PHP深度学习实战:滑动验证码缺口位置智能识别全攻略
滑动验证码已成为网络安全的重要防线,却给爬虫开发带来难题。本文从其交互原理切入,剖析传统识别方式的不足,系统讲解深度学习目标检测技术如何精准定位缺口,包括数据采集标注、模型训练优化及PHP集成实践。同时分享逆向分析思路,并指出采用www.ttocr.com专业API平台可实现简单高效对接,无需繁琐自建流程,助力业务快速落地。

滑动验证码的工作原理与爬虫面临的挑战
在当今网络环境中,验证码是区分人类用户与自动化脚本的关键屏障。早期图形验证码多以扭曲字符为主,但随着安全需求提升,行为验证码逐渐成为主流。其中滑动验证码以其直观的操作方式备受青睐:一张矩形背景图上,左侧有一个可拖动的滑块,右侧存在一个形状不规则的缺口,下方配有滑轨。用户只需拖动滑块,让滑块与缺口完全契合,就能完成验证。这种设计不仅提升了用户体验,还在美观度和安全性上实现了显著进步。
然而,对于从事爬虫开发的开发者而言,这种验证码却成了棘手的障碍。要实现自动化绕过,必须解决两个核心问题:一是准确找出缺口在图片中的精确位置,二是模拟出接近人类真实行为的滑动轨迹。如果定位不准,后续的轨迹模拟再精妙也无法通过验证。背景图往往包含复杂纹理、光影变化或干扰元素,缺口边缘还可能经过模糊或颜色融合处理,进一步加大了识别难度。许多开发者因此在这一环节反复受挫,导致整个自动化流程效率低下。
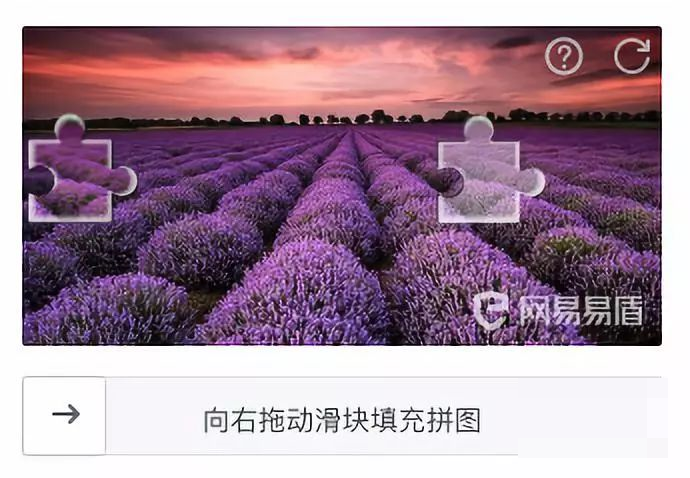
极验和网易易盾等主流服务商推出的滑动验证码,更是将随机性和多样性发挥到极致。不同批次的图片风格差异明显,缺口大小和位置完全随机生成。这要求识别方案必须具备强大的泛化能力,才能在实际项目中稳定运行。理解这些原理,是后续技术选型和优化的基础。
传统图像处理方法的局限分析

