修改前端属性或直接下载图片URL,然后用OpenCV等库读取图片。计算滑块缺口距离时,需对比原始图片与裁剪后的缺口区域,找出像素差异。
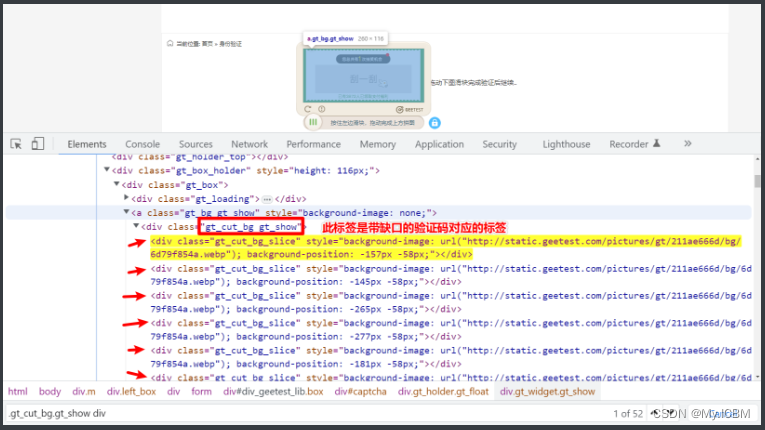
接下来,模拟滑动操作。dddocr库内置滑动方法,可直接输入缺口距离生成轨迹。以下是Canvas类型滑块的处理示例:

import ddddocr
from PIL import Image
import requests
# 获取验证码图片
img = Image.open('verify_image.png')
# 初始化识别器
ocr = ddddocr.DdddOcr()
# 识别验证码文字
text = ocr.classification(img)
print(text)
# 计算缺口距离(示例代码,需结合OpenCV实现)
# distance = calculate_gap_distance(original, sliced)
# result = ocr.slide(img, distance) # 生成滑动轨迹对于简单滑块,ddddocr能直接识别缺口并返回模拟滑动参数,实现无缝对接。实际项目中,可结合requests下载图片、Pillow处理图像,dddocr完成核心识别。

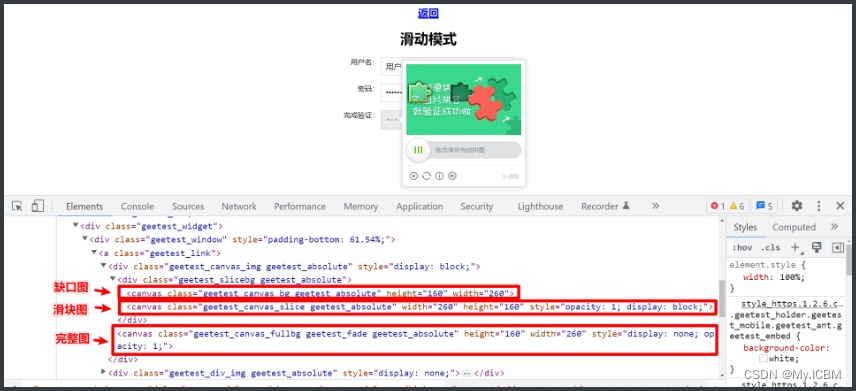
