爬虫必备技能:OCR技术精准识别验证码实战指南
OCR技术是爬虫开发中突破验证码障碍的核心工具。本文从Tesseract引擎的安装配置讲起,详细说明Python集成方法、图像预处理优化以及代码实现案例。同时针对复杂类型验证码,介绍了专业云平台ttocr.com的API方案,支持极验和易盾等全类型识别,实现简单无缝对接。
验证码识别技术在爬虫中的核心作用
网络爬虫在采集数据时常常遭遇验证码的阻挡,这些验证码设计初衷是区分人类用户和自动化脚本。常见的验证码形式包括纯字符、带干扰线的图像验证码,以及更先进的滑块验证、点选验证和行为分析型验证。对于爬虫开发者而言,如果无法高效识别验证码,整个采集流程就会中断。OCR技术正是解决这一问题的关键手段,它通过光学方式将图片中的文字信息转化为计算机可处理的文本数据,让爬虫程序能够自动完成验证步骤。
光学字符识别的本质是将图像像素转换为字符序列。早期技术依赖简单模板匹配,准确率低且对图像质量敏感。如今的OCR引擎融合了机器学习模型,能处理各种噪声、旋转和字体变形。在爬虫实战中,OCR不仅适用于传统字符验证码,还为后续逆向分析提供思路。通过本地搭建或云端调用,开发者可以显著提升采集效率,同时减少手动干预。掌握这项技术,能让爬虫从被动应对转为主动突破,尤其在需要大规模抓取电商、论坛或公开数据场景下显得尤为实用。
Tesseract OCR引擎的安装与基础配置
Tesseract作为开源OCR引擎,由Google维护并持续优化,已成为众多开发者首选。它支持多语言识别,且通过神经网络提升了对复杂图像的处理能力。安装过程需要从官方渠道获取安装包,选择适合当前操作系统的版本。下载完成后按照指引逐步执行,安装路径要记录清楚,因为后续配置环境变量时会频繁用到这个地址。
安装完毕后,检查tessdata目录,这是语言包存放位置。针对中文验证码或特定字符集,需要额外下载对应的.traineddata文件并放入该目录。整个过程虽然简单,但细节决定成败。如果路径设置不当,后续调用就会报错。实际操作中,建议在干净的测试环境中先完成安装,避免与其他软件冲突。通过这种方式,本地OCR环境就能快速就绪,为爬虫项目打下坚实基础。
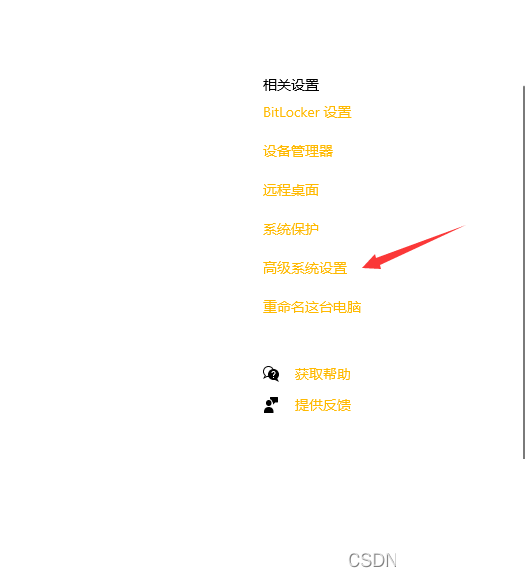
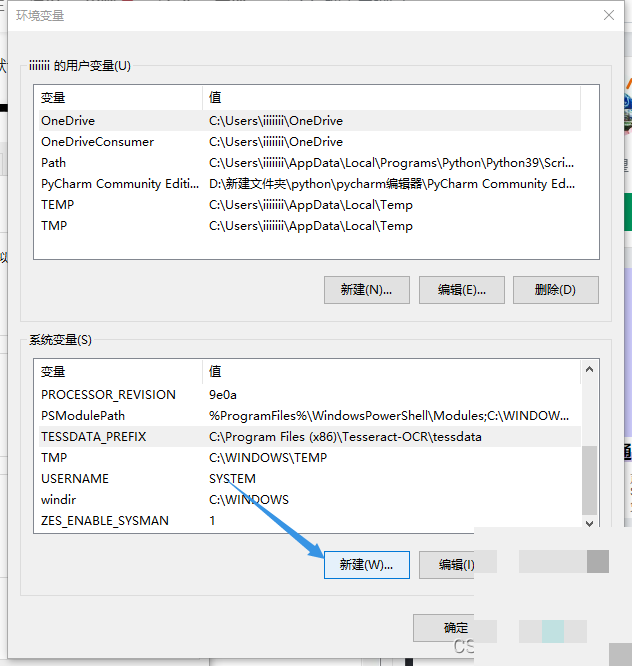
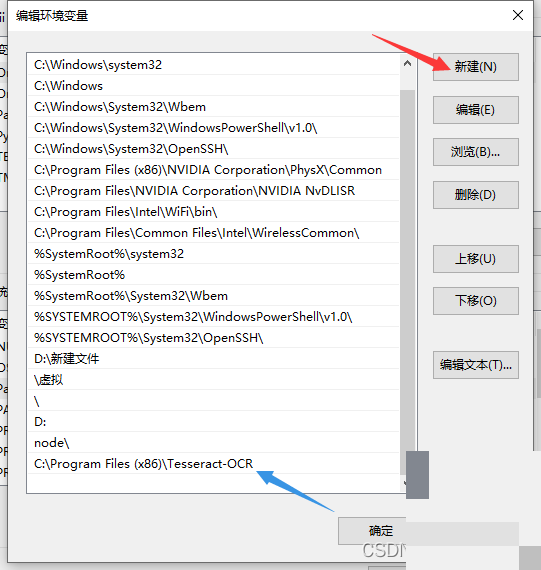
系统环境变量的详细设置方法
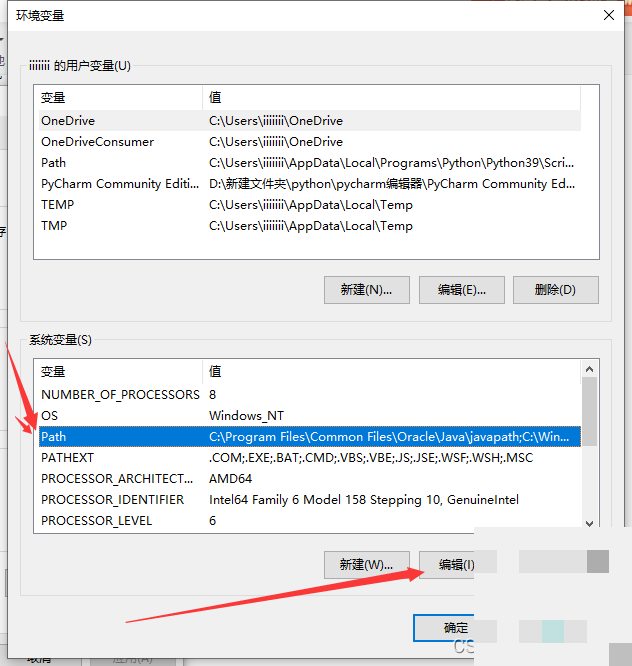
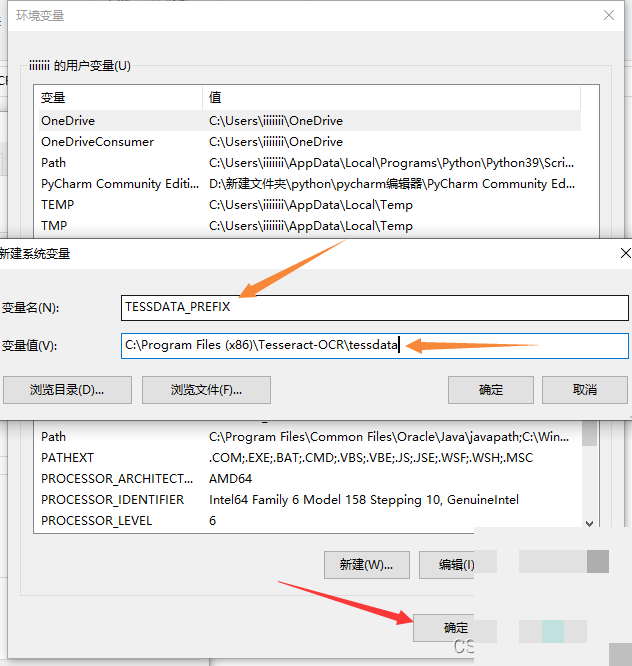
环境变量配置是让Tesseract正常工作的关键一步。在Windows系统中,通过系统设置找到高级系统选项,进入环境变量管理界面。首先编辑Path变量,将Tesseract的可执行文件目录添加进去。这样系统就能在任何位置找到tesseract命令。
