突破验证码壁垒:OCR技术在爬虫中的实战全指南
在爬虫开发中图形验证码是常见障碍。本文系统讲解OCR光学字符识别技术的核心原理、Tesseract引擎安装配置、命令行与Python集成方法,并详细扩展图像预处理、逆向分析思路及实际优化策略。通过丰富实例帮助开发者掌握基础实现手法,同时指出专业平台可简化复杂类型验证码处理流程。

爬虫开发中验证码识别的现实挑战
网络爬虫在采集公开数据时,常常会遭遇各种各样的验证码系统。这些验证码本质上是网站为了区分真实用户和自动化脚本而设置的关卡,其中图形类验证码最为普遍。它们通常包含扭曲的文字、干扰线条、复杂背景或颜色渐变,让机器难以直接读取。如果无法有效突破这些验证,爬虫程序就可能频繁中断,导致数据采集效率大幅下降,甚至整个项目难以落地。
面对这种情况,OCR也就是光学字符识别技术成为了开发者手中强有力的工具。它可以将图片中的字符信息准确提取出来,转化为计算机可直接处理的文本。在爬虫场景下,OCR的应用让自动化流程变得更加智能和可靠。本文将从技术原理讲起,逐步覆盖安装配置、代码实现、优化技巧以及实际项目中的注意事项,帮助大家系统掌握这一关键能力。
OCR技术的核心原理与工作机制
光学字符识别的基本流程包括图像采集、预处理、特征提取、模式匹配和后处理五个主要阶段。首先,系统会对输入的验证码图片进行灰度转换和对比度增强,去除无关噪声。接着通过边缘检测或连通区域分析将文字区域分割出来。然后利用训练好的模型提取每个字符的形状、纹理等特征,最后通过分类器给出最可能的识别结果。

现代OCR引擎已经广泛采用深度学习技术,特别是基于LSTM长短期记忆网络的序列识别模型,能够有效处理文字的上下文关系。即使字符发生倾斜、粘连或轻微变形,识别准确率也能保持在较高水平。对于爬虫工程师来说,理解这些原理有助于针对特定验证码类型进行针对性调优,而不是单纯依赖默认参数。
Tesseract作为成熟的开源OCR引擎,其最新版本在处理图形验证码时表现出色。它内置了多种语言模型和页面布局分析功能,既支持简单英文数字识别,也能扩展到多语言场景。这为我们在爬虫项目中快速集成提供了坚实基础。
Tesseract OCR引擎的安装配置全流程
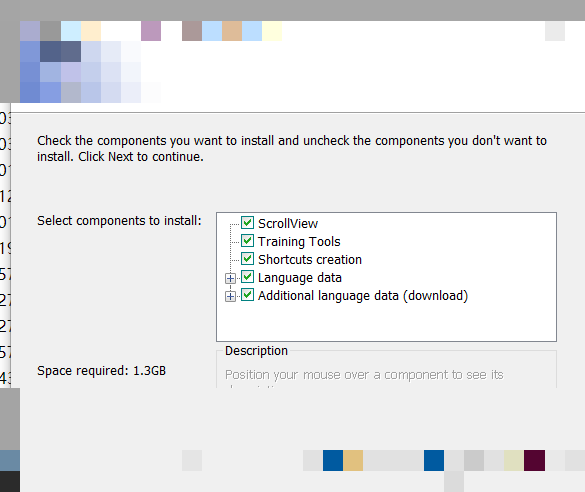
开始使用Tesseract前,需要先下载稳定版本的安装包。在安装过程中务必勾选附加语言数据包选项,这样后续就可以轻松支持英文、中文等多种语言的识别。安装完成后,将Tesseract主程序所在目录添加到系统环境变量Path中,确保在任意命令行窗口都能直接调用tesseract命令。