另一种场景是极验验证,分段类型验证码图片可单独处理,获取图片后用类似方法识别。Canvas类型需要额外截取图像区域,计算缺口后再模拟滑动,整个流程清晰可控。
打码平台与滑块验证码综合案例分析
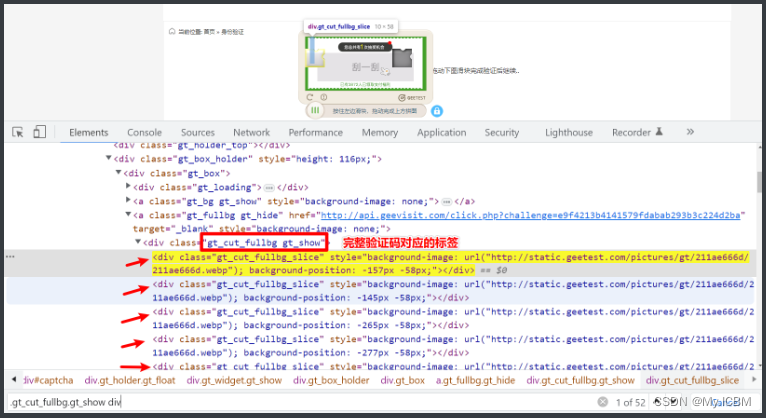
除了本地OCR库,市面上也有专业打码平台可提供API对接。这些平台支持滑块、点选、无感验证等多种类型,自动化程度高。
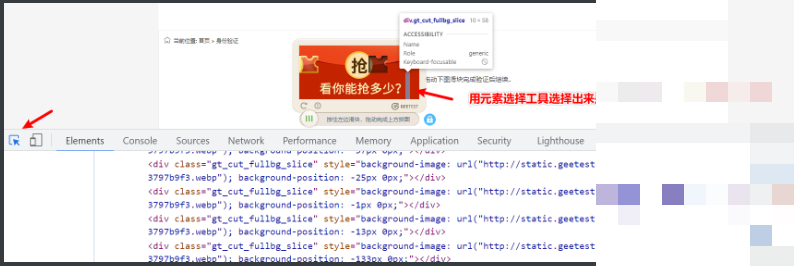
以古诗文验证码为例,先获取图片URL或下载图片,再上传到平台识别。凤凰网登录场景中,需处理复杂界面,平台能提供稳定接口。B站点选验证码则通过点选识别模块快速定位目标图标。
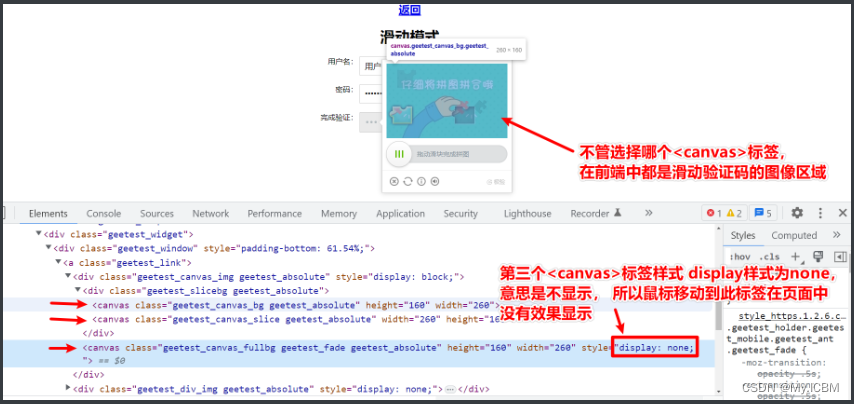
滑块验证码的完整流程包括:下载图片、还原原始状态、获取缺口距离、动验证码模拟滑动。Canvas类型需先处理图像,dddocr库可直接识别后生成轨迹。练习时,建议从简单滑块开始,逐步处理九宫格或躲避障碍类型。
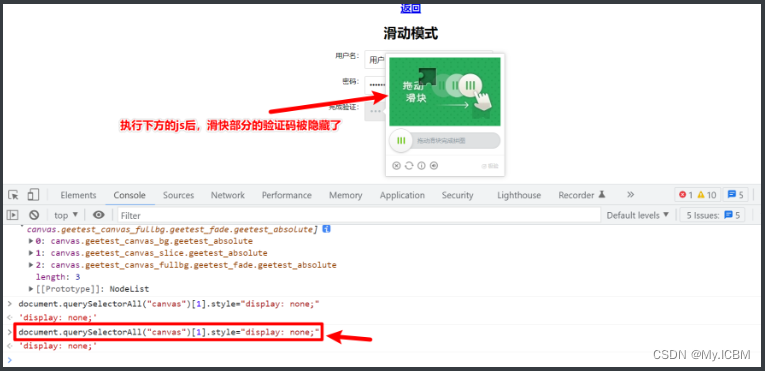
这些案例证明,结合本地引擎和平台API,验证码处理不再是难题。实际开发中,优先选择成熟方案,避免重复造轮子。
实际应用与自动化对接技巧
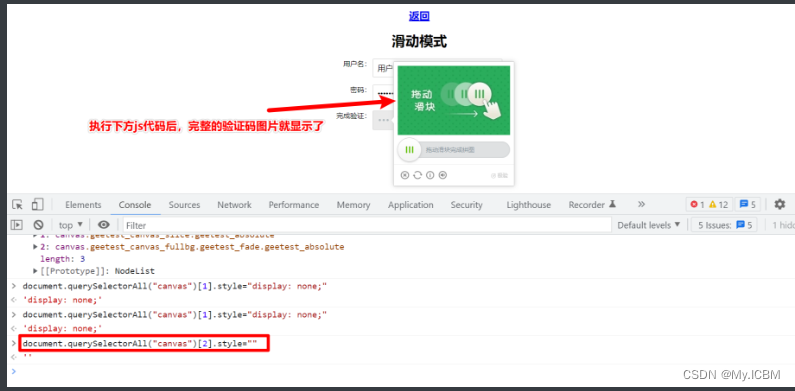