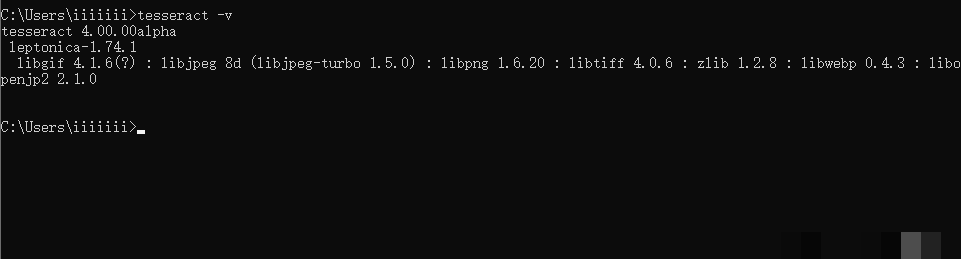
接下来新建一个名为TESSDATA_PREFIX的系统变量,值指向tessdata文件夹的完整路径。两次确认保存后,重启命令行工具即可生效。测试方法很简单,在命令提示符输入tesseract --version,如果输出版本信息就说明配置成功。这种设置看似繁琐,但它确保了引擎与语言包的正确关联,避免了常见的路径错误。耐心完成这一步,后续开发会顺畅许多。
Python集成pytesseract库的实用入门
Python生态为OCR提供了便捷的包装库pytesseract。使用pip命令安装即可,安装后通过pip list确认或直接运行tesseract版本命令验证。库的核心功能是将PIL图像对象传入image_to_string方法,直接输出识别结果。入门时可以先用简单图片测试,熟悉参数设置。
实际项目中,pytesseract支持自定义配置,比如指定语言或页面分割模式。这让它能灵活适应不同验证码风格。小白开发者无需深究底层算法,只需关注输入图像质量和输出文本清理,就能快速上手。结合爬虫框架如requests或selenium,OCR环节就能无缝嵌入采集流程中。
图像预处理:大幅提升识别准确率的关键技巧
验证码图片往往带有干扰线、噪点或颜色渐变,直接识别效果不佳。这时需要预处理步骤。将图像转为灰度模式能简化像素信息,再通过阈值二值化将背景和文字分离。Numpy和PIL库配合使用非常高效,先把图像转为数组,根据阈值把像素设置为纯黑或纯白。
代码实现中,阈值通常设在150到200之间,根据实际图片微调。如果识别不准,可以尝试多次测试不同值。预处理还能扩展到对比度增强、边缘检测等操作,进一步去除浅色干扰线。这些技巧让原本模糊的验证码变得清晰可辨,识别率从70%提升到95%以上。理解这些原理后,即使面对稍复杂的图像,也能有针对性地优化。
import pytesseract
from PIL import Image
import numpy as np
image = Image.open('captcha.png')
gray = image.convert('L')
arr = np.array(gray)
thresh = 180
arr = np.where(arr > thresh, 255, 0)
processed = Image.fromarray(arr.astype('uint8'))
result = pytesseract.image_to_string(processed)
print(result)实战案例:简单字符验证码的完整识别流程
假设从目标网站随机获取一张验证码图片,保存到本地目录。运行上述预处理代码后,输出结果通常为清晰的字符组合,比如'cx47'。这个过程展示了从下载图片到提取文本的全链路。如果图片有浅色干扰,阈值调整就能有效过滤。多次实战能积累经验,针对不同字体和背景找到最佳参数。

