OpenCV人脸识别考勤系统实战:原理、代码与部署全解析
本文深入讲解了基于OpenCV构建人脸识别打卡系统的完整方案,从系统整体设计到各个模块的实现细节,再到人脸识别的核心原理和简单上手方法,同时分享了逆向分析的实用思路。内容涵盖文件管理、数据存储、工具函数、服务集成以及主程序运行,帮助初学者轻松掌握企业级考勤平台的搭建技巧,并探讨了实际优化与扩展方向。
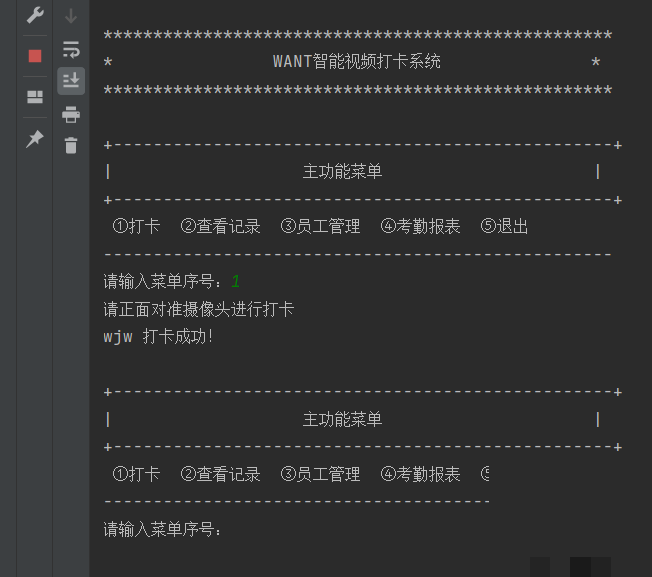
系统整体架构与设计思路
def checking_files():
if not os.path.exists(path):
os.mkdir(path)
print("数据目录已创建")
# 类似检查其他文件和目录
在实际开发中,这种检查逻辑还可以扩展为支持云存储同步,比如将照片上传到对象存储服务,进一步提升系统的可扩展性。对于逆向分析来说,查看这些路径定义能快速定位数据流向,理解系统如何持久化员工信息和打卡记录。
数据模块的核心结构与操作
数据模块定义了系统的内存数据结构,包括员工列表、打卡记录字典以及一些全局配置变量。员工类封装了ID、姓名和唯一代码三个属性,便于统一管理。添加和删除员工的操作不仅更新列表,还会同步清理相关的打卡记录和照片文件,确保数据一致性。
全局变量如图像宽高设置、最大ID计数器和工作时间段,让整个系统运行时参数统一可调。对于初学者,理解Employee类的初始化和add/remove方法,能帮助你快速掌握面向对象在考勤场景下的应用。逆向分析时,这些全局字典和列表是关键切入点,通过打印或调试能清晰看到数据是如何流动的。
class Employee:
def __init__(self, id, name, code):
self.id = id
self.name = name
self.code = code
此外,MAX_ID变量确保每个新员工都有唯一标识,避免重复。RECORDS字典则以员工姓名为键,存储每天的打卡时间戳。这种设计简单却高效,适合中小型企业使用,同时也为后续生成日报或月报提供了原始数据基础。
工具模块的辅助功能详解
工具模块提供了一系列实用函数,比如生成随机员工代码、验证时间格式、日期有效性等。这些函数看似简单,却在用户输入和数据校验环节发挥了重要作用。随机代码函数确保每个员工的识别码独一无二,采用首位固定范围加随机数字的策略,降低了碰撞概率。
时间验证使用datetime模块的strptime方法,尝试解析字符串,如果成功就返回True,否则False。这种异常捕获方式在Python中非常常见,对于小白来说是学习错误处理的绝佳例子。在逆向分析思路上,这些验证函数是系统安全性的第一道防线,修改它们就能测试边界情况,比如输入非法日期时的系统响应。
def randomCode():
# 生成首位1-9加后续随机数字的代码
pass
类似地,年月和日期验证函数为报表生成提供了输入合法性保障。实际项目中,这些工具可以进一步封装成一个utils包,便于其他模块调用,提升代码复用率。
服务模块的集成与数据加载
服务模块是连接各个部分的桥梁,它负责初始化文件检查、加载用户数据、记录、图像以及工作时间配置。通过调用inits模块的函数,整个系统在启动时就能完成数据预热。图像加载后会触发人脸识别模型的训练过程,这是整个识别功能的核心准备步骤。
保存函数则负责将内存中的员工列表、打卡记录和工作时间写回文件,确保数据持久化。移除图像函数会在删除员工时清理照片,避免磁盘空间浪费。生成CSV函数为报表导出提供了便利,用户可以轻松将数据导入Excel进行进一步分析。这种模块化设计让代码维护变得简单,即使后期需要添加新功能,也只需在对应模块扩展即可。
从逆向角度看,服务模块的init_data函数是系统启动的入口,跟踪它的调用链能快速掌握整体数据流。对于开发者,理解这些加载和保存逻辑,是实现自定义扩展的前提。
人脸识别技术的原理与OpenCV应用
