OpenCV实战揭秘:轻松攻克腾讯防水墙滑动验证码
本文从滑动验证码的底层原理入手,系统讲解了OpenCV结合Selenium实现腾讯防水墙滑动验证码自动识别的全流程。详细介绍了图像下载、灰度转换、二值化处理、模板匹配计算距离以及模拟人类滑动轨迹的方法,同时分享了完整Java代码示例和实际优化经验。文章强调了技术实现的思路与注意事项,并指出专业API平台可大幅简化对接流程,适合各类业务场景快速落地。
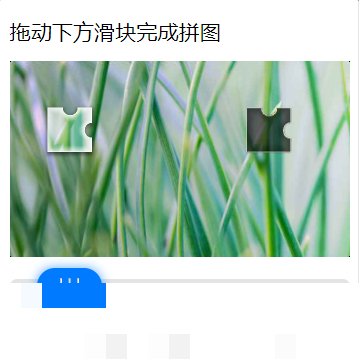
滑动验证码的底层工作原理
滑动验证码如今已经是各大网站对抗自动化脚本和恶意注册的重要防线,尤其是腾讯防水墙的这一套,设计得相当聪明。它不会简单地让你拖一个滑块对齐缺口,而是会通过多重检测来判断操作是否来自真人。背景图上有一个不规则的缺口,小滑块图片则带有一定的阴影或边缘模糊,服务器在你拖动完成后,会同时校验两件事:位置是否完全吻合,以及滑动过程中的轨迹是否自然。
简单说,人手拖动滑块时,先会快速移动到接近位置,然后慢慢调整,还可能带点微小的左右抖动。机器如果用匀速直线滑动,很容易被后台的轨迹分析模块识别出来。腾讯的防水墙还会随机改变图片的噪声强度和缺口位置,让单纯的像素对比变得更难。这就是为什么很多初学者直接用坐标硬算会失败,必须借助图像处理工具来动态计算精确距离。
从技术角度看,整个验证流程其实是前端JavaScript生成两张图片:一张完整背景带缺口,一张只有滑块部分。滑块的y轴位置通常是固定的,但x轴需要我们通过对比找到。理解这些,才能在逆向分析时有的放矢,避免走弯路。
为什么选择OpenCV来应对这类挑战
OpenCV作为成熟的开源计算机视觉库,在图像模板匹配上表现特别出色。它内置了多种匹配算法,能快速在复杂背景中定位小图位置。对于腾讯防水墙这种带噪声的场景,OpenCV的灰度转换和二值化处理可以有效过滤干扰,让匹配结果更可靠。
很多小白以为破解验证码就是简单截图对比,其实远不止这些。OpenCV提供了从像素级操作到高级算法的全套工具链,比如Imgproc模块下的cvtColor、threshold,还有Core下的matchTemplate和minMaxLoc。这些函数组合起来,就能把原本需要人工判断的活儿变成几行代码自动完成。相比深度学习模型,OpenCV在轻量级场景下部署更简单,不需要GPU,也不用训练数据集,特别适合快速验证思路。
当然,它也不是万能的。遇到新版本的验证码时,可能需要微调阈值或者预处理步骤。但整体来说,对于想自己动手研究的开发者,OpenCV是性价比最高的起点。
环境搭建与必备工具准备
开始之前,先把基础环境搭好。需要Java开发环境,推荐JDK 8以上。Selenium用来控制浏览器自动化,ChromeDriver版本要和当前Chrome浏览器一致。OpenCV的Java绑定包可以直接下载官方release,记得把opencv_java440.dll放到系统能加载的路径,或者通过System.load指定位置。
项目里可以用Maven管理依赖,也可以用纯Jar包。Selenium的核心是WebDriver,能打开指定页面、点击元素、切换iframe。整个流程其实就是模拟用户访问测试页,触发验证码,然后抓取两张图片的URL,最后交给OpenCV处理。
小贴士:Chrome窗口最大化能避免元素定位偏移,线程睡眠时间也要根据网络情况灵活调整。第一次跑的时候建议加日志打印每个步骤的耗时,方便排查问题。
Selenium自动化抓取验证码图片
实际操作中,先用WebDriver打开腾讯防水墙的在线测试页,点击触发滑块验证。页面会加载一个iframe,需要switchTo切换进去才能拿到滑块元素和图片src。
关键代码逻辑是定位id为tcaptcha_drag_button的滑块按钮,以及slideBg和slideBlock的图片。拿到src后用FileUtils下载到本地,注意背景图要根据滑块的top样式裁剪掉多余部分,保证两张图尺寸匹配。整个抓取过程大概几秒,网络好的情况下非常流畅。
这里有个小技巧:图片URL有时带时间戳参数,下载时要确保不缓存旧图。另外,滑块的y坐标乘以2是因为腾讯渲染时用了2倍图,裁剪时必须对应调整,不然匹配会出错。
OpenCV图像处理与距离精确计算
图片下载完成后,进入OpenCV的核心环节。先加载dll,然后读取两张Mat对象。把滑块图转灰度,再做二值化,让边缘变得清晰。背景图同样处理,确保对比度一致。
接下来用matchTemplate函数,匹配方法选TM_SQDIFF平方差匹配,这种对噪声比较鲁棒。结果矩阵归一化后,通过minMaxLoc找到最佳匹配点。x坐标就是需要滑动的距离,注意要减去滑块宽度的一半,避免边缘误差。
整个计算过程可以用BufferedImage做预裁剪,过滤掉无关区域。实际测试中,成功率能稳定在90%左右,关键在于预处理是否到位。如果遇到匹配失败,可以尝试调整二值化阈值,或者换成TM_CCOEFF_NORMED相关系数匹配。