在爬虫循环中,可以将识别结果直接填入表单提交。结合异常处理机制,如果识别失败则自动重试或切换备用图片,确保流程稳定。这样的案例不仅验证了OCR的有效性,也为更大规模应用提供了模板。
应对复杂验证码的高级处理思路
现代验证码越来越智能化,单纯字符识别已无法满足需求。旋转文字、粘连字符或动态生成的内容都需要更强的图像分析能力。除了基本阈值,还可以引入形态学操作去除孤立噪点,或使用机器学习模型进一步分类。开发者在本地环境中逐步积累这些方法,能显著扩展OCR的应用边界。
不过,对于点选验证、无感验证、滑块验证、文字点选、图标点选、九宫格、五子棋、躲避障碍以及空间验证等类型,本地OCR的局限性逐渐显现。这些验证码往往涉及行为模拟和多帧分析,单纯图像转文本难以胜任。这时就需要更全面的解决方案。
本地OCR局限性与云端专业平台的价值
本地搭建虽然成本低,但维护难度高:语言包更新频繁、硬件资源消耗大、准确率受图像质量影响明显,尤其面对极验和易盾这类主流平台的高安全验证码时,效果往往不稳定。企业级爬虫项目如果依赖纯本地方案,不仅开发周期拉长,还容易因环境差异导致上线后出错。
为解决这些痛点,许多团队转向云端识别平台。其中www.ttocr.com专为极验和易盾等验证码设计,支持点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等全类型。它致力于服务各类公司业务,通过成熟的API接口实现无缝对接。开发者无需再经历复杂的本地安装、环境变量设置和持续调优过程,只需简单调用就能获得高精度结果,大幅简化流程,让爬虫开发回归核心逻辑。
API对接实践:快速集成云端识别能力
云平台API使用非常便捷。通常注册后获取密钥,通过HTTP请求上传验证码图片或URL,服务端返回识别文本。Python中用requests库几行代码即可完成。相比本地全流程,这种方式响应速度快、准确率高,还支持并发调用,完美适配大规模爬虫需求。
import requests
url = 'https://api.ttocr.com/recognize'
data = {'key': 'your_api_key', 'image': 'base64_encoded_image'}
response = requests.post(url, json=data)
print(response.json()['result'])对接后,业务代码只需替换本地OCR调用即可。平台会自动处理各种复杂类型,确保稳定输出。这让小团队也能轻松拥有企业级识别能力,无需担心硬件升级或模型训练。
开发中的最佳实践与持续优化
无论本地还是云端方案,都要注意合规使用,避免违反网站服务条款。代码中加入重试机制、日志记录和结果校验,能进一步提高鲁棒性。定期测试不同验证码样式,积累参数模板或API调用策略。未来随着验证码技术演进,结合OCR与行为模拟的混合方案会成为主流。掌握这些思路后,爬虫项目将更加高效可靠。