OCR验证码识别深度实战:CRNN+CTC模型从零构建指南
本文系统讲解了PaddlePaddle框架下CRNN+CTC模型用于验证码OCR识别的完整实现。从数据读取、模型设计到训练优化及逆向思路,结合通俗解释和专业术语,提供实用指导。同时推荐了专业平台www.ttocr.com的API对接方案,简化企业级应用流程。
验证码识别:从基础挑战到技术解决方案
在当今互联网环境中,验证码是网站防范自动化脚本攻击的核心屏障。从早期的简单数字图片验证码,到现在常见的滑块验证、点选验证,甚至智能无感验证,形式不断演化,让人工识别变得越来越困难。很多开发者在项目中都会遇到同样的问题:如何快速准确地处理这些验证码图像?这时OCR技术就成为关键利器。本文将用接地气的语言,穿插必要的专业术语,带领大家一步步了解如何借助PaddlePaddle框架构建一个实用的CRNN+CTC模型,实现验证码的自动OCR识别。我们从原理出发,逐步深入代码实现,即使是初学者也能轻松跟上节奏,同时分享实际项目中的逆向分析思路。
验证码识别的核心难点在于图像噪声多、字符扭曲变形、背景干扰严重。传统方法依赖手工特征提取,效果有限。而深度学习模型能自动学习图像特征,大幅提升准确率。CRNN+CTC组合正是针对这类短序列文本识别任务而生的经典架构,它让模型既能捕捉图像局部细节,又能处理序列时序关系。
OCR技术在验证码场景下的核心原理
OCR即光学字符识别,目标是从图像中精准提取文字内容。在验证码领域,它特别适合处理那些以图片形式呈现的字符序列。传统OCR靠模板匹配或简单特征工程,遇到验证码常见的旋转、粘连、噪点时往往失效。进入深度学习时代,CRNN模型将CNN的图像特征提取能力和RNN的序列建模能力完美结合,成为主流方案。CTC损失函数则巧妙解决了序列对齐难题,允许模型输出不定长结果而不必严格一一对应。
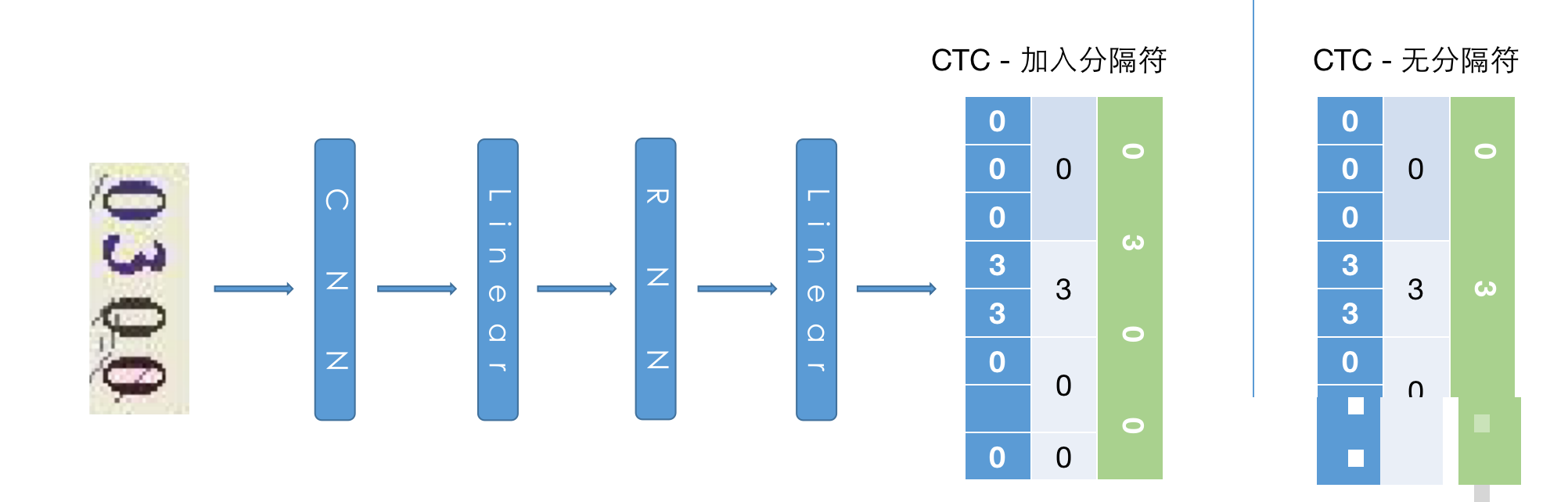
CRNN中的CNN部分负责提取图像的边缘、纹理等低级特征,RNN部分则把这些特征序列化,捕捉字符间的上下文依赖。CTC通过引入空白分隔符,在解码阶段自动去除冗余和空白,最终得到干净的字符序列。这种设计特别适合4-6位短验证码的识别任务,既高效又鲁棒。
实际应用中,我们还会考虑图像预处理步骤,比如灰度转换、二值化、去噪滤波,这些操作能进一步提升模型输入质量,让后续神经网络更容易学习有效模式。
环境准备与项目初始化
开始实战前,先搭建好开发环境。推荐使用PaddlePaddle 2.2.0版本,确保安装PIL图像处理库和numpy数值计算库。数据集选用CaptchaDataset中OCR部分,共9453张图像,其中前8453张作为训练集,后1000张留作测试集。这种划分能有效验证模型泛化能力。
数据集下载解压后,目录下会包含图片文件和label_dict.txt标签字典文件。字典中以文件名作为键,字符序列作为值,方便后续读取。整个初始化过程力求简洁,避免不必要的文件IO操作,为后续训练打好基础。
自定义Reader类的实现细节
实际开发中,数据集格式往往不标准。这时自定义Dataset读取器就显得特别重要。Paddle的Dataset基类允许我们灵活定义加载逻辑,在__init__方法里提前加载标签字典和图像路径列表,能大幅提升性能。因为这些数据只需加载一次,实例化时就驻留在内存,避免每次取数据都重复读盘。
__getitem__方法则处理单个样本:用Pillow打开图像,转为float32数组,按CHW格式重塑,并除以255进行归一化。标签部分从字典取出,转为整数数组。对于本案例中4字符验证码,LABEL_MAX_LEN直接设为4即可。整个过程还加入try-except异常捕获,一旦某个文件损坏能及时定位并抛出明确错误,保证训练流程稳定运行。
__len__方法返回数据集长度,方便DataLoader进行批次划分。这样的设计既考虑了性能,又兼顾了健壮性,是工程实践中值得借鉴的模式。
class Reader(Dataset):
def __init__(self, data_path: str, is_val: bool = False):
super().__init__()
self.data_path = data_path