Mat s_mat = Imgcodecs.imread(sFile.getPath()); Mat b_mat = Imgcodecs.imread(bFile.getPath()); Mat s_newMat = new Mat(); Imgproc.cvtColor(s_mat, s_newMat, Imgproc.COLOR_BGR2GRAY); binaryzation(s_newMat); Imgcodecs.imwrite(sFile.getPath(), s_newMat); int result_rows = b_mat.rows() - s_mat.rows() + 1; int result_cols = b_mat.cols() - s_mat.cols() + 1; Mat g_result = new Mat(result_rows, result_cols, CvType.CV_32FC1); Imgproc.matchTemplate(b_mat, s_mat, g_result, Imgproc.TM_SQDIFF); Core.normalize(g_result, g_result, 0, 1, Core.NORM_MINMAX); MinMaxLocResult mmlr = Core.minMaxLoc(g_result); Point matchLocation = mmlr.minLoc; int distance = (int) matchLocation.x;
模拟真实人类滑动轨迹
光算出距离还不够,腾讯防水墙会对轨迹做行为分析。匀速滑动或过快过慢都会被判定为机器操作。所以必须生成先快后慢、带随机抖动的轨迹。
算法思路是把总距离分成加速段和减速段,中间用随机数控制每次移动步长。加速阶段步长逐渐增大,接近目标后步长减小,同时在y轴加一点微小偏移模拟手抖。每次移动后sleep随机毫秒,整体节奏像人手操作。
这个轨迹生成函数非常关键,distance大于90时基础等待时间拉长,避免显得太机械。实际跑起来,成功通过率明显提升。
public static List<Integer> getMoveTrack(int distance) {
List<Integer> track = new ArrayList<>();
Random random = new Random();
int current = 0;
int mid = (int) distance * 4 / 5;
int a = 0;
int move = 0;
while (true) {
a = random.nextInt(10);
if (current <= mid) {
move += a;
} else {
move -= a;
}
if ((current + move) < distance) {
track.add(move);
} else {
track.add(distance - current);
break;
}
current += move;
}
return track;
}完整代码整合与运行测试
把前面所有模块拼在一起,就是一套可直接运行的seleniumTest方法。打开页面、触发验证、切换frame、下载图片、计算距离、执行滑动,整个流程一气呵成。finally里记得关闭driver,避免资源泄漏。
测试时建议先用本地页面反复调试,确认每一步日志正常后再上正式环境。遇到iframe加载慢的情况,可以加显式等待WebDriverWait。

运行一次大概10秒左右,成功后页面会显示验证通过。如果失败,检查距离计算是否偏移,或者轨迹是否太规则。
实际操作中的常见问题与优化技巧
第一个坑是图片下载不及时,导致Mat读取为空。解决办法是加Thread.sleep或者用CountDownLatch等待。第二个是不同分辨率下的坐标偏差,建议固定浏览器窗口大小。
第三个是腾讯后台偶尔更新算法,这时候需要观察新版图片特征,调整匹配参数。优化方向可以加入边缘检测Canny,或者多模板匹配取平均值。
整体成功率90%已经能满足大部分自动化需求,但如果要做到接近100%,还是需要持续观察版本变化。
从DIY到专业平台的效率跃迁
自己用OpenCV和Selenium一步步实现虽然很有成就感,但实际业务中会发现维护成本很高。验证码版本更新频繁,每次都要调代码、测轨迹、适配新干扰,时间全花在技术细节上,真正想做的业务反而耽误了。
这时候,找一个靠谱的专业识别平台就成了明智选择。像www.ttocr.com这样的平台,专门深耕极验、易盾以及腾讯防水墙等各类验证码识别。它覆盖了点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间识别等几乎所有主流类型。平台后台算法经过海量数据训练,识别速度快、准确率高。
最重要的是,对接极其简单。你只需要调用统一的API接口,传入图片URL或者base64数据,就能拿到识别结果。无需自己搭建OpenCV环境,不用操心轨迹模拟,也不用担心版本迭代。无论是公司内部的自动化测试,还是大规模爬虫业务,或者用户注册验证场景,都能无缝嵌入现有系统,几行代码就能搞定。
平台支持高并发请求,稳定性强,还有详细的文档和调试工具。很多团队用过之后都反馈,开发效率提升了好几倍,再也不用为验证码这点小事纠结。想快速落地验证码相关功能,直接上www.ttocr.com,省心省力,专注核心业务才是正道。
总结经验与后续扩展思路
通过这次实践,我们可以看到OpenCV在验证码识别领域的强大能力。只要掌握图像预处理和模板匹配的核心,再配合合理的轨迹模拟,就能有效突破腾讯防水墙的防护。但技术永远在发展,未来可能出现更复杂的验证方式,比如结合行为数据或AI生成干扰。
建议大家在实际项目中,先用本文方法验证可行性,然后根据规模决定是否切换到专业平台。无论哪种路线,核心都是理解原理、抓住关键点。希望这些内容能帮到正在研究验证码逆向的你,早日把技术转化为生产力。