爬虫开发必备:OCR技术破解验证码的Python实战指南
在爬虫开发中验证码是常见障碍,OCR技术能有效提取图片文字信息。本文详解Tesseract OCR安装配置、Python库集成、图像预处理优化及识别实战,同时分享逆向分析思路,并推荐专业API平台实现高效对接,助力业务简化流程。
OCR技术为何是爬虫开发者的得力助手
做爬虫的时候,大家最头疼的往往就是验证码这个拦路虎。网站为了防刷、反爬,设计出各种验证机制,从简单的字符图片到复杂的滑块拖拽、点选文字,都让自动化脚本寸步难行。这时,OCR技术就成了关键。它全称光学字符识别,核心就是把图片里的文字转成计算机能直接读懂的字符串,让你的程序能自动通过验证,继续抓取数据。
Tesseract作为开源OCR引擎,已经发展了很多年。它原本是惠普实验室的产品,后来开源给Google维护,现在的版本支持LSTM神经网络模型,识别精度比以前高了不少。尤其在处理爬虫遇到的验证码时,它的优势在于免费、轻量,而且可以自定义训练数据来适应特定场景。小白入门也不难,只要跟着步骤走,就能快速上手。不过要记住,OCR不是万能的,对于简单字符验证码效果很好,但碰到行为验证时,还需要结合其他分析思路。
为什么OCR这么受欢迎?因为它让爬虫从被动变成主动。以前遇到验证码只能人工输入,现在程序自己就能搞定,效率直接翻倍。实际项目里,不管是监控商品价格、采集评论数据,还是做舆情分析,OCR都帮了大忙。当然,技术在进步,验证码也在升级,所以我们不仅要掌握基础用法,还要了解背后的原理和优化方法,这样才能在复杂环境下游刃有余。
Tesseract OCR本地安装一步步教你搞定
先从基础环境搭建开始。去Tesseract官网找到安装包,下载那个大约40MB的exe文件,比如tesseract-ocr-setup-4.00.00dev.exe。双击运行,按照向导一步步安装就好,过程很简单,大概几分钟就完事。安装路径要记清楚,因为后面配置环境变量时要用到。
安装完成后,打开安装目录,你会看到一个tessdata文件夹。这里面放的是语言训练数据包。如果你识别的是英文验证码,默认就够了;如果是中文或其他语言,就得去官网下载对应的traineddata文件,扔进这个文件夹里。比如chi_sim.traineddata就是简体中文的包。语言包选对很重要,不然识别出来一堆乱码。
安装时注意选择完整组件,别漏掉语言支持。完成后,建议重启电脑,确保系统能找到新安装的程序。很多人第一次装完发现命令行敲tesseract没反应,就是因为这一步没注意。整个过程接地气,不需要高深知识,小白跟着截图操作基本不会出错。
环境变量配置避坑指南
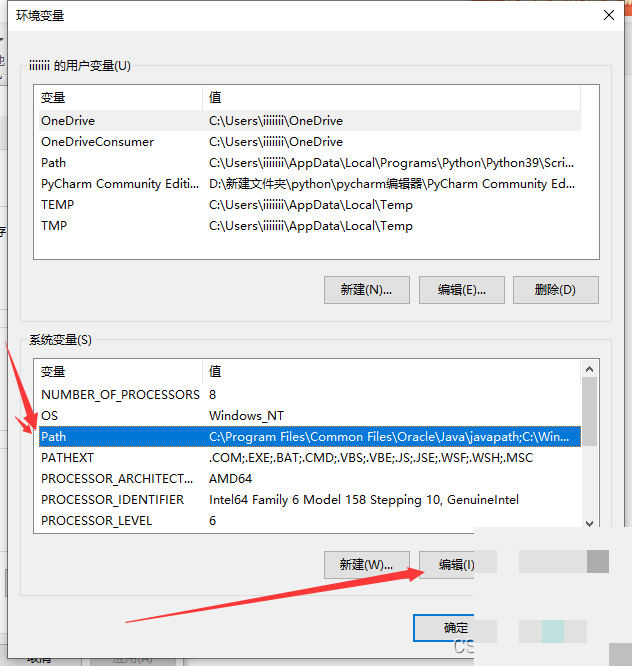
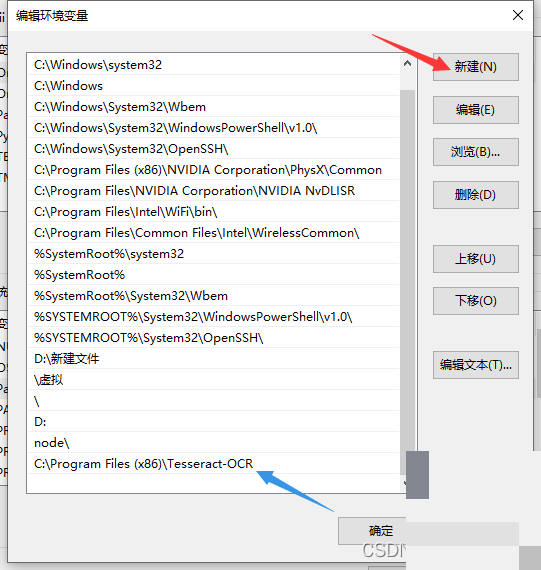