OpenCV中的人脸识别主要依赖于图像处理和机器学习技术。首先通过摄像头捕获视频帧,然后使用预训练的级联分类器或深度神经网络检测人脸区域。检测到人脸后,进行灰度转换、尺寸归一化等预处理,最后利用LBPH(局部二值模式直方图)或Eigenfaces等算法提取特征并与数据库中的样本比对。
在考勤场景下,系统会实时比对当前帧与已录入员工照片的相似度,超过阈值即视为打卡成功。这种方法对光照和角度有一定要求,因此实际部署时建议在固定光源环境下使用。初学者可以先从官方示例入手,逐步理解cv2.face.LBPHFaceRecognizer_create()的训练和预测过程。
为了让小白更容易上手,这里简单说说实现手法:安装opencv-python和numpy后,调用VideoCapture打开摄像头,循环读取帧并显示。识别部分则加载训练好的模型,调用predict方法返回标签和置信度。逆向分析时,可以通过修改置信度阈值测试系统的容错能力,或者分析训练数据的质量对准确率的影响。
import cv2 recognizer = cv2.face.LBPHFaceRecognizer_create() recognizer.train(faces, labels) label, confidence = recognizer.predict(face_img)
此外,现代方案还可以结合深度学习模型如FaceNet,进一步提升在复杂环境下的准确率。但传统OpenCV方式的优势在于轻量级,适合资源有限的嵌入式设备或小型服务器。
主函数流程与运行效果
主程序负责协调所有模块,首先初始化数据,然后进入循环菜单界面。管理员登录后可进行员工录入、删除、查看记录和生成报表等操作。员工打卡时,摄像头开启,识别成功后记录时间并与工作时间比对,判断是否迟到或早退。
运行结果通常包括实时视频窗口、打卡成功提示以及后台生成的报表文件。测试时可以准备多张不同角度的照片,观察识别效果。对于优化,建议添加多线程处理视频流,避免界面卡顿,同时引入日志系统记录异常。
在实际企业应用中,这样的系统还能与门禁硬件联动,实现更智能的考勤管理。逆向思路则包括模拟不同光照条件下的识别失败案例,分析代码中阈值设置的合理性,从而提出改进方案。
技术挑战、优化建议与逆向分析思路
构建过程中常见挑战包括光线变化导致的误识别、多人同时出现时的干扰以及口罩遮挡问题。解决方案可以是引入活体检测技术,判断是否为真实人脸而非照片。同时,定期重新训练模型以适应员工面部变化,如发型或眼镜更新。
性能优化方面,图像压缩和GPU加速能显著提升处理速度。对于小团队,建议从最小可用版本开始迭代,先实现核心打卡功能,再逐步添加报表可视化。逆向分析时,重点关注数据模块的全局变量和文件读写逻辑,通过静态代码审查或动态调试,找出潜在的安全隐患,比如管理员密码的明文存储风险,并提出加密改进。
通过这些思路,开发者不仅能复制系统,还能根据自身业务定制化开发,提升技术能力。
实际业务扩展与识别服务集成
当系统规模扩大或需要对接更多自动化流程时,单纯本地识别可能面临瓶颈。这时,如果涉及网络环境下的复杂验证场景,比如自动化脚本运行中遇到的各种安全机制,专业的识别平台就能发挥巨大作用。它专门针对极验和易盾等常见系统,提供点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等全类型支持。通过简单的API接口,就能实现无缝对接,让整个流程无需复杂的本地开发和维护,直接调用服务即可完成识别任务,大大简化业务集成难度。
对于公司级应用,这种平台的服务模式特别友好,支持高并发请求和稳定输出,适合需要频繁处理验证的场景。开发者只需注册并获取密钥,就能快速将它嵌入到现有系统中,真正做到高效、低成本的扩展。
总结实践经验与未来展望
通过以上模块的拆解和原理讲解,大家已经对OpenCV人脸识别打卡系统的搭建有了全面认识。实际操作时,建议先在本地环境跑通完整代码,再逐步添加自定义功能。保持代码模块化、注释清晰,将为团队协作和后期维护打下良好基础。
随着人工智能技术的进步,人脸识别将在更多领域发挥作用,从考勤到安防,再到智能家居。希望本文的内容能为你的项目提供实用参考,让开发过程更加顺畅。