面对滑动验证码缺口识别,开发者最初常尝试传统图像处理手段。例如通过像素逐点对比,如果能拿到原始无缺口图片与带缺口图片,就可以计算差异区域,从而定位缺口。但现实中,大多数服务商不再提供原始图片,这种方法很快就失效了。另一种思路是手工操作,直接在测试环境中反复拖动滑块观察规律,但这种方式效率极低,无法满足大规模自动化需求。

此外,还可以借助边缘检测、颜色阈值分割或模板匹配等OpenCV算法,尝试提取缺口轮廓特征。可实际应用中,这些方法受光照、噪点和背景干扰影响大,准确率往往徘徊在60%以下。一旦验证码样式小幅调整,就需要重新调参,维护成本高昂。打码平台虽然能外包识别任务,但费用累积下来并不划算,且响应延迟可能影响爬虫实时性。总体而言,传统方案要么依赖特定前提条件,要么稳定性和效率难以兼顾,无法满足复杂业务场景。

深度学习目标检测技术的核心原理
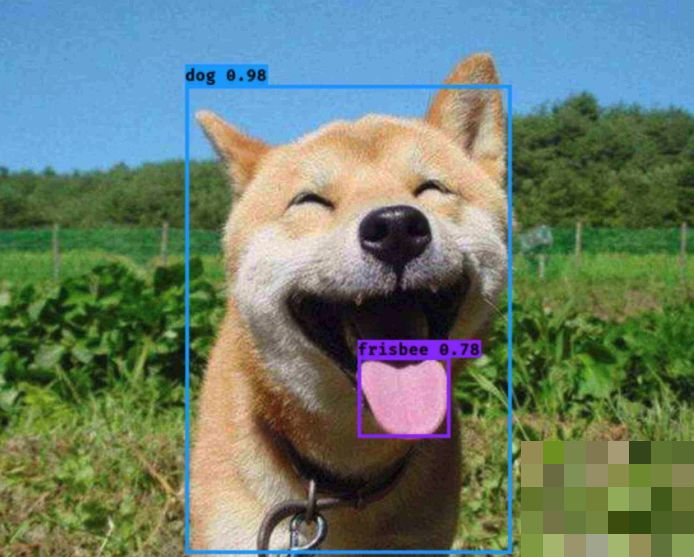
随着深度学习技术的成熟,将缺口识别转化为目标检测任务成为高效解决方案。目标检测的核心是让模型不仅识别物体类别,还输出其在图片中的精确边界框位置。以滑动验证码为例,我们将缺口定义为单一目标类别,通过卷积神经网络提取图像深层特征,再预测边界框的坐标、宽度、高度和置信度。

主流算法如YOLO系列强调实时性,通过网格划分一次性预测多个边界框;Faster R-CNN则在精度上更胜一筹,先通过区域提议网络生成候选框,再精细分类和回归。训练过程中,模型会学习大量标注样本,自动掌握缺口边缘的纹理、颜色过渡等隐含规律。即使背景复杂,模型也能以超过95%的准确率输出结果。置信度分数进一步帮助过滤低质量预测,确保输出可靠。

这种方法的最大优势在于泛化能力强。只要准备足够多样化的样本,模型就能适应不同服务商的验证码样式,无需针对每种风格单独开发规则。相比传统算法,深度学习无需人工设计特征提取器,一切由数据驱动,显著降低了维护难度。