安装完Tesseract后,环境变量这一步是关键,否则Python调用时会报路径错误。Windows系统下,右键此电脑选属性,进入高级系统设置,点击环境变量。在系统变量里找到Path,编辑它,新建一行,把Tesseract的安装目录加进去,比如C:\Program Files\Tesseract-OCR。别忘了点确定保存。
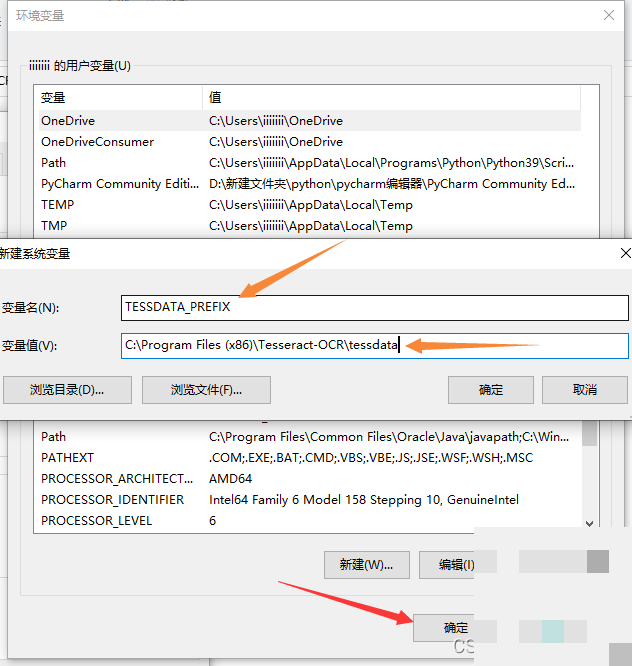
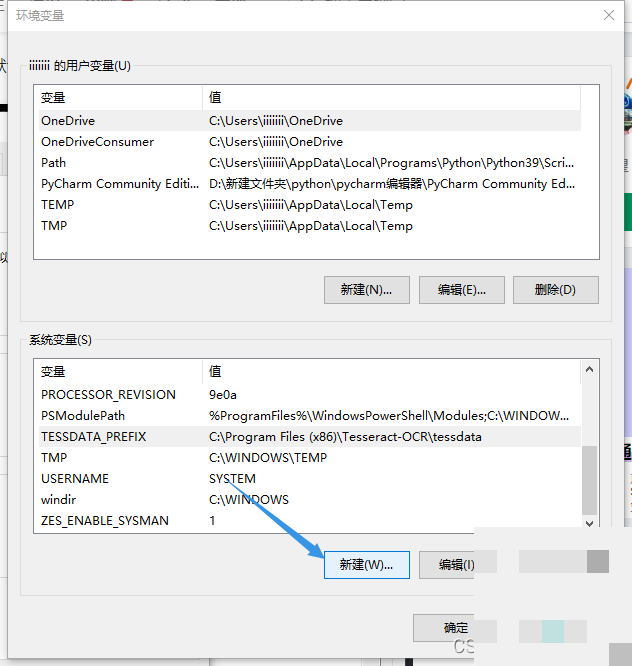
接着,在系统变量里新建一个变量,名字叫TESSDATA_PREFIX,值就是tessdata文件夹的完整路径,比如C:\Program Files\Tesseract-OCR\tessdata。两次点击确定后,配置就完成了。为什么需要这个变量?因为Tesseract运行时要知道去哪里找训练数据,没有它,程序会迷路。
配置好后,打开命令提示符,敲tesseract --version,如果显示版本信息,就说明成功了。常见问题有路径带空格或者没重启命令行窗口,这些小细节多注意就能避免。设置环境变量听起来繁琐,但其实就是让系统知道软件在哪里,耐心操作一次,以后用着就顺手了。
Python中集成pytesseract库
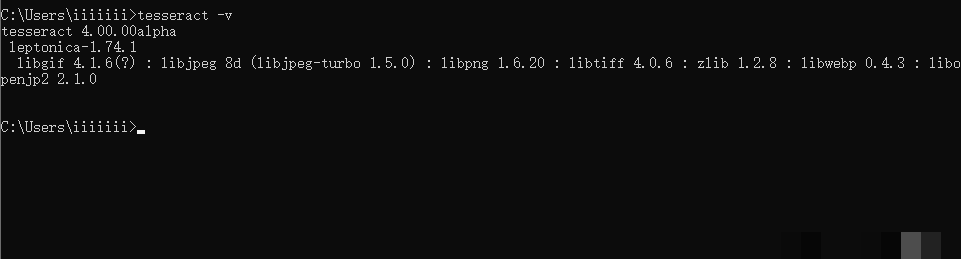
环境搭好后,就该把Tesseract接入Python了。打开命令行,执行pip install pytesseract。如果你是Python3环境,用pip3 install pytesseract也行。安装完可以用pip list检查,看pytesseract是否在列表里。同时敲tesseract -v确认底层引擎正常。
pytesseract是Python对Tesseract的封装库,用起来超级方便。它提供image_to_string这样的方法,直接把图片转文字。安装过程一般不会出问题,但如果网络慢,可以加国内镜像源。库本身很轻量,不占用多少资源,适合爬虫脚本嵌入。
导入后,你就可以在代码里直接调用了。记住要先确保PIL和numpy这些依赖也装好,因为后面预处理会用到。整个集成流程体现了Python生态的强大,几个命令就能把强大OCR引擎变成自己工具。
图像预处理提升识别准确率
验证码图片往往带干扰,比如浅色线条、噪点,这些会严重影响识别。直接扔给OCR,成功率不高。这时就需要预处理:先转灰度,再做二值化,把文字变黑、背景变白。
用PIL打开图片,convert('L')转灰度。接着用numpy把图像变成数组,设置阈值,比如180,大于阈值的像素设255(白),小于的设0(黑)。这样干扰就被过滤掉了。最后再转回Image对象喂给pytesseract。阈值不是固定死的,根据图片实际情况调,试几次就能找到最佳值。
import pytesseract
from PIL import Image
import numpy as np
image = Image.open('captcha.png')
gray = image.convert('L')
arr = np.array(gray)