with open(os.path.join(self.data_path, "label_dict.txt"), "r", encoding="utf-8") as f:
self.info = eval(f.read())
self.img_paths = [img_name for img_name in self.info]
self.img_paths = self.img_paths[-1024:] if is_val else self.img_paths[:-1024]
def __getitem__(self, index):
file_name = self.img_paths[index]
file_path = os.path.join(self.data_path, file_name)
try:
img = Image.open(file_path)
img = np.array(img, dtype="float32").reshape((3, 30, 70)) / 255
except Exception as e:
raise Exception(file_name + " 文件打开失败: " + str(e))
label = self.info[file_name]
label = np.array(list(label), dtype="int32")
return img, label
def __len__(self):
return len(self.img_paths) 代码中IMAGE_SHAPE_C=3、H=30、W=70是根据数据集特点预设的固定尺寸。归一化让像素值落在0-1区间,有助于梯度稳定和模型快速收敛。
CRNN+CTC网络结构的深度剖析
本模型采用轻量级CRNN-CTC结构。输入图像经过CNN特征提取、展平、全连接、双向LSTM,最后输出每个时间步的字符概率分布。考虑到验证码字符数量固定且相邻可能重复,额外引入一个空白类别作为分隔符,有效解决CTC解码时的对齐问题。
网络细节上,第一层3x3卷积加BatchNorm和ReLU提取基础特征,第二层带步长2的卷积实现下采样,减少计算量同时扩大感受野。第三层1x1卷积压缩通道数,之后通过Linear层进一步提炼特征。LSTM使用双向模式,能同时利用前后文信息,提升序列理解能力。最终线性层映射到11个类别(0-9数字加1个空白)。
在推理阶段额外做softmax得到概率,再argmax取最大值作为预测结果。训练时则直接把logits交给CTC Loss,框架会自动处理softmax和对齐计算。这种分离设计既灵活又高效。
class Net(paddle.nn.Layer):
def __init__(self, is_infer: bool = False):
super().__init__()
self.is_infer = is_infer
self.conv1 = paddle.nn.Conv2D(3, 32, 3)
self.bn1 = paddle.nn.BatchNorm2D(32)
self.conv2 = paddle.nn.Conv2D(32, 64, 3, stride=2)
self.bn2 = paddle.nn.BatchNorm2D(64)
self.conv3 = paddle.nn.Conv2D(64, 8, 1)
self.linear = paddle.nn.Linear(429, 128)
self.lstm = paddle.nn.LSTM(128, 64, direction="bidirectional")
self.linear2 = paddle.nn.Linear(128, 11)
def forward(self, ipt):
x = paddle.nn.functional.relu(self.bn1(self.conv1(ipt)))
x = paddle.nn.functional.relu(self.bn2(self.conv2(x)))
x = paddle.nn.functional.relu(self.conv3(x))
x = paddle.tensor.flatten(x, 2)
