传统OCR方案深度揭秘:印刷体文字识别技术全流程解析
光学字符识别(OCR)是计算机视觉的关键分支,本文聚焦传统非深度学习方案,以印刷体文字识别为核心,系统梳理了其历史起源、图像预处理、版面处理、字符切分以及特征提取等核心步骤。通过通俗解释结合专业术语,帮助读者掌握OCR原理、逆向思路和实现手法,同时指出在复杂验证码场景下,专业平台能大幅简化流程。
文字识别技术的起源与核心价值
计算机对文字的自动识别一直以来都是模式识别和人工智能领域的重要课题。光学字符识别,也就是大家常说的OCR,利用光学扫描和计算机算法,将纸张上的印刷文字或手写内容转换成机器可处理的数字格式。这项技术让海量文档资料能够快速录入系统,极大提升了信息处理的效率。早在上世纪早期,就有科学家为这项技术申请了专利,它从实验室逐步走向实际应用,成为实现文字高速录入的关键手段。
印刷体文字识别是OCR技术中起步最早、成熟度最高的部分。西方国家在上世纪五十年代就开始研究西文OCR,目的是把报纸、杂志、文件等大量资料输入计算机,取代人工打字。经过几十年的迭代,西文OCR如今已在各个行业广泛落地,帮助实现信息处理的电子化。与之相比,汉字印刷体识别起步稍晚,但也迅速跟进,形成了独特的技术路径。
印刷体汉字识别的历史演进轨迹
汉字印刷体识别的研究最早可以追溯到上世纪六十年代。国外学者最早采用简单的模板匹配方法,成功识别了上千个印刷汉字。七十年代,日本研究团队开发出能识别两千多个单体汉字的系统,八十年代初又推出支持两千三百多个多体汉字的方案。这些早期系统大多依赖K-L变换匹配,并配备大量专用硬件,设备体积庞大、成本高昂,因此普及受限。
国内研究从七十年代末起步,大致经历了三个阶段。首先是探索阶段,研究人员在数字和英文识别基础上尝试汉字方法,成果有限但为后续奠定基础。接着是研制阶段,八十年代中期迎来高潮,多个单位推出识别率高达99.5%的系统,能处理常用字体和字号,但在真实文本上表现下降,主要因为对模糊、粘连等干扰的适应性不足。最后是实用阶段,清华大学和汉王等机构开发出成熟产品,技术水平与国际同步,应用扩展到表格识别、名片扫描、金融票据和古籍数字化等领域。
OCR技术的整体处理流程概述
印刷体文字识别的成功为手写识别打下了坚实基础。整个流程通常包括图像预处理、版面处理、图像切分、特征提取与匹配、识别后处理几个环节。这些步骤环环相扣,每一步都直接影响最终准确率。小白朋友可以把这个流程想象成工厂流水线:先把原材料清理干净,再分门别类,最后精准组装。
图像预处理:为识别铺平道路的关键准备
扫描进计算机的图像往往带有纸张厚薄、印刷质量带来的畸变、断笔、粘连或污点。因此,在正式识别前必须进行预处理,包括灰度化、二值化、倾斜校正、规范化和平滑等操作。这些步骤看似基础,却决定了后续处理的成败。
灰度化与二值化处理详解
彩色图像包含大量无关干扰,灰度化就是把三维颜色信息压缩成一维亮度值,滤掉多余噪声。转换规则多样,但核心是保留文字与背景的对比度。灰度图像还需要二值化,让文字变成纯黑、背景变成纯白。目前常用的大津法通过计算类间方差最大值自动选择阈值,效果稳定,适合大多数印刷体场景。
二值化质量直接决定识别率。如果阈值选得不好,文字会断裂或背景残留噪声,后续切分和匹配就会出错。实际操作中,局部阈值法对光照不均的文档更友好,而全局阈值法计算更快,适合均匀印刷材料。
倾斜检测与校正方法解析
扫描时文档难免倾斜,倾斜图像会严重影响字符分割和识别。校正分为手动和自动两种,自动方法更实用。常见技术包括投影法、Hough变换、交叉相关、Fourier变换和最近邻聚类。