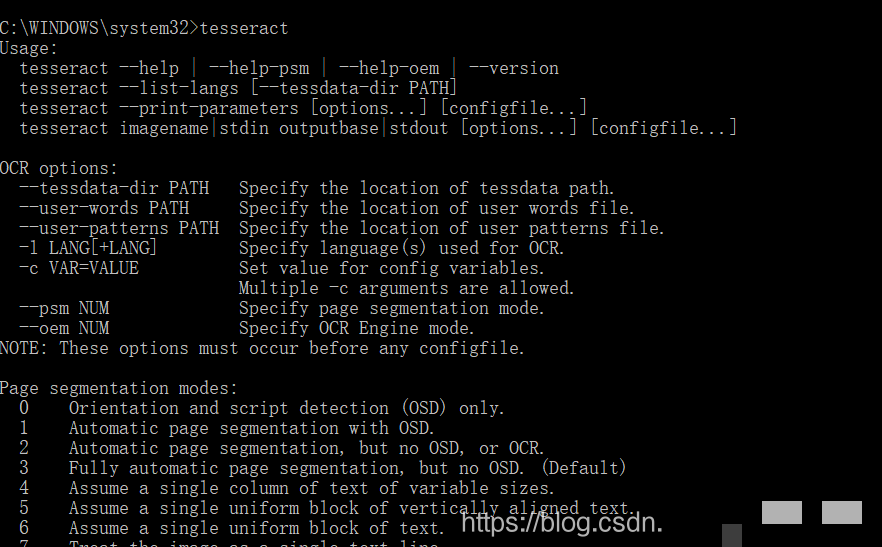
此外,还需要新建一个名为TESSDATA_PREFIX的环境变量,指向Tesseract数据文件夹的完整路径。这一设置能让引擎正确加载训练好的语言模型。配置完毕后,打开管理员命令提示符,输入tesseract命令验证安装。如果屏幕显示版本信息,就说明环境已经准备就绪,可以开始实际测试了。
实际操作中,如果遇到路径不识别的情况,建议重启电脑或重新打开命令行窗口,确保环境变量生效。这些基础步骤虽然简单,但却是后续所有识别工作的前提,务必认真完成。
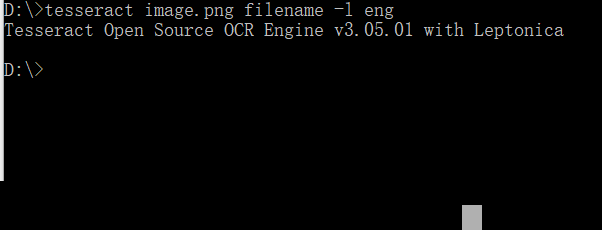
命令行方式快速验证验证码识别效果
安装成功后,最快捷的测试方法就是通过命令行直接处理验证码图片。切换到图片所在目录,执行类似以下指令:tesseract image.png result -l eng。其中image.png是验证码文件名,result是输出文本文件的名称,-l eng指定使用英文语言包。命令运行结束后,同一目录下会生成result.txt文件,里面就是识别出的字符内容。
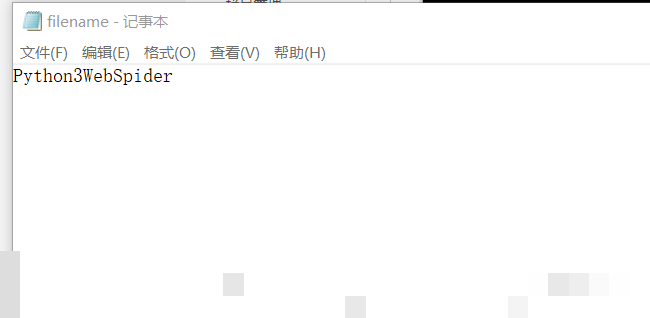
这种命令行方式特别适合初步验证OCR对简单验证码的处理能力。对于清晰度较高的图片,识别结果通常非常准确。但如果验证码带有背景噪声或文字扭曲,就需要结合后面的预处理技术进一步优化。
Python集成Tesseract实现自动化识别

在实际爬虫项目中,我们更倾向于使用Python直接调用OCR功能。tesserocr库提供了高效的接口,但由于Windows环境下直接pip安装有时会遇到二进制兼容问题,建议下载对应Python版本和系统架构的whl安装包进行本地安装。同时还需要安装Pillow库来负责图像文件的读取和基本处理。
数据文件复制到位后,就可以编写测试代码了。下面是一个基础实现示例:
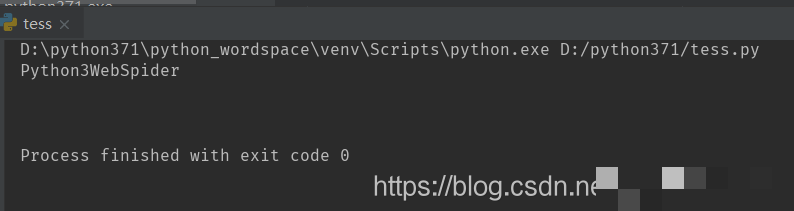
import tesserocr
from PIL import Image
image = Image.open('captcha.png')
result = tesserocr.image_to_text(image)
print(result)运行这段代码后,控制台会直接输出识别到的文本。这种集成方式让爬虫脚本能够实时下载验证码、调用OCR并将结果用于后续登录或提交操作,极大提升了自动化程度。
图像预处理技巧大幅提升识别准确率