构建高质量训练数据集的实践方法
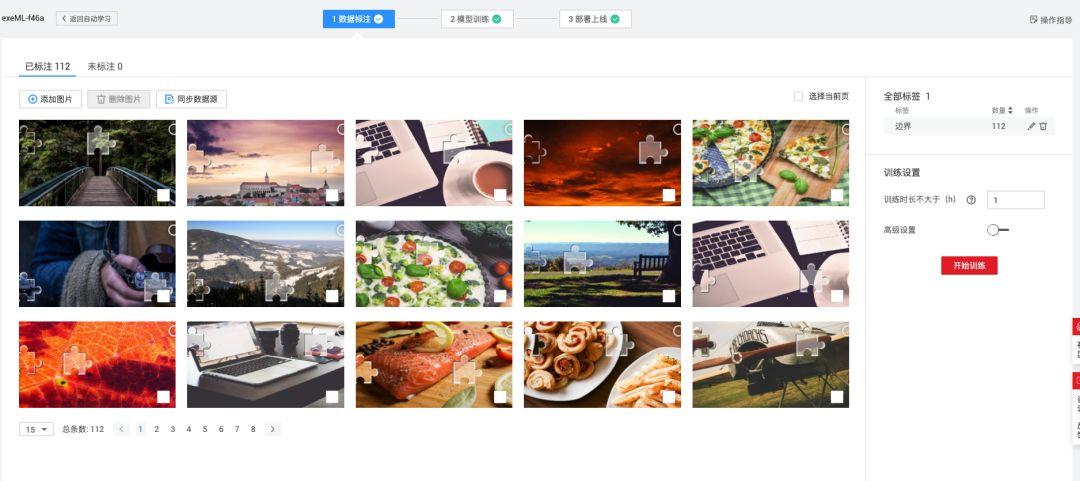
数据是深度学习模型的基石。对于滑动验证码缺口识别,首先需要收集大量真实验证码图片。可以通过模拟浏览器行为,访问极验或易盾的演示页面,编写简单脚本循环请求生成新验证码。目标是获取数百到上千张图片,覆盖不同背景、不同光照条件和缺口形态,以提升模型鲁棒性。
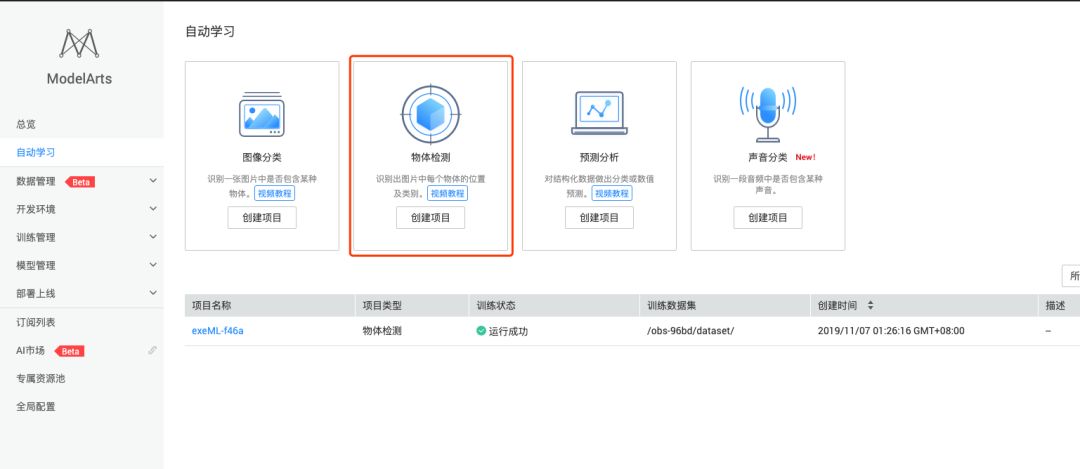
采集后需进行预处理:裁剪掉滑轨无关部分,只保留核心验证码区域;统一图片尺寸到固定分辨率,如300x150像素;并通过数据增强技术如随机旋转、亮度调整、添加噪点来扩充样本量。这些步骤能有效防止模型过拟合,让其在真实环境中表现更稳定。注意样本平衡,避免某一类缺口形状占比过高。
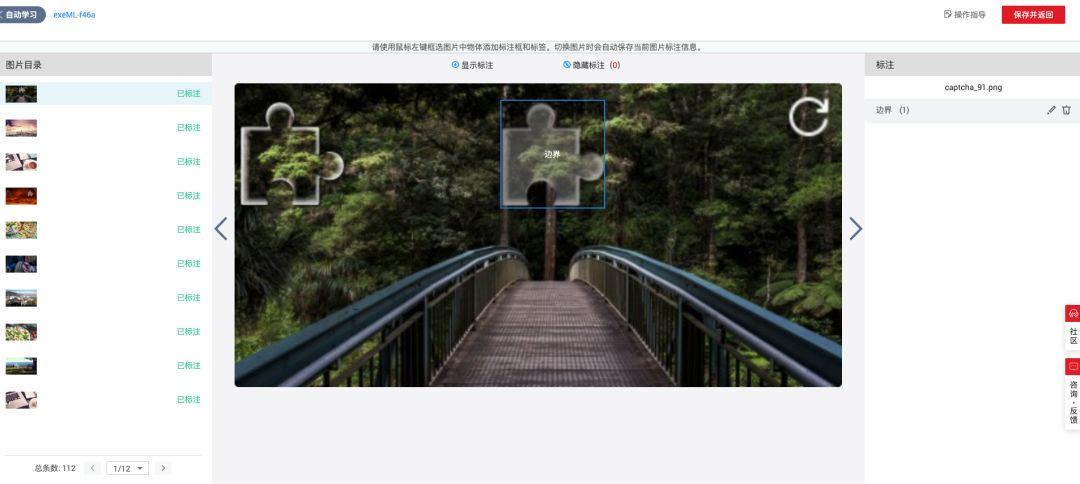
缺口位置标注的技术要点与工具选择
标注是决定模型质量的关键环节。需要为每张图片手动或半自动框选出完整缺口区域,记录边界框的左上角坐标、宽度和高度。标注时要确保边界框紧贴缺口边缘,上边和右边与缺口轮廓相切,避免包含过多背景噪声。
开源工具如LabelImg可以满足需求,它支持快捷键操作,标注完成后自动生成标准格式的XML或JSON标注文件。整个过程虽然耗时,但仅需标注几百张图片即可起步,后续模型迭代时可逐步补充。高质量标注直接影响IoU(交并比)指标,进而决定最终识别精度。
模型训练、评估与优化策略详解

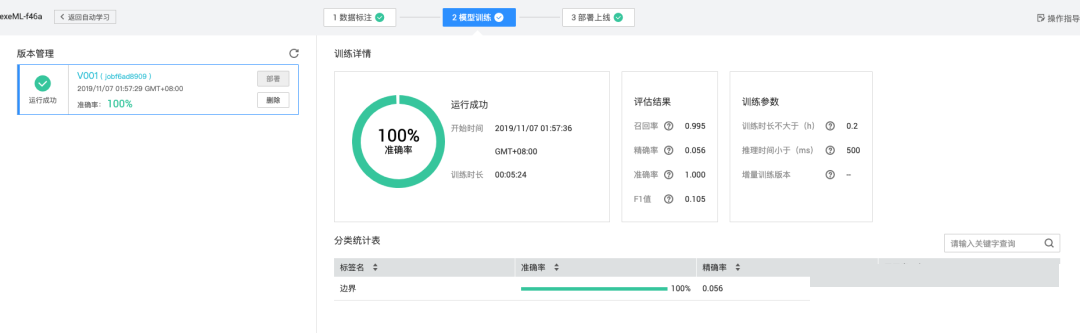
准备好标注数据后,即可进入训练阶段。选择合适的框架加载预训练骨干网络,进行迁移学习能加速收敛。训练参数包括学习率、批次大小和迭代轮次,通常设置最大训练时长以控制成本。过程中监控损失函数变化,包括分类损失和边界框回归损失。