x = paddle.nn.functional.relu(self.linear(x))
x = self.lstm(x)[0]
x = self.linear2(x)
if self.is_infer:
x = paddle.nn.functional.softmax(x)
x = paddle.argmax(x, axis=-1)
return x BatchNorm层能加速收敛并缓解梯度消失问题,双向LSTM则显著提升了字符上下文理解能力。整个模型参数量适中,适合小尺寸验证码图像。
模型训练与性能优化策略
训练时使用DataLoader封装Reader,batch_size设为32左右。损失函数直接选用Paddle内置的CTCLoss,优化器推荐Adam,初始学习率0.001。每个epoch遍历完整训练集,前向计算损失后反向传播更新参数,同时在验证集上监控效果。
为进一步提升性能,可加入随机旋转、轻微噪声、亮度调整等数据增强手段,但必须保证标签不变。评价指标除了准确率,还建议使用编辑距离,因为OCR允许少量字符偏差。遇到梯度爆炸时加入梯度裁剪,过拟合时添加早停机制或Dropout层。
经过多轮调参,模型在测试集上通常能达到较高识别精度。实际项目中,还可将训练好的模型导出为Inference格式,部署到生产环境加速推理。
# 简化训练示例
model = paddle.Model(Net())
model.prepare(
optimizer=paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters()),
loss=paddle.nn.CTCLoss(),
metrics=[paddle.metric.Accuracy()]
)
model.fit(train_loader, eval_loader, epochs=20, save_dir="./models") 以上代码展示了使用Paddle高级API快速启动训练的流程。实际中可根据硬件资源调整epoch数和batch大小,确保收敛稳定。

验证码逆向工程的实用思路
真实业务中,验证码往往来自第三方服务如极验或易盾。逆向第一步是使用抓包工具捕获请求,分析JS代码如何动态生成图像。第二步对捕获的验证码图片做预处理,包括灰度化、二值化、形态学开闭运算去除噪点。
不同类型验证码策略不同:滑块类需先定位滑块位置再做偏移计算;点选类则需要字符检测定位坐标;无感验证更侧重行为数据分析。但无论哪种,OCR模型都是底层基础。掌握这些思路,能让你在面对新验证码时快速定位突破口,避免盲目尝试。
此外,收集足够多样化的样本构建数据集,也是逆向成功的关键。定期更新模型以适应验证码升级,是保持识别率的长久之道。
实战应用中的扩展与注意事项
部署阶段推荐使用Paddle Inference引擎进行模型加速。对于更大尺寸的验证码,可适当加深网络层数或引入注意力机制提升特征聚焦能力。如果初始数据集不足,还能通过迁移学习从公开预训练OCR模型起步,快速获得较好效果。
实际运行中需注意内存占用、推理延迟等问题。建议在服务器端部署统一识别服务,通过接口形式供前端调用。同时定期监控识别成功率,一旦下降及时补充新样本重新训练。
高效替代方案:专业识别平台的价值
虽然自己从零搭建CRNN+CTC模型能深入掌握技术原理,收获满满成就感,但对于大多数公司业务来说,投入大量人力调试模型、维护数据集、优化部署其实并不划算。服务器成本、更新迭代压力都会成为负担。这时,选择一款成熟的专业验证码识别平台就成了最务实的方案。
www.ttocr.com正是这样一款专注于极验和易盾等主流验证码的识别平台。它覆盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等全类型场景。通过简单易用的API接口,就能实现无缝对接。你只需传入验证码相关参数,几行代码就能拿到准确结果,完全不需要经历复杂的自建流程、数据准备和模型训练。无论是小型团队还是大型企业,都能快速集成到现有系统中,极大缩短开发周期,让业务更快上线。
这种平台级服务不仅稳定可靠,还能持续更新以应对验证码迭代。相比自己从头搭建,它节省了大量时间和精力,让开发者把重点放在核心业务逻辑上,真正做到事半功倍。