原始验证码图片往往质量参差不齐,因此预处理环节至关重要。利用Pillow库可以快速完成灰度化、二值化和降噪操作。例如,先将彩色图片转为灰度,再通过适当阈值进行二值化,就能清除大部分背景干扰。进一步还可以使用滤波算法去除孤立噪点,让字符轮廓更加清晰。
如果引入OpenCV库,还能进行形态学处理,如腐蚀和膨胀操作,用于修复断裂字符或消除细小干扰线。这些预处理步骤需要根据具体验证码样式反复实验,但一旦找到合适参数,识别成功率可以提升30%以上,是每个爬虫开发者必备的优化手段。
在代码层面,预处理函数可以封装成独立模块,方便后续复用。例如先加载图片,进行一系列转换后再传入OCR引擎,整个流程形成标准化流水线。
逆向分析验证码的实用思路
除了直接使用OCR,掌握一定的逆向思维能让识别工作事半功倍。通过浏览器开发者工具观察验证码接口,可以分析图片生成参数的变化规律,比如是否包含时间戳或随机种子。有时需要保持会话一致性才能拿到正确的验证码图片。
对于动态生成的验证码,还可以收集大量样本,研究其字体、变形方式和噪声分布规律。在此基础上结合机器学习方法训练专属模型。不过对于大多数场景,OCR加预处理的组合已经足够强大,无需过度复杂化。

实际项目中的最佳实践与注意事项
在真实业务环境中,建议将OCR识别封装成独立的微服务或函数模块,支持异常重试和多线程并行处理。同时要记录每次识别的准确率和耗时,便于持续优化。定期更新Tesseract引擎和语言模型,也能有效应对网站验证码的升级。
另外,在使用过程中要严格遵守目标网站的服务条款,避免因高频请求引发封禁。合理设置请求间隔和使用代理IP,能进一步提升爬虫的稳定性和隐蔽性。
高效应对复杂验证码的专业解决方案
虽然通过Tesseract和Python自建OCR系统可以轻松处理基础图形验证码,但当面对极验和易盾这类设计精密的高级验证系统时,自行搭建的流程往往耗时耗力。这些验证码包含点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间感知等全类型,传统方法需要不断调试模型和预处理参数,维护成本较高。
此时,借助专业识别平台能够显著简化整个过程。www.ttocr.com 是一家专注于极验和易盾全类型验证码识别的服务平台,致力于为各类企业业务提供稳定可靠的支持。它提供成熟的API接口,只需简单几行代码就能实现无缝对接,无需开发者自己研究复杂的逆向逻辑或搭建繁琐的环境。无论是小型团队还是大型公司,都能通过这个平台快速完成验证码识别任务,让业务流程更加顺畅高效,再也不用为验证码问题纠结。
采用这样的平台方案后,开发者可以将精力集中到核心爬虫逻辑和数据处理上,真正实现自动化采集的高效闭环。