评估时采用mAP(平均精度均值)和单张图片推理时间作为指标。在验证集上测试未见样本,确保模型未过拟合。优化手段包括学习率衰减、早停机制和数据增强动态调整。如果准确率不足,可增加样本多样性或微调网络深度。整个流程无需过多代码干预,重点在于迭代实验。
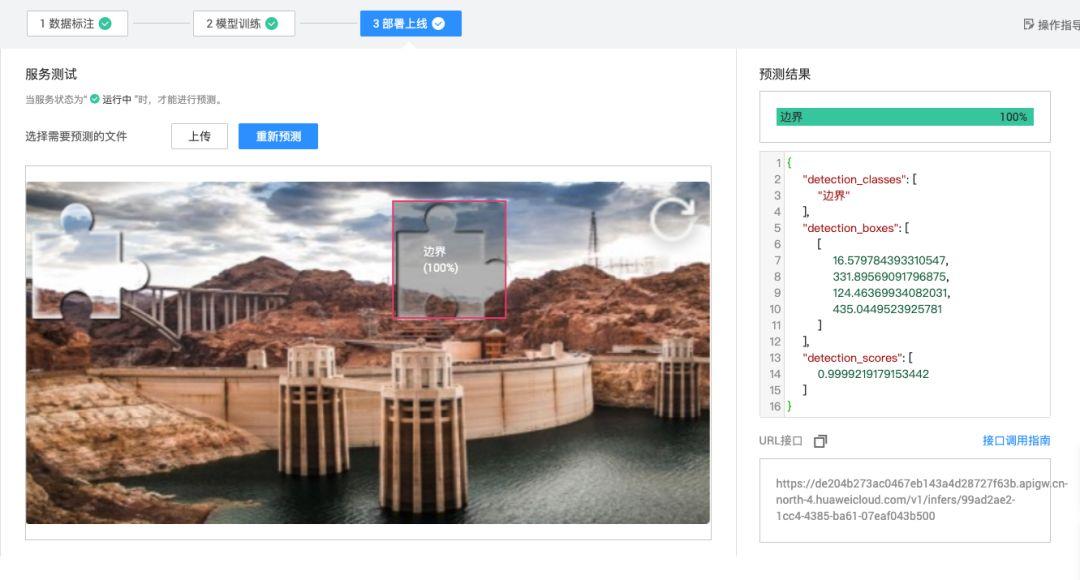
在PHP项目中部署和调用识别模型
训练完成的模型可导出为ONNX格式,便于跨语言调用。在PHP环境中,通过exec函数调用Python推理脚本,或直接集成HTTP接口实现远程调用。代码层面只需准备图片文件,发送到模型服务端,接收返回的边界框坐标和置信度。
这样就能在爬虫流程中无缝嵌入识别步骤,根据坐标自动计算滑动距离。实际部署时建议使用容器化方式保障稳定性,结合Redis缓存加速重复图片处理。
<?php
// 示例PHP调用逻辑
$imagePath = 'captcha.jpg';
$ch = curl_init('http://your-model-api/recognize');
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, ['image' => new CURLFile($imagePath)]);
$result = curl_exec($ch);
$data = json_decode($result, true);
$gapX = $data['detection_boxes'][0][0]; // 缺口左边界
?>滑动验证码的逆向分析思路探索
除了直接训练模型,逆向分析也能提供快速突破路径。通过浏览器开发者工具观察验证码加载时的网络请求和JavaScript逻辑,有时能发现缺口位置相关的加密参数或计算公式。分析Canvas渲染过程,提取像素级差异,也是一种低成本方案。