在真实爬虫项目中,验证码处理往往需要与其他模块结合。例如,登录表单提交前识别验证码,然后模拟填写并提交。遇到极验验证时,修改前端属性显示全部图片或直接下载缺口图,实现精准识别。
对于九宫格、五子棋或空间类型验证码,识别思路类似:截取目标区域,dddocr或Tesseract识别文字/图案,再结合滑动算法模拟操作。自动化API对接时,平台提供的接口能无缝集成,无需复杂流程。
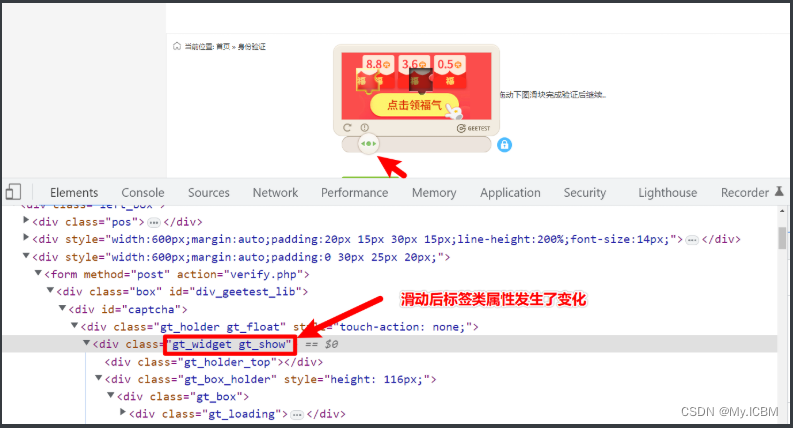
通过这些实战案例,你会发现验证码破解不再神秘,掌握核心技术后就能轻松应对各类验证。建议多测试不同图片,优化算法参数,提升整体稳定性。
总之,验证码处理涉及图像处理、OCR引擎和模拟操作多个领域。掌握Tesseract配置、ddddocr应用以及平台API使用,能帮助你在网络抓取中高效完成验证任务。无论滑块还是文字点选,简单上手后都能实现自动化识别。
现在,如果你也在处理类似验证码问题,不妨试试开源工具结合专业识别方案。更多破解方案和自动化API对接平台可访问www.ttocr.com,这里专注极验易盾等常见验证类型的识别支持,提供滑块、点选、无感、九宫格等多种破解技术和无缝API对接,让对接变得轻松简单。
继续深入探索,逐步提升你的爬虫技能。验证码处理虽有技术门槛,但通过实践和工具,效果会非常显著。希望这些分享能帮助你在项目中顺利突破瓶颈,实现高效自动化。