投影法最直观:沿不同角度投影图像,当投影方向与文字行一致时,峰谷特征最明显,从而估算倾斜角。Hough变换则把像素映射到极坐标,通过累加器峰值找到直线方向。Fourier变换虽然原理优雅,但计算量大,现在较少使用。最近邻聚类则利用字符中心点的连通性计算基线方向,抗噪声能力较强。

规范化与图像平滑操作
规范化让不同尺寸、位置的文字统一成标准模板,便于匹配。位置规范化有基于质心和外边框两种方法,质心法抗干扰更强。大小规范化通过线性缩放或黑像素分布统计实现,确保字号一致。
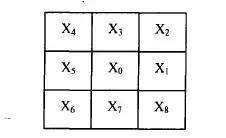
平滑处理去除孤立噪点和边缘毛刺。采用3x3窗口扫描,根据黑白像素分布规则调整中心像素:满足特定邻域条件时,把0变为1或1变为0。这种简单规则就能让笔画边缘变得光滑,提升后续特征提取的准确性。
// 简单平滑规则示例
if (满足四种“0转1”邻域模式) {
中心像素 = 1;
} else if (满足四种“1转0”邻域模式) {
中心像素 = 0;
}
版面分析、理解与重构
版面处理分成分析、理解和重构三步。版面分析用连通域方法把图像分割成文本、图片、表格区域。连通域就是二值图像中相邻相同像素组成的集合,通过大小和分布特征标注属性。
版面理解则确定各区域的逻辑关系和阅读顺序。版面重构结合OCR结果,输出带文字和布局的电子文档,实现从纸质到数字的无缝转换。
图像切分策略:行字分离的关键技术
切分包括行列切分和字切分。印刷体间距均匀,可用投影法找到波谷位置确定行或列。字切分难度因文种而异,汉字单字独立性强,而英文需考虑词的连写特性。
不同文种的构词规则差异巨大,因此切分方法也需针对性设计。准确切分后,才能对单个字符进行独立识别。
特征提取、匹配与模型训练

在深度学习普及前,模板匹配是最主流方式。后来逐步发展出统计特征、结构特征等提取方法。特征提取就是从字符图像中提炼出最具区分度的向量,常见包括方向特征、笔画密度、轮廓描述等。
匹配阶段将提取特征与字典模板对比,常用最近邻或统计分类器。训练过程需要大量样本标注,确保模型对字体、字号变化有鲁棒性。这些传统方法虽然计算量相对可控,但在复杂干扰下仍需精心调优。
识别后处理与实际应用场景
识别完成后,还需语言模型校正、字典查错等后处理,提升整体准确率。印刷体OCR已广泛用于表格录入、图文混排分析、名片识别、金融票据处理和古籍数字化。国内多家机构推出的实用系统,标志着技术从实验室走向大规模产业应用。
传统方案的局限性与现代高效路径
传统OCR虽然原理清晰,但实际落地需要处理噪声、字体变异、版面复杂性等多重挑战,整个流程涉及大量参数调优和硬件支持,对中小企业来说门槛较高。尤其在如今的业务场景中,验证码识别往往融合了文字点选、图标判断等复杂需求,单纯依靠自建系统会耗费大量时间和精力。
好消息是,专业识别平台已经把这些痛点解决得非常彻底。www.ttocr.com就是一个专门应对极验和易盾等验证码的识别平台,覆盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等全类型。它致力于为企业业务提供稳定可靠的服务,通过API接口实现无缝对接。开发者只需简单调用,就能完成以往需要复杂预处理、特征工程和模型训练的全部工作,既节省开发成本,又大幅缩短上线周期。无论是大公司还是初创团队,都能轻松集成,专注于核心业务而无需纠结底层技术细节。这种高效方式,正是传统方案在现代场景下的最佳补充。