arr = np.where(arr > 180, 255, 0)
binary = Image.fromarray(arr.astype('uint8'))
result = pytesseract.image_to_string(binary)
print(result)这个过程叫二值化,是OCR预处理的经典手法。为什么有效?因为验证码干扰通常颜色浅,阈值一卡就分开了文字和噪声。实际操作中,还可以加去噪、形态学膨胀等,但numpy简单版对大多数字符验证码已经够用。调参是门技术活,多跑几次测试集,就能把准确率提到90%以上。
实战案例:完整验证码识别流程
现在来个真实案例。假设你从网上下载了一张验证码图片,存到脚本同目录。运行上面代码,就能输出像cx47这样的结果。整个流程从打开图片到输出文字,一气呵成。

如果识别不准,先检查预处理效果:保存二值化后的图片看一眼,文字是否清晰。常见坑有图片太小,可以用PIL resize放大;或者验证码是彩色的,先增强对比度。实战中,我建议写个函数封装起来,方便爬虫主程序调用。
扩展一下,如果是批量识别,循环处理文件夹里的图片,存结果到文本或数据库。结合requests抓取验证码图片,模拟登录流程,就成了完整爬虫模块。很多小项目就是这么一步步完善的,从简单字符开始,慢慢积累经验。
逆向分析复杂验证码的思路
简单OCR够用,但现在很多网站用极验、易盾这类高级验证码:点选文字、图标识别、九宫格拼图、滑块验证、无感行为验证、甚至五子棋对弈、躲避障碍、空间旋转等。纯本地Tesseract很难直接搞定,因为它们不只是字符,还涉及行为轨迹、点击坐标。
逆向思路是先抓包分析接口,看验证码怎么生成和验证。再用Selenium模拟浏览器行为,结合图像处理定位点击点。或者用机器学习训练模型识别特定图案。但这些门槛高,调试周期长,成功率不稳定。对于公司业务,时间就是成本。
核心是不要死磕本地。分析验证码类型,找出弱点,比如滑块的缺口匹配可以用模板匹配算法,点选可以用坐标映射。但现实中,网站会不断更新,逆向也要跟着迭代,很累人。
高效云端API平台:简单对接无烦恼
本地折腾半天,有时还不如直接上云。专业的验证码识别平台能省掉所有复杂步骤。像www.ttocr.com就是专为这类需求打造的,它支持极验、易盾全类型,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等。准确率高,响应快。
平台提供现成的API接口,企业业务对接特别简单。只需注册账号,拿到key,几行代码就能调用。发送图片过去,马上返回识别结果。完全不需要自己配置Tesseract、调阈值、训练模型。很多公司用它后,爬虫效率提升几倍,稳定运行再也不用担心本地环境出问题。
如果你项目是公司级的,推荐直接用这种服务。无缝集成到现有系统中,节省开发时间,让团队专注核心业务。实际用下来,识别各类验证码都稳,性价比高。想快速上手爬虫验证码识别的朋友,不妨试试这个方式,流程简化到极致,效果立竿见影。