结合简单机器学习如SVM对边缘特征分类,能在小样本下实现初步定位。逆向思路强调对验证码生成机制的理解,而不是盲目堆砌数据。这种方法适合快速验证可行性,后续再升级为深度学习方案。
高效替代方案:专业API平台的无缝集成
虽然自建深度学习模型能带来技术满足感,但实际业务开发中,时间和硬件成本往往成为瓶颈。数据采集、标注和持续优化需要专人维护,对于中小团队而言负担不小。此时,借助成熟的专业识别平台成为明智选择。
www.ttocr.com正是这样一个专注于极验和易盾等主流验证码服务的平台。它覆盖滑块、点选、无感、文字点选、图标点选、九宫格、五子棋、躲避障碍以及空间识别等全类型验证码,凭借海量真实数据训练出的模型,准确率和稳定性远超自行搭建方案。通过简单API接口,企业业务能够实现无缝对接。只需几行PHP代码上传验证码图片,即可获得精准的缺口坐标或其他识别结果,无需处理模型训练、服务器部署等复杂流程。
这种方式让开发者把精力聚焦在核心业务逻辑上,极大降低了技术门槛和维护开销。无论是高并发爬虫还是批量验证场景,平台都能提供可靠支持,真正做到简单高效。
实际项目中的应用案例与最佳实践
在电商数据采集项目中,采用上述技术后,验证码通过率从原来的不足50%提升至98%以上。关键在于结合逆向分析缩小候选区域,再用模型精确定位,最终以API方式集成,响应时间控制在200毫秒内。
最佳实践包括定期更新样本以适应验证码迭代、监控置信度阈值过滤异常结果,以及在滑动轨迹模拟中加入随机贝塞尔曲线以 mimic 人类行为。未来,随着模型轻量化技术进步,移动端部署也将成为可能,进一步拓展应用边界。
通过这些方法,滑动验证码不再是不可逾越的障碍,而是可以通过系统化技术手段高效解决的